
2026-02-28 计算机网络笔记
- 教材:<<计算机网络-自顶向下方法>>
- (3/20): 不得不承认是一本神书,尽管部分地方所作的假设与计算过于枯燥和无用,但整本书还是很有体系足够全面的
- (4/3): 主干概念都讲的很明白,但边缘概念很多都讲的不明不白,不如不讲
应用层
应用层协议
http协议(2026/1/28)
事实上我把之前博客里写的内容直接搬过来了,比书上还是要详细不少的
概览
HTTP 是一个客户端—服务器协议:请求由一个实体,即用户代理(user agent),或是一个可以代表它的代理方(proxy)发出。大多数情况下,这个用户代理都是一个 Web 浏览器,不过它也可能是任何东西,比如一个爬取网页来充实、维护搜索引擎索引的机器爬虫。
每个请求都会被发送到一个服务器,它会处理这个请求并提供一个称作响应的回复。在客户端与服务器之间,还有许许多多的被称为代理的实体,履行不同的作用,例如充当网关或缓存。
客户端发送的请求
1 | POST /api/v1/user/update?id=1024 |
POST: 客户端发起的请求所用方法
/api/v1/user/update?id=1024:服务器对应资源的路径和Query参数
Host: 目标服务器域名
Content-Type: 传输数据格式声明
User-Agent: 使用的浏览器代理
Authorization: cookie或token等身份识别头
Content-Length: 请求体字节长度
{"nickname": "Apollo","gender": "male"}: 传输数据
服务端返回的报文
1 | HTTP/1.1 200 OK |
METHOD
HTTP/1.1 协议中共定义了八种方法来以不同方式操作指定的资源,下面我列举常用的几种
GET
The request is for a representation of a resource.The server should only retrieve data; not modify state.
HEAD
The request is like a GET except that the response should not include the representation data in the body.
HEAD = GET − Response Body
POST
The request is to process a resource in some way.
PUT
The request is to create or update a resource with the state in the request.
DELETE
The request is to delete a resource.
status code
In HTTP, you send a numeric status code of 3 digits as part of the response.
These status codes have a name associated to recognize them, but the important part is the number.
In short:
100 - 199 are for “Information”. You rarely use them directly. Responses with these status codes cannot have a body.
200 - 299 are for “Successful” responses. These are the ones you would use the most.
200 is the default status code, which means everything was “OK”.
Another example would be 201, “Created”. It is commonly used after creating a new record in the database.
A special case is 204, “No Content”. This response is used when there is no content to return to the client, and so the response must not have a body.
300 - 399 are for “Redirection”. Responses with these status codes may or may not have a body, except for 304, “Not Modified”, which must not have one.
400 - 499 are for “Client error” responses. These are the second type you would probably use the most.
An example is 404, for a “Not Found” response.
For generic errors from the client, you can just use 400.
500 - 599 are for server errors. You almost never use them directly. When something goes wrong at some part in your application code, or server, it will automatically return one of these status codes.
User Agent
wiki:用户代理(英语:user agent)在计算机科学中指的是代表用户行为的程序(软件代理程序)。例如,网页浏览器就是一个“帮助用户获取、渲染网页内容并与之交互”的用户代理
简单说,user agent是http header里的客户端标识,告诉目标服务器自己是通过哪个浏览器进行访问的
- 爬虫总是需要伪装自己是通过某个代理访问服务器的,否则容易被拦截
标准形式:
1 | User-Agent: <product> / <product-version> <comment> |
web浏览器的通用格式:
1 | User-Agent: Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions> |
示例:
1 | Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36 |
Proxy(2/4)
In computer networking, a proxy server is a server application that acts as an intermediary between a client requesting a resource and the server then providing that resource.[1]
Forward proxy vs. reverse proxy
A forward proxy is a server that routes traffic between clients and another system, which is, in most cases, external to the network. This means it can regulate traffic according to preset policies, convert and mask client IP addresses, enforce security protocols, and block unknown traffic. A forward proxy enhances security and policy enforcement within an internal network.A reverse proxy, instead of protecting the client, is used to protect the servers. A reverse proxy accepts a request from a client, forwards that request to another one of many other servers, and then returns the results from the server that specifically processed the request to the client. Effectively, a reverse proxy acts as a gateway between clients, users, and application servers and handles all the traffic routing whilst also protecting the identity of the server that physically processes the request.
eg
家庭网络中的路由器就同时扮演了正向代理和反向代理两个角色
cookie
MDN
服务器收到 HTTP 请求后,服务器可以在响应标头里面添加一个或多个 Set-Cookie 选项。浏览器收到响应后通常会保存下 Cookie,并将其放在 HTTP Cookie 标头内,向同一服务器发出请求时一起发送。你可以指定一个过期日期或者时间段之后,不能发送 cookie。你也可以对指定的域和路径设置额外的限制,以限制 cookie 发送的位置
Web cache
- Web缓存是用于临时存储(缓存)Web文档(如HTML页面和图像),以减少服务器延迟的一种信息技术。Web缓存系统会保存下通过这套系统的文档的副本;如果满足某些条件,则可以由缓存满足后续请求
流程如下:
-
浏览器建立 TCP 连接 到 Web Cache,发送 HTTP 请求获取某个对象。
-
Web Cache 查询本地缓存。
- 若存在对象副本(cache hit),直接返回 HTTP 响应给浏览器。
-
若本地没有该对象(cache miss),Web Cache 建立 TCP 连接 到 Origin Server。
-
Web Cache 通过该 TCP 连接向 Origin Server 发送 HTTP 请求。
-
Origin Server 返回包含对象的 HTTP 响应。
-
Web Cache 接收响应后:
- 在本地缓存该对象副本
- 通过已有的 浏览器 ↔ Web Cache TCP 连接 将 HTTP 响应返回给浏览器。
- 这样看的话,cache和proxy的作用有大半是重叠的,因此一个代理服务器或者代理客户端通常身兼cache和proxy的角色
从HTTP/1到HTTP/3
HTTP1采用非持续连接,每个HTTP请求都使用独立的TCP连接,可想而知慢的吓人
因此,HTTP1.1采用了并行的TCP持续连接,共享带宽,但这会增加连接占用的带宽,容易引发网络阻塞
这也是HTTP2推出的原因,只使用一个TCP持续连接来处理多个并行请求,将每个HTTP报文划分为帧单位,在第一个请求发送第一帧后,发送第二个请求的第一帧,以此类推,不断循环
至于HTTP3,改进的程度比较有限,且基于UDP而非TCP连接,在22年已经标准化
SMTP协议(3/4)
SMTP,一种广泛使用,十分古老的邮件传输协议,与HTTP一样使用的是持续的TCP连接
流程如下:
-
Alice 在 用户代理(Mail User Agent) 中输入 Bob 的邮箱地址(如
bob@someschool.edu),编写邮件并发送。 -
用户代理将邮件发送到 Alice 的邮件服务器(Mail Server),邮件进入服务器的 邮件队列(message queue)。
-
Alice 邮件服务器上的 SMTP 客户端 从队列中发现该邮件,并建立 TCP 连接 到 Bob 的邮件服务器上的 SMTP 服务器。
-
完成 SMTP 握手 后,SMTP 客户端通过该 TCP 连接发送邮件内容。
-
Bob 的邮件服务器上的 SMTP 服务器 接收邮件,并将邮件存入 Bob 的邮箱(mailbox)。
-
Bob 在需要时启动 用户代理,从邮箱中读取邮件。
DNS
识别主机有两种方式———主机名(hostname)和 IP 地址。人们喜欢便于记忆的主机名标识方式,而路由器则喜欢定长的、有着层次结构的 IP 地址,因为hostname(如www.baidu.com)不能给路由器任何有关这个主机所在位置的信息
因此,我们需要一种能够将主机名转换成IP地址的服务,也就是 域名系统( Domain Name System , DNS ),由DNS服务器和DNS协议构成,运行在UDP之上,故也是应用层协议
常用查询方法
-
A 记录查询 (Address Record)
- 物理定义:将域名直接映射到一个具体的 IPv4 地址。
- 工作机制:当发起 A 记录查询时,DNS 服务器会返回一个由 4 组数字组成的物理地址(如
192.168.1.1)。 - 特性:它是最基础、速度最快的解析方式。浏览器拿到 A 记录后,可以直接根据该 IP 地址物理寻找目标服务器并建立 TCP 连接。
-
CNAME 记录查询 (Canonical Name Record)
- 物理定义:将一个域名指向另一个域名,而不是具体的 IP 地址。
- 工作机制:
- 客户端查询
www.example.com。 - DNS 返回一个 CNAME 记录(如
example.cdn.com)。 - 客户端必须针对这个新域名再次发起 DNS 查询,直到最终获得一个 A 记录(IP 地址)。
- 客户端查询
- 特性:
- 别名逻辑:常用于 CDN 加速或云服务。当后端物理服务器 IP 变动时,只需更改最终域名的 A 记录,所有指向它的 CNAME 无需修改。
- 性能成本:相比 A 记录,CNAME 至少会增加一轮 DNS 查询的物理往返时间。
为什么DNS用UDP
我们可以简单总结一下 DNS 的发展史,1987 年的 RFC1034 和 RFC1035 定义了最初版本的 DNS 协议,刚被设计出来的 DNS 就会同时使用 UDP 和 TCP 协议,对于绝大多数的 DNS 查询来说都会使用 UDP 数据报进行传输,TCP 协议只会在区域传输的场景中使用,其中 UDP 数据包只会传输最大 512 字节的数据,多余的会被截断;两年后发布的 RFC1123 预测了 DNS 记录中存储的数据会越来越多,同时也第一次显式的指出了发现 UDP 包被截断时应该通过 TCP 协议重试
实际应用举例
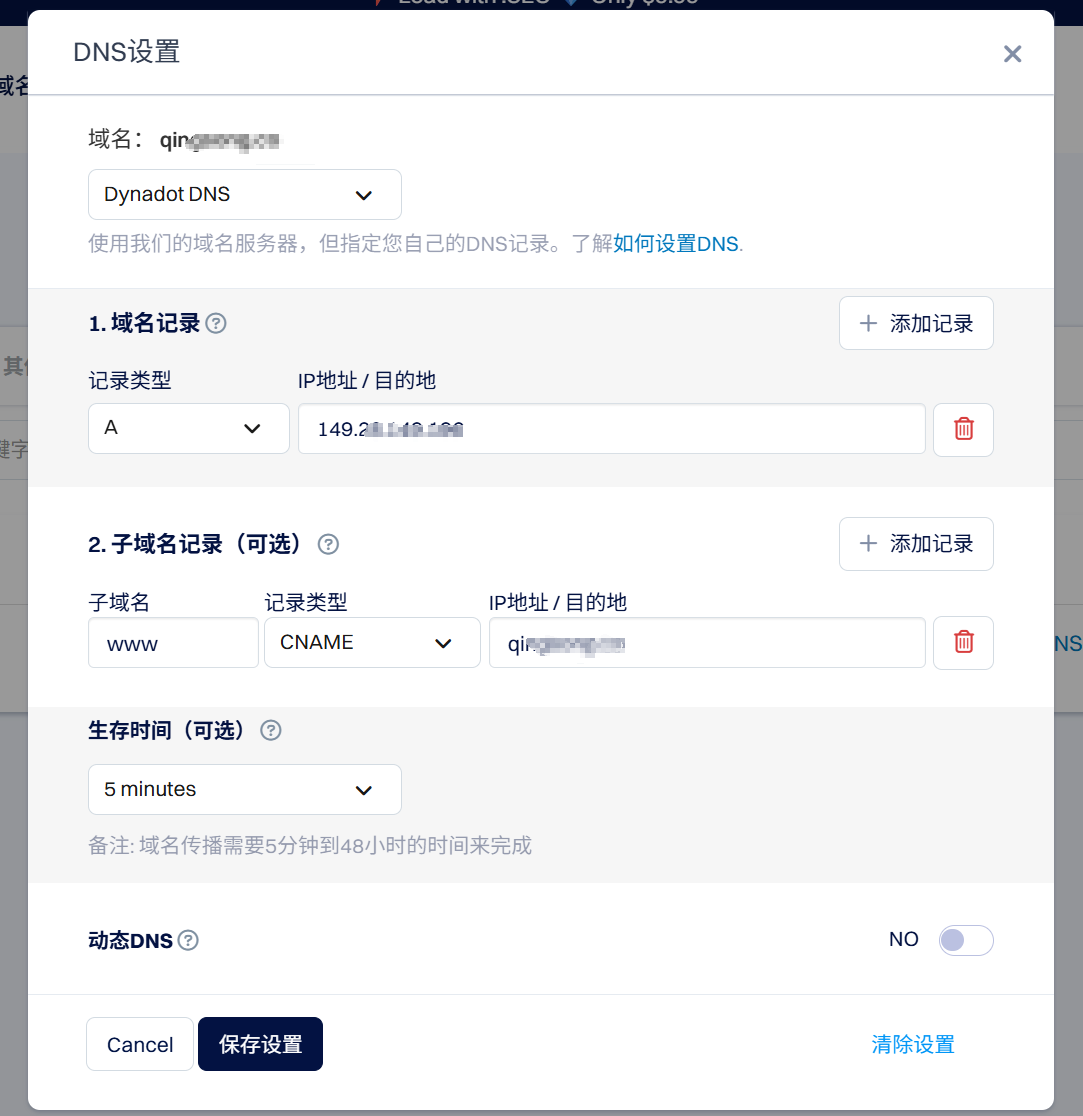
来看这样一个图,这是我在服务器上部署好了网站后,并在dynadot购买域名进入后台时将服务器的IP地址与对应域名绑定的过程.
使用A记录时,只要将服务器的ip地址填入就可以生效,但是别人访问这个服务器的时候只能在地址栏输入类似qin*********.com的内容来访问.
但一般情况下,用户可能会输入www.qin******.com来访问这个服务器,但DNS并不会自动帮我将www前缀删除,所以我需要增加一条CNAME记录,将www.qin******.com指向qin*********.com.
- www前缀代表着这个网站使用的是http协议,是一个web网站,但由于现在基本都是web网站,少有类似
ftp.qin*****.com这样的网站名了
P2P协议
BitTorrent是里面最为著名的代表,简单来说是一种多人之间互相传数据分包的协议,从而避免多人仅通过连接一台服务器导致的下载速度延缓.
磁力链接,torrent等资源链接都采用这一协议进行传输
DASH和CDN
DASH(Dynamic Adaptive Streaming over HTTP),将视频编码为不同清晰度的版本,根据用户的可用带宽来动态选择对应画质版本的视频
CDN(Content Distribution Network),由名字可以看出来,CDN相当于一个存储视频,文档等数据的分布式服务器,避免只用一个服务器来接受http请求导致的各种问题
socket(3/5)
socket原本的意思是插座,可以理解为只有通过socket,应用层的软件才能联网
Port(端口)
可以理解为通信接口,也就是说,应用层的进程通过特定的端口实现与运输层TCP/UDP的连接.
- 一个端口号使用16位无符号整数(unsigned integer)来表示,其范围介于0与65535之间
- 在TCP协议中,端口号0是被保留的,不可使用。1–1023 系统保留,只能由root用户使用。1024–4999 由客户端程序自由分配。5000–65535 由服务器端程序自由分配。在UDP协议中,来源端口号可选择是否填上,如果设为0,则代表无来源端口号。
实际上硬件里不存在Port,而是一个虚拟的socket绑定对象,socket依靠每个进程设定独特的Port与运输层交互
运输层
- remind: RTT = Round-Trip Time(往返时延)
Reliable Data Transfer Protocol (RDT)
- 显然书上这部分的引入太长了,而且并没有作者自以为的讲得很详细很清晰,还是让AI来总结一下吧
可靠数据传输协议(Reliable Data Transfer Protocol,RDT)是计算机网络中用来保证发送方的数据能够完整、正确、按顺序送达接收方的一类协议。即使底层信道可能存在丢包、乱序或传输错误,RDT 也能通过设计机制让数据安全传输
1. RDT 的核心问题
在现实网络中,直接发送比特流存在很多潜在问题:
- 丢包:数据包在传输中可能完全丢失。
- 数据错误:信道噪声或硬件故障可能导致比特翻转,接收方收到的数据与发送方发送的数据不同。
- 重复数据:网络重传机制或路由问题可能导致同一个数据包被接收多次。
- 乱序:数据包可能通过不同路径传输,先发送的包晚到达。
可靠数据传输协议需要解决这些问题,保证端到端的可靠性。
2. 核心机制概览
RDT 的核心机制可以概括为五个部分:
-
分包(Segmentation)
-
将大数据拆分成较小的数据包,每个包称为 segment。
-
优点:小包更容易重传,减少重发的代价,同时便于序列号管理。
-
每个包通常包含以下内容:
- 数据内容(payload)
- 序列号(Sequence Number)
- 校验和(Checksum)
-
-
错误检测(Error Detection)
-
利用 Checksum 或 CRC(Cyclic Redundancy Check) 检测数据在传输中是否被破坏。
-
发送方:计算数据包的校验和并附加在包头。
-
接收方:收到包后重新计算校验值,如果与包头的值相同,则认为数据正确,否则认为数据出错。
-
示例:
1
2数据内容: 10110011
校验和: 0110接收方校验,如果不匹配,就触发重传。
-
-
序列号(Sequence Number)
-
每个数据包被赋予唯一的序列号(Sequence Number),用于:
- 防止重复包处理
- 保证接收顺序
-
序列号通常为 0、1 或更大的整数,循环使用。
-
接收方通过序列号判断是否收到新的包还是重复包。
-
-
确认机制(Acknowledgment, ACK / Negative Acknowledgment, NAK)
-
ACK(确认):接收方收到正确的数据包后发送 ACK 给发送方。
-
NAK(否定确认):接收方收到错误数据包时发送 NAK,要求发送方重发。
-
作用:
- 让发送方知道哪些数据包成功到达。
- 在丢包或错误情况下触发重传。
-
示例流程:
1
2发送方 -> 数据包 1 -> 接收方
接收方 -> ACK 1 -> 发送方
-
-
重传机制(Timeout & Retransmission)
-
发送方设置 超时时间(Timeout)。
-
如果在超时时间内没有收到 ACK,发送方会自动 重发数据包。
-
与 ACK/NAK 配合,可以保证即使网络丢包,最终数据仍然完整送达。
-
关键点:
- 超时必须合理,否则可能导致过早重发或等待过久。
- 与序列号结合,保证重发的数据仍能正确排序,不被重复处理。
-
3. 可靠数据传输模型示例
3.1 Stop-and-Wait RDT(最基础模型)
-
发送端:
- 发送一个数据包,附带序列号。
- 等待接收方发送 ACK。
- 如果超时未收到 ACK,重发数据包。
- 收到 ACK 后发送下一个包。
-
接收端:
- 收到数据包,检查校验和。
- 如果正确,处理数据并发送 ACK。
- 如果错误或重复,丢弃数据或发送 NAK。
-
优点:简单易实现,理解方便。
-
缺点:效率低,因为发送方在等待 ACK 期间 无法发送下一个数据包。
3.2 Sliding Window RDT(滑动窗口机制,流水线机制)
-
改进 Stop-and-Wait,允许 发送方在等待 ACK 的同时发送多个包。
-
核心概念:
- 发送窗口:发送方未确认的数据包集合。
- 接收窗口:接收方能够接收的序列号范围。
-
优点:提高链路利用率,尤其是高延迟链路。
-
实现机制:
- 发送方维护一个窗口,窗口内的包可以连续发送。
- 接收方按序号接收,并发送 ACK。
- 窗口滑动:收到 ACK 后,发送方窗口向前滑动,可以发送新的包。
-
常见变种:
- Go-Back-N:出错时从错误包开始重发之后所有包。
- Selective Repeat:只重发出错的包,更高效。
4. RDT 的工作流程总结
以最简单的 Stop-and-Wait 为例,端到端流程如下:
1 | 发送方: [数据包 seq=0] --------> |
异常情况:
-
数据包丢失:
- 发送方超时重发。
-
数据包出错:
- 接收方丢弃包并发送 NAK 或不发送 ACK。
-
ACK 丢失:
- 发送方超时重发数据包,接收方根据序列号判断重复,避免重复处理。
核心思想:发送方持续重发,接收方持续确认,直到每个包安全到达。
5. 小结
可靠数据传输协议(RDT)通过以下机制保证数据完整、顺序正确、无重复:
- 分包(Segmentation):大数据拆成小包,便于传输和重发。
- 错误检测(Checksum / CRC):保证数据正确。
- 序列号(Sequence Number):防止重复,保证顺序。
- 确认机制(ACK / NAK):接收方反馈接收情况。
- 重传机制(Timeout & Retransmission):丢包或错误时自动重发。
总结一句话:RDT 是一种“问答 + 重试”的机制,发送方不断发送数据并等待确认,接收方检查数据并反馈状态,通过循环直到每个包安全送达。
TCP/UDP(3/7)
UDP(User Datagram Protocol)
UDP的原理非常简单,就是将src post传输的数据 打包进UDP报文,并传递给网络层,再分发给dst post
- 使用 UDP 时,在发送报文段之前,发送方和接收方的运输层实体之间没有握手.正因为如此,UDP 被称为无连接的.
Why use UDP
- 无连接状态。TCP 需要在端系统中维护连接状态。此连接状态包括接收和发送缓存、拥塞控制参数以及序号与确认号的参数。另一方面, UDP 不维护连接状态 , 也不跟踪这些参数。 因此, 当应用程序运行在 UDP 之上而不是运行在 TCP 上时,某些专门用于某种特定应用的服务器一般都能支持更多的活跃客户。
- 分组首部开销小 。每个 TCP 报文段都有 20 字节的首部开销 , 而 UDP 仅有 8 字节的开销。
- TCP 的拥塞控制会导致如因特网电话、视频会议之类的实时应用性能变得很差 。由于这些原因,多媒体应用开发人员通常将这些应用运行在 UDP 之上而不是 TCP 之上
UDP包分析
一个完整的 UDP 包由 UDP 头部 + 数据负载(Payload)组成
UDP头部(固定8字节)
| 字段 | 字节数 | 说明 |
|---|---|---|
| Source Port | 2 | 源端口 |
| Destination Port | 2 | 目标端口 |
| Length | 2 | UDP 头 + 数据总长度 |
| Checksum | 2 | 校验和,验证头部和数据是否损坏 |
1 | 0 15 16 31 |
UDP 数据负载(Payload)
- 长度 = UDP Length – 8(头部大小)
- 完全由应用程序生成
UDP检验和
检验和用于确定当 UDP 报文段从源到达目的地移动时,其中的比特是否发生了改变 ( 例如,由于链路中的噪声干扰或者存储在路由器中时引入问题 )。发送方的 UDP 对报文段中的所有 16 比特字的和进行反码运算,求和时遇到的任何溢出都被回卷(把最高位进位送入最低位相加) 。 得到的结果被放在 UDP 报文段中的检验和字段.
显然接收方可以再进行一次求和与反码相加,如果出现了0就说明数据有地方出错了.
TCP(Transmission Control Protocol)
TCP 被称为是面向连接的 ( connection-oriented),这是因为在一个应用进程可以开始向另一个应用进程发送数据之前 , 这两个进程必须先相互 “ 握手 ”,即它们必须相互发送某些预备报文段,以建立确保数据传输的参数
TCP报文段分析
一个完整的 TCP 报文段由 **TCP头部(Header)+ 选项(Options,可选)+ 数据负载(Payload)**组成,其中最小 TCP 头部固定 20 字节。
TCP头部(最小20字节)
| 字段 | 字节数 | 说明 |
|---|---|---|
| Source Port | 2 | 源端口,标识发送应用进程 |
| Destination Port | 2 | 目标端口,标识接收应用进程 |
| Sequence Number | 4 | 序列号,标识第一个数据字节编号 |
| Acknowledgment Number | 4 | 确认号,期望收到的下一个字节编号(ACK置1有效) |
| Data Offset | 4位 | TCP头部长度(单位:32位字/4字节) |
| Reserved | 3位 | 保留,必须置0 |
| Flags(控制位) | 9位 | URG, ACK, PSH, RST, SYN, FIN 等 |
| Window Size | 2 | 接收端可接收缓冲区大小(流量控制) |
| Checksum | 2 | TCP头+数据+伪首部校验和 |
| Urgent Pointer | 2 | 紧急指针,URG置1时有效 |
TCP头部字段示意图
1 | 0 15 16 31 |
-
Flags(控制位):
- URG:紧急指针有效
- ACK:确认号有效
- PSH:接收端应用立即读取数据
- RST:重置连接
- SYN:同步序列号,用于建立连接
- FIN:关闭连接
-
数据偏移(Data Offset):
- 表示 TCP 头部长度,单位4字节
- 最小值 5(20字节),最大 15(60字节,包括选项)
-
窗口大小用于流量控制,控制发送端发送未确认的数据量。
-
校验和覆盖 TCP 头部、数据以及伪首部(IP源/目的地址、协议号、TCP长度)。
序号和确认号
报文段的序号 ( sequence number for a segment ) 是该报文段首字节的字节流编号
举例来说 ,假设主机 A 上的一个进程想通过一条 TCP 连接向主机 B 上的一个进程发送一个数据流 。主机 A 中的 TCP 将隐式地对数据流中的每一个字节编号 。假定数据流由一个包含 500 000 字节的文件组成,其 MSS 为 1000 字节,数据流的首字节编号是 0。则该 TCP 将为该数据流构建 500 个报文段。给第一个报文段分配序号 0 ,第二个报文段分配序号 1000 ,第三个报文段分配序号 2000,以此类推。每一个序号被填入到相应TCP报文段首部的序号字段中。
至于确认号,首先我们需要明确为什么需要确认号这样一个东西,由于TCP连接是双向的,故发送方也需要收到接收方传来的信息,故需要在确认号字段里填写缺失的来自接收方传来的包序号
假设主机 A 已收到一个来自主机 B 的包含字节 0 ~ 535 的报文段,以及另一个包含字节 900 ~ 1000 的报文段。 由于某种原因, 主机 A 还没有收到字节 536 ~ 899 的报文段。 在这个例子中, 主机 A 为了重新构建主机 B 的数据流,仍在等待字节 536 ( 和其后的字节)。 因此 , A 到 B 的下一个报文段将在确认号字段中包含 536
TCP连接的建立(三次握手)
- 第一步:SYN 报文段
客户端向服务器发送一个首部 SYN 比特置为 1 的特殊报文段。该报文不含应用层数据,但包含客户端随机选择的初始序号 client_isn。该报文段被封装在 IP 数据报中发送。 - 第二步:SYNACK 报文段
服务器接收到 SYN 后,为连接分配 TCP 缓存和变量,并回送允许连接的报文段。此时 SYN 比特置为 1,确认号字段设为 client_isn + 1,同时服务器选择自己的初始序号 server_isn。此报文段表明服务器同意建立连接。 - 第三步:ACK 报文段
客户端收到 SYNACK 后,也为连接分配缓存和变量,并向服务器发送最后的确认报文。此时 SYN 比特置为 0,确认号字段设为 server_isn + 1。该阶段的报文段负载可以开始携带实际的客户数据。
- 注意,第三步的时候客户端可以主动选择终止连接
拓展:为什么要三次握手
想象一下这个场景,如果通信双方的通信次数只有两次,那么发送方一旦发出建立连接的请求之后它就没有办法撤回这一次请求,如果在网络状况复杂或者较差的网络中,发送方连续发送多次建立连接的请求,如果 TCP 建立连接只能通信两次,那么接收方只能选择接受或者拒绝发送方发起的请求,它并不清楚这一次请求是不是由于网络拥堵而早早过期的连接。使用三次握手和 RST 控制消息将是否建立连接的最终控制权交给了发送方,因为只有发送方有足够的上下文来判断当前连接是否是错误的或者过期的,这也是 TCP 使用三次握手建立连接的最主要原因。
TCP连接的终止(四次挥手)
终止发起方的对等性
TCP 协议是对称的全双工协议,连接的任何一方(无论最初是客户端还是服务器)都可以主动调用 close() 发送 FIN 报文段来开启连接终止流程。在协议规范(RFC 793/RFC 9293)中,通常将发起关闭的一方称为 Active Closer(主动关闭方),将接收关闭请求的一方称为 Passive Closer(被动关闭方)。
主动关闭与被动关闭的逻辑演进
- 主动方 (Active Closer) 发送 FIN
该方应用进程决定不再发送数据。TCP 实体构造首部 FIN 位为 1 的报文段。发送后,主动方进入 FIN-WAIT-1 状态。 - 被动方 (Passive Closer) 确认 ACK
被动方收到 FIN 后,由 TCP 协议栈自动回送 ACK。此时被动方进入 CLOSE-WAIT 状态,并通知上层应用进程对端已关闭。主动方收到 ACK 后进入 FIN-WAIT-2。 - 被动方 (Passive Closer) 发送 FIN
当被动方的应用进程处理完所有剩余数据后,显式关闭套接字。TCP 发送 FIN 位为 1 的报文段,被动方进入 LAST-ACK 状态。 - 主动方 (Active Closer) 发送最终 ACK
主动方收到对端的 FIN 后,发送最后一个 ACK,进入 TIME-WAIT 状态。被动方收到此 ACK 后直接进入 CLOSED 状态,释放所有资源。 - 主动方的资源释放延迟
主动方必须在 TIME-WAIT 状态维持 2MSL 时长,以确保最后一个 ACK 到达被动方,并清空网络中残存的旧报文段。倒计时结束后,主动方进入 CLOSED 并释放资源。
拥塞控制原理(3/11)
由于实际应用中网络层总是不能实现具有无限容量的,无数据丢失的信道,故当数据传输量很大时信道很容易发生拥塞,故需要运输层使用拥塞控制方法来尽可能减小拥塞的可能.
在最为宽泛的级别上,我们可根据网络层是否为运输层拥塞控制提供了显式帮助,来区分拥塞控制方法。
端到端拥塞控制
在端到端拥塞控制方法中,网络层 没有 为运输层拥塞控制提供 显式支持。即使网络中存在拥塞,端系统也必须通过对网络行为的观察 ( 如分组丢失与时延) 来推断之
网络辅助的拥塞控制
路由器会向发送方提供关于网络中拥塞状态的显式反馈信息
TCP拥塞控制(待补充)
网络层(3/12)
Overview
网络层用一句话来表示就是: 通过多个路由器将数据从服务端移动到客户端.为此,网络层需要具备以下两种功能:
- 转发: 当数据输入时,路由器需要将数据移动到适当的输出端口
- 路由选择: 网络层需要解决数据从服务端传输到客户端所采用的路径,相当于规划好了具体要用到的转发路由器
- 注意这里的端口是指物理的输入输出接口,与虚拟的软件端口不是一个概念.
这样来看的话,网络层便可以分为负责转发功能的数据平面和负责路由选择功能的控制平面.
数据平面
路由器工作原理
路由器有四个组件:
- 输入端口
- 交换结构: 将路由器的输入端口连接到输出端口
- 输出端口
- 路由选择处理器: 主要作用于交换结构
输入端口处理和基于目的地转发
输入端口可以通过转发表和嵌入式的搜索算法来查找传入的ip地址对应的输出端口,故可以在本地实现转发决策,而无需调用路由选择处理器.
交换方法
经内存交换
早期的路由器是传统的计算机,端口之间的交换.一个分组到达一个输入端口时,该端口会先通过中断方式向路由选择处理器发出信号。于是 ,该分组从输入端口处被复制到处理器内存中。路由选择处理器则从其首部提取目的地址,在转发表中查找适当的输出端口,并将该分组复制到输出端口的缓存中.
经总线交换
输入端口经一根共享总线将分组直接传送到输出端口,不需要路由选择处理器的干预.由于总线单一时间只能通过一个数据分组,故交换速率受到总线速率的限制.
经互联网络交换
克服单一、共享式总线带宽限制的一种方法是,使用一个更复杂的互联网络.如纵横式交换机使用由2N条总线构成的互联网络,能够并发转发多个分组,因此是非阻塞的
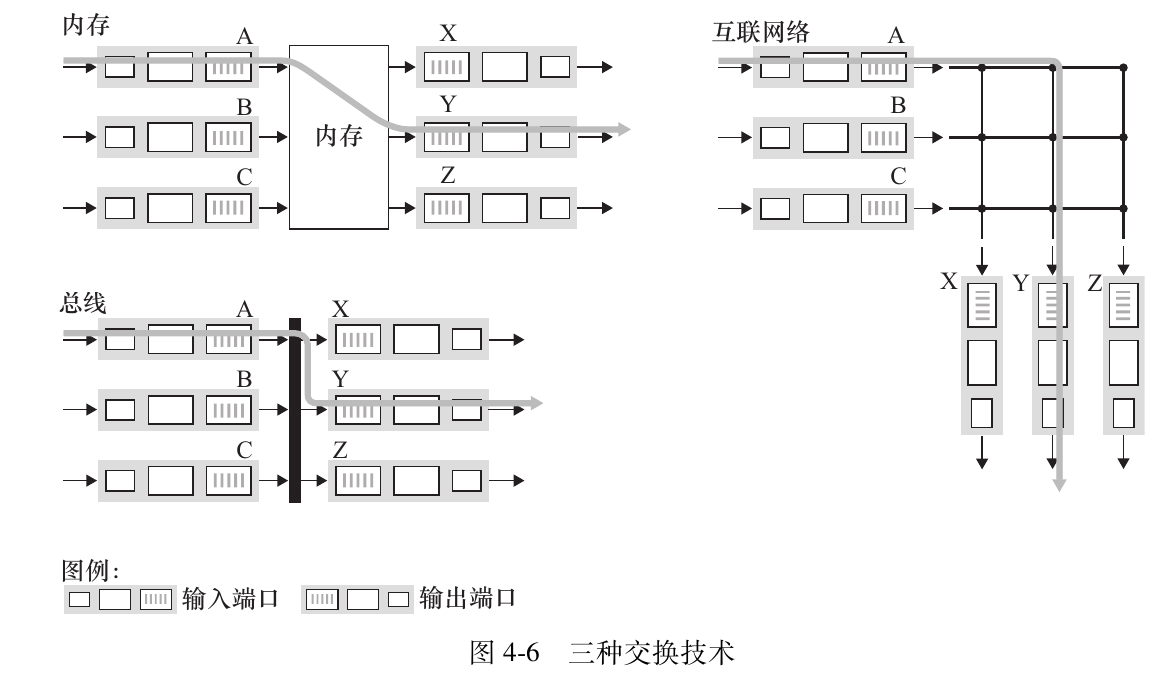
输出端口处理
输出端口处理取出已经存放在输出端口内存中的分组并将其发送到输出链路上
- 分组(packet):从传输层传入的打包好的数据帧
排队问题分析
在输入端口和输出端口处都可以形成分组队列,就像在环状交叉路的类比中我们讨论过的情况,即汽车可能等待在流量交叉点的入口和出口。排队的位置和程度(或者在输入端口排队,或者在输出端口排队)将取决于流量负载、交换结构的相对速率和线路速率。
我们现在更为详细地考虑这些队列,因为随着这些队列的增长,路由器的缓存空间最终将会耗尽,并且当无内存可用于存储到达的分组时将会出现丢包(packet loss)。回想前面的讨论,我们说过分组“在网络中丢失”或“被路由器丢弃”。正是在一台路由器的这些队列中,分组被实际丢弃或丢失。
为什么不加缓存空间?
我们很容易这样想:更多的缓存必定更好,因为更大的缓冲区能承受更大的分组到达率波动,从而降低路由器的丢包率。
但更大的缓冲区也意味着潜在的更长的排队时延。
对于游戏玩家和交互式电话会议用户,几十毫秒的时延就很关键。
如果为了减少丢包而把每跳路由器的缓冲区大小增加10倍,端到端时延可能随之增加10倍。
增加的RTT会使TCP发送方对拥塞或分组丢失的响应变慢:
- TCP依赖RTT来估计超时重传定时器(RTO)。
- RTT增大 → RTO变大 → 检测到丢包后等待更久才重传。
- 拥塞控制窗口增长更慢(慢启动、拥塞避免阶段受RTT影响)。
- 整体吞吐响应性下降,尤其在突发拥塞或间歇性丢包场景。
如何决定分组转发的优先权?
有以下几种调度方法
先进先出( First-In-First-Out,FIFO,也称为First-Come-First-Serve,FCFS)
调度规则按照分组到达输出链路队列的相同次序来选择分组在链路上传输
优先权排队(priority queuing)
针对不同分组或者IP地址配置不同优先级别的权限,每次转发分组时均从当前最高优先级别的队列中选择分组来传输,同一级别则采用FIFO方式
循环排队(round robin queuing discipline)和加权公平排队(Weighted Fair Queuing)
循环排队像优先权排队规则一样给不同分组分类,但是会轮流处理不同类,从而避免低优先级类难以被转发的情况.
加权公平排队会为不同类分配权重,保证在某一时刻下在排队队列中的某一类能够得到对应权重的转发量.
IPv4,IPv6,寻址(3/13)
IPv4数据报格式
网络层中的分组被称为数据报,IPv4数据报的格式如下:
- 版本:使用的IP协议版本,帮助路由器决定如何解释数据报的剩余部分
- 首部长度:用来确定载荷(运输层报文)实际开始的字节
- 服务类型: 可以将不同服务类型的数据报区别开来
- 数据报长度: 首部加上数据的总字节长度,为16bit,故理论最大长度为65535字节,但实际上很少超过1500字节
- 标识,标志,片偏移: 将一个大数据报分片为几个小数据报所需的字段
- 寿命: 确保数据报不会一直在网络中循环
- 协议: 指示数据部分是由哪个协议处理的,例如值为17表示要交给UDP处理
- 首部检验和: 检验是否有数据错误或丢失
- 源IP地址和目的IP地址
- 可选字段: 很少用
- 数据(有效载荷): 来自运输层
IPv4编址
一台主机通常只有一条链路连接到网络 ,当主机中的 IP 想发送一个数据报时,它就在该链路上发送。主机与物理链路之间的边界叫作接口(interface)
路由器与它的任意一条链路之间的边界也叫作接口,因此每台主机与路由器都能发送和接收IP数据报,为了明确源地址和目标地址,故每台主机和路由器接口都有自己的IP地址.
在IPv4协议中,一个IP地址长度为32字节,书写方法为点分十进制记法(dotted-decimal notation),即每个字节都用它的十进制形式书写,因此会有3个点,4个部分,每个部分占8字节,如:
193. 32. 216. 9:11000001 00100000 11011000 00001001
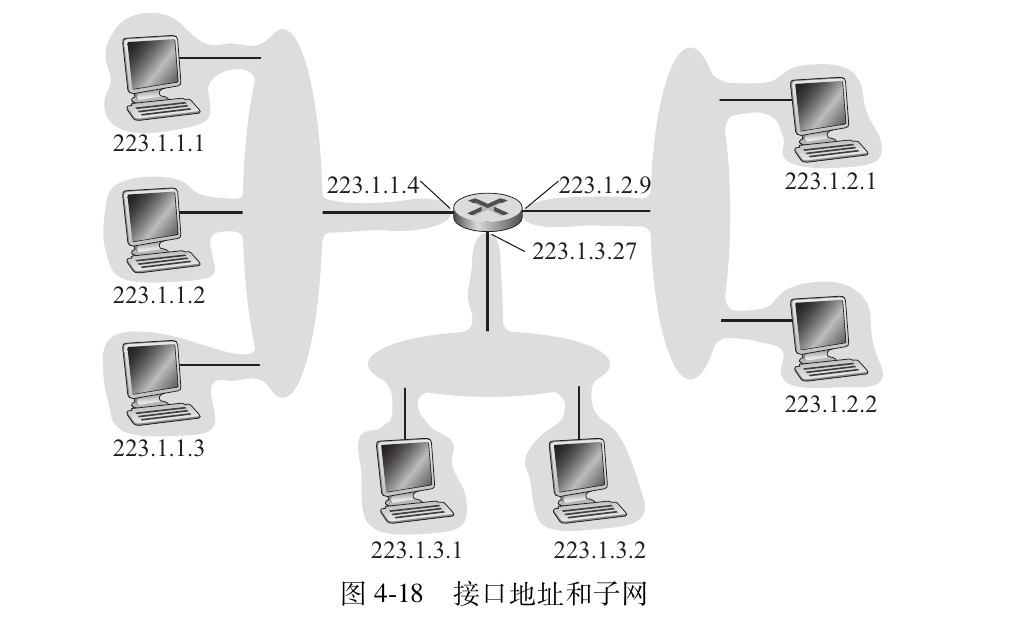
互联这 3 个主机接口与 1 个路由器接口的网络形成一个子网(subnet),IP编址为这个子网分配一个地址223. 1. 1. 0 / 24,其中, /24被称为子网掩码,将地址的前24位设定为该子网的IP地址
表示为255.255.255.0.需要时可以通过将子网掩码与ip地址取和得到子网地址;换句话说,只有前24位等于223.1.1的地址才属于这个子网.
- 可以在cmd输入ipconfig查看自己所属的子网.
IP地址是如何分配的(3/15)
IP 地址由因特网名字和编号分配机构(Internet Corporation for Assigned Names and Numbers,ICANN)管理,是非盈利的.
当某个组织获得了被分配的地址块后,可以为本组织内的主机与路由器接口逐个分配 IP 地址,这主要由动态主机配置协议 (Dynamic Host Configuration Protocol , DHCP)完成.
某给定主机每次与网络连接时能得到一个相同的 IP 地址,或者被分配一个临时的 IP 地址. 除了主机 IP 地址分配外,DHCP 还允许一台主机得知它的子网掩码、它的第一跳路由器地址(也就是直连路由器,常称为默认网关)与它的本地 DNS 服务器的地址等其他信息.
网络地址转换(Network Address Translation,NAT)
NAT(网络地址转换) 是工作在路由器等网关设备上的物理逻辑,它允许整个局域网(LAN)内的成百上千台设备,通过同一个公网 IP 地址(WAN 端)访问互联网。
A. 出站请求 (SNAT - Source NAT)
当你的手机(192.168.1.5)访问网站时:
- 原始数据包:源 IP 是
192.168.1.5,源端口是10001。 - 物理改写:路由器将源 IP 修改为自己的 公网 IP(如
1.2.3.4),并将源端口修改为一个新分配的端口(如5000)。 - 记录映射:路由器在 NAT 表中记下一笔:
5000 端口 <-> 192.168.1.5:10001。
B. 入站响应 (DNAT - Destination NAT)
当网站服务器回传数据时:
- 到达数据包:目标地址是
1.2.3.4:5000。 - 物理查询:路由器查找 NAT 表,发现
5000端口对应的是内网的192.168.1.5:10001。 - 物理还原:路由器将目标 IP 和端口还原,数据包准确送达手机。
IPv6
IPv6将地址长度从32bit增加到128bit,确保了IP地址不会被用完,具体结构如下:
- 版本: 4bit长,字段值为6
- 流量类型: 与IPv4的服务类型类似
- 流标签: 对数据流中的某些数据报给出优先权
- 有效载荷长度: 载荷的字节数量
- 下一个首部: 与IPv4中的协议字段含义一样,表示要交付给哪个运输层协议
- 跳限制: 类似于IPv4中的寿命字段,当跳限制计数变为0时,包被丢弃
- 源地址和目的地址
- 数据: 载荷
事实上,IPv6不再使用子网掩码,而是直接用一个整数表示网络部分的位数,写在地址后的斜线后,如:
fe80::49e0/128
如何兼容IPv4
通过将IPv6数据报整个放入IPv4数据报的载荷部分中,并通过协议字段指示接收方这是一个装入了IPv6的IPv4数据报,从而实现了对网络层中使用IPv4路由器的兼容
泛化转发和SDN(待补充)
中间盒(middlebox)
中间盒: 在源主机和目的主机之间的数据路径上,执行除了 IP 路由器的正常标准功能之外的其他功能的任何中间的盒子,一般可以提供以下三种功能服务:
- NAT转换
- 安全服务: 如防火墙和电子邮件过滤器等
- 性能增强: 提供内容缓存等功能
控制平面
路由选择算法
按照集中式的还是分散式的来给算法分类:
- 集中式路由选择算法(centralized routing algorithm):也被称为链路状态(Link State,LS)算法,需要提前得知网络中每条链路的开销,从而计算出当前节点的最低开销路径
- 分散式路由选择算法(decentrlized routing algorithm): 每个节点仅有与其直接相连的节点链路开销,通过迭代和通信逐渐计算出最低开销路径,距离向量(Distance Vector)算法是一个代表.
链路状态(LS)算法
通过链路状态广播(link state broadcast)算法来获取整体的节点信息,并根据Dijkstra算法找到最佳路径.
但是,实际应用中会产生振荡(Oscillation)问题,也就是当路由恰巧都沿着最短路径转发时,这条路径的开销由于流量增大而不再是最优路径,因此路由都转向原本开销比较高但现在相对是开销最低的那条线路,又导致这条线路开销变高,路由又都回到原来的路由转发路径上,这样来回切换路径显然不利于网络减小时延.
距离向量(DV)算法
使用Bellman-Ford算法
因特网中自治系统内部的路由选择: OSPF
如果将网络看作一个大规模的路由器互联网络会遇到以下两个问题:
- 规模瓶颈(Scalability):数亿台设备若运行单一路由算法,将导致内存耗尽、广播风暴以及算法(如距离向量)无法收敛。
- 管理自治(Administrative Autonomy):不同 ISP 需要独立控制内部协议、隐藏拓扑结构,并按自身策略进行管理。
因此,设计者将路由器规划成一个自治系统( Autonomous System,AS): - 构成:处于相同管理控制下的路由器和链路集合。
- 标识:每个 AS 拥有全局唯一的 AS 号 (ASN),由 ICANN 授权机构分配。
- 划分:ISP 可作为一个 AS,也可拆分为多个 AS。
光这样说还不够,看下面这个表格:
| 运营商 | 网络名称 | AS 号 (ASN) | 角色 |
|---|---|---|---|
| 中国电信 | ChinaNet (163 骨干网) | AS4134 | 全球最大的 AS 之一,承载绝大多数宽带流量。 |
| 中国电信 | CN2 (下一代承载网) | AS4809 | 独立的 AS,专注于高质量、低延迟的精品业务。 |
| 中国联通 | 中国联通骨干网 | AS4837 | 原中国网通与联通合并后的核心 AS。 |
| 中国移动 | 中国移动骨干网 | AS9808 | 移动宽带及移动端流量的核心承载 AS。 |
- 这样就很好理解了,当我们接入网络的时候,实际上是进入了某一个运营商的AS,而不是直接接入整个互联网.
在一个AS内部运行的路由选择算法称为(intra-autonomous system routing protocol).
开放最短路优先 ( OSPF )
该算法使用Dijkstra和周期性的路由广播,也就是说:
路由器向自治系统内所有其他路由器广播路由选择信息,而非只向相邻路由器广播. 每当一条链路的状态发生变化时(如开销的变化或连接 / 中断状态的变化), 路由器就会广播链路状态信息 。即使链路状态未发生变化,它也要周期性地(至少每隔 30min一次)广播链路状态.从而能够运用Dijkstra得到正确的结果.
ISP之间的路由选择:BGP
前面讨论的是AS内部的路由选择,现在我们来考虑AS之间的路由选择,在internet中,所有AS运行相同的路由选择协议: 边界网关协议(Border Gateway Protocol,BGP).
BGP的作用
作为一种 AS 间的路由选择协议,BGP 为每台路由器提供了一种完成以下任务的手段:
-
从邻居 AS 获得前缀的可达性信息: 特别是,BGP 允许每个子网向因特网的其余部分通告它的存在。一个子网高声宣布 “我存在,我在这里”,而 BGP 确保在因特网中的所有 AS 知道该子网。如果没有 BGP 的话,每个子网将是隔离的孤岛,即它们孤独地存在,不为因特网其余部分所知和所达。
-
确定到该前缀的 “最好的” 路由: 一台路由器可能知道两条或更多条到特定前缀的不同路由。为了确定最好的路由,该路由器将本地运行一个 BGP 路由选择过程 (使用它经过相邻的路由器获得的前缀可达性信息)。该最好的路由将基于策略以及可达性信息来确定。
- 前缀指的是例如138.16.68/22这样的AS子网
通告BGP路由信息
一个AS中有两种类型的路由器:网关路由器(gateway router)和内部路由器(internal router),网关路由器直接与其他AS中的路由器相连接,内部路由器仅连接AS内部的主机和路由器
与先前AS内部的路由广播类似,网关路由器也会将对应的转发信息传递给相邻的网关路由和内部路由,从而找到不同AS之间的转发路由路径
找到最短路径(待补充)
IP任播(anycast)
路由选择策略
SDN控制平面
ICMP: 因特网控制报文协议
wiki
互联网控制消息协议(英语:Internet Control Message Protocol,缩写:ICMP)是互联网协议族的核心协议之一。它用于网际协议(IP)中发送控制消息,提供可能发生在通信环境中的各种问题反馈。通过这些信息,使管理者可以对所发生的问题作出诊断,然后采取适当的措施解决。ICMP与传输协议(如TCP和UDP)显著不同:它一般不用于在两点间传输数据。它通常不由网络程序直接使用,除了 ping 和 traceroute 这两个特别的例子.
事实上,ICMP位于IPv4和IPv6报文里面,用于提供网络发生问题时返回报错信息
链路层
OVERVIEW
- 节点: 运行链路层协议的任何设备,包括主机,路由器,交换机,WiFi接入点
- 链路: 连接相邻节点的通信信道
链路层需要提供的服务
- 成帧(framing): 将网络层的数据报封装成链路层帧
- 协调多个节点之间的通信: MAC协议
- 可靠交付: 通过确认和重传确保数据不出错和丢失
- 差错检测
链路层是如何实现的
链路层控制器的大部分功能是在硬件中实现的,但也有部分链路层是在运行与主机CPU上的软件实现的.
差错检测和纠正
奇偶校验
假设要发送的信息D有d比特,在偶校验方案中,发送方附加一个校验比特,使得者d+1个比特中1的总数是偶数;在奇校验方案中则保证是奇数.
接收方只需要检测接收的d+1个比特中1的个数即可以验证是否出现差错,比如在偶校验方案中发现了奇数个1比特,则说明至少出现了1个比特差错.
但如果出现了偶数个比特的差错,那就无法检测出差错了.因此,可以采用二维的奇偶校验方案,通过行和列来检验从而减小没有检测到差错的概率
检验和方法
与TCP/UDP协议中采用的检验和类似.
循环冗余检测(Cyclic Redundancy Check,CRC)(待补充)
双方协商取一个最高位为1的r+1位多项式G,发送方在d位数据段D的后端附加r个附加比特R,使得这个d+r位数据在模2算术下可以被G整除,接收方只需要用G去除这个收到的数据就可以知道是否出现差错.
多路访问协议(multiple access protocol)
该协议的目标是实现多个发送和接收节点对同一个共享信道的访问.
因为所有的节点都能够传输帧,所以多个节点可能会同时传输帧,那么其他节点就会同时接收到多个帧,发生碰撞(collide),这时没有一个节点能够有效获得传输的帧.
在理想情况下,对于速率为 R bps 的广播信道,多路访问协议应该具有以下所希望的特性:
- 当仅有一个节点发送数据时,该节点具有 R bps 的吞吐量;
- 当有 M 个节点发送数据时,每个节点吞吐量为 R / M bps. 这不必要求 M 个节点中的每一个节点总是有 R / M 的瞬间速率,而是每个节点在一些适当定义的时间间隔内应该有 R / M 的平均传输速率;
- 协议是去中心化的; 这就是说不会因某主节点故障而使整个系统崩溃;
- 协议是简单的,使实现不昂贵.
信道划分协议(过)
随机接入协议(待补充)
在随机接入协议中,一个传输节点总是以信道的全部速率(即 R bps)进行发送. 当有碰撞时,涉及碰撞的每个节点反复地重发它的帧(也就是分组),到该帧无碰撞地通过为止. 但是当一个节点经历一次碰撞时,它不必立刻重发该帧. 相反,它在重发该帧之前等待一个随机时延. 涉及碰撞的每个节点独立地选择随机时延. 因为该随机时延是独立地选择的,所以下述现象是有可能的:这些节点之一所选择的时延充分小于其他碰撞节点的时延,并因此能够无碰撞地将它的帧在信道中发出.
Switched Local Area Networks
Link-Layer Addressing and Address Resolution Protocol(ARP)
MAC地址
A link-layer address is variously called a LAN address, a physical address, or a MAC address.
事实上,并不是主机或路由器具有链路层地址,而是它们的适配器(即网络接口)具有链路层地址
The MAC address is 6 bytes long, giving 2^48 possible MAC addresses. 尽管MAC地址是一个固定值并且是唯一的,但现在有可能用软件改变某个接口的MAC地址.
- 需要注意的是,一般来说一个设备的MAC地址总是不变的,而对应的IP地址总是根据连接到的网络而改变
一般来说,当源适配器要向向一个目的适配器发送帧时,它会讲目的适配器的MAC地址插入帧中,并将该帧发送到局域网中;有时候源适配器或者中途经过的交换机会将帧广播到所有的适配器.
当目的适配器接收到帧时,如果帧中的目的MAC地址与自己的MAC地址匹配,则会提取出封装的数据报并沿着协议栈向上传输;如果不匹配,则直接丢弃这个帧.
- 有时候源适配器需要让局域网的所有适配器接收并处理自己的帧,这个时候,可以在目的地址字段插入一个特殊的MAC广播地址,对于6字节MAC地址的局域网来说,广播地址是48个连续的1组成的字符串
Address Resolution Protocol,ARP(地址解析协议)
为了在发送链路层帧的时候指明接收该帧的适配器,需要提前知道适配器的MAC地址,从而实现包的正确发送,因此我们采用ARP协议来根据适配器对应路由器或主机的IP地址,找到其MAC地址
- ARP: 将网络层地址与链路层地址相互转换的协议.它和DNS的作用基本类似,但一个重大区别是: DNS可以解析因特网上任意主机或者域名为IP地址,但ARP只为同一个子网的主机和路由器接口解析IP地址为MAC地址
ARP原理
每台主机或者路由器在内存中有一个ARP表(ARP table),包含了IP地址与MAC地址的映射关系,还有保存时限值,指示了从表中删除该映射的时间.
主机要发送帧前,先要发送一个ARP packet给自己的适配器,这个ARP分组包括发送和接收方的IP地址以及自己的MAC地址,指示适配器使用MAC广播地址发送这个分组并发送该链路层帧,从而让子网的所有适配器接收这个分组,IP地址与该ARP packet中包含的目的IP地址匹配的适配器会向发送方传回一个响应ARP packet,让发送方可以更新它的ARP表.
- 从这个角度来看,ARP与IP处于同一级别,都位于网络层
如何跨越子网传输数据
通过上面的论述,我们可以发现,ARP只适用于子网内部的转发,当我们要跨越子网转发数据时,应该先将数据转发给网关路由,再由网关路由来根据链路层帧包含的IP地址跳到下一个路由器,直到转发到目标主机的网关路由,再将数据交给目标主机
Ethernet
- 以太网(Ethernet)几乎完全占据了有线局域网市场
以太网的帧结构
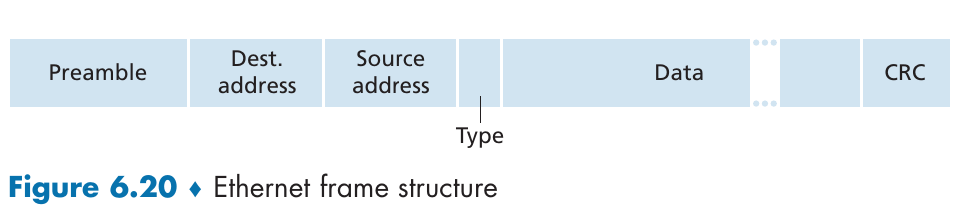
- Data field (46 to 1,500 bytes): This field carries the IP datagram. The minimum size of the data field is 46 bytes.This means that if the IP datagram is less than 46 bytes, the data field has to be “stuffed” to fill it out to 46 bytes.
- Destination address (6 bytes): This field contains the MAC address of the destination adapter.
- Source address (6 bytes): This field contains the MAC address of the adapter that transmits the frame onto the LAN
- Type field (2 bytes): 指示数据字段所用网络层协议的类型
- Cyclic redundancy check (CRC) (4 bytes): 检测帧差错
- Preamble (8 bytes): 用于唤醒适配器,告诉它现在有一个以太网帧来了
以太网的无连接传输
以太网技术向网络层提供不可靠服务. 具体来说, 当适配器 B 收到一个来自适配器 A 的帧, 它对该帧执行 CRC 校验, 但是当该帧通过 CRC 校验时它既不发送确认帧; 而当该帧没有通过 CRC 校验时它也不发送否定确认帧. 当某帧没有通过 CRC 校验, 适配器 B 只是丢弃该帧. 因此, 适配器 A 根本不知道它传输的帧是否到达了 B 并通过了 CRC 校验.
在链路层缺乏可靠传输有助于使以太网变得简单且便宜. 但是这也意味着传递到网络层的数据报流可能存在间隙.
如果由于丢弃了以太网帧而存在间隙, 主机 B 上的应用也会看见这个间隙吗? 正如我们在第 3 章中所学到的, 这完全取决于该应用是使用 UDP 还是 TCP.
- 如果应用使用的是 UDP, 则主机 B 中的应用确实会看到数据中的间隙.
- 另一方面, 如果应用使用的是 TCP, 则主机 B 中的 TCP 将不会确认包含在丢弃帧中的数据, 从而引起主机 A 的 TCP 重传.
注意到当 TCP 重传数据时, 数据最终将回到曾经丢弃它的以太网适配器. 因此, 从这种意义上来说, 以太网确实重传了数据, 尽管以太网本身并不知道它正在传输的是一个包含全新数据的全新数据报, 还是一个包含已经被传输过至少一次的数据的数据报.
链路层交换机(Link-Layer Switches)
转发和过滤
Filtering is the switch function that determines whether a frame should be forwarded to some interface or should just be dropped.
Forwarding is the switch function that determines the interfaces to which a frame should be directed, and then moves the frame to those interfaces.
假定目的地址为 DD-DD-DD-DD-DD-DD 的帧从交换机接口 x 到达,那么会有以下三种情况:
- 交换表中没有对应 DD-DD-DD-DD-DD-DD 的表项,则将这个帧广播到所有接口(除了接口x,因为帧是从接口x来的)
- 交换表中有对应 DD-DD-DD-DD-DD-DD 的表项,但是对应接口为x,那么显然你不可能把从接口x收到的帧再送回接口x,只能就地丢弃这个帧
- 交换表中有对应 DD-DD-DD-DD-DD-DD 的表项,对应接口不是x而是y,那么交换机就需要把这个帧送入接口y
疑问:第二种可能中,如果是局域网通信的话,那不就有可能用的是同一个接口吗?
在局域网(LAN)中,如果两个主机 A 和 B 都在“同一个接口”下,通常只有两种物理物理场景:
- 场景 A:接了集线器(Hub)
你将 A 和 B 都接在一个外接 Hub 上,再把 Hub 连到交换机的接口 。 - 场景 B:共享介质(旧式同轴电缆)
所有主机物理上连在同一根线上。
交换机(Switch)的核心作用是隔离冲突域并跨端口转发。
当主机 A 发送一个目的 MAC 为 B 的帧进入接口 时:
- 查表:交换机查找 MAC 地址表,发现 B 的 MAC 对应接口也是 。
- 判断:交换机意识到,“目的地”和“来源地”都在同一个物理方向上。
- 结论:如果 A 和 B 都在接口 下方,那么当 A 发出信号时,信号在到达交换机之前,物理上已经流经了 B(如果是 Hub 或共享总线)。
底层逻辑:交换机认为,既然目标 MAC 就在接收端口所在的网段内,那么目标主机 B 应该已经通过物理介质直接收到了这个帧。如果交换机再把它从接口 “弹回”去,不仅是浪费带宽,更会导致 B 收到两份重复的数据帧。
交换表的建立与交换机的自学习
- 交换表初始为空
- 对于在每个接口接收的帧,交换机会在表中记录以下信息:
- 该帧的源MAC地址
- 该帧是从哪个接口进来的
- 当前时间
- 如果一段时间后,交换机没有接收到过与记录的源MAC地址相同的帧,那么就会在表中删除这个地址
那么,让我们来详细分析一下一个新产生的帧被目的MAC地址对应的交换机接收的过程:
- 当这个帧进入第一个交换机时,由于交换机不认识这个帧,故会在所有接口转发该帧并记录该帧信息
- 经过很多次转发,在传播路径上的交换机都记录了该帧的三种信息
- 当目的MAC地址对应的交换机接收到该帧时,由于目的MAC地址对应的服务器一定已经将自己的信息存在了该交换机中(思考一下是为什么),那么只需要将该帧送入服务器的适配器即可完成整个流程.
虚拟局域网(VLAN)
- wiki
- 由于书上讲的不明不白,所以去额外找资料了
VLAN的工作原理是在广播域内转发的网络帧上添加标签,从而使网络流量看起来如同被分割在不同的网络中。这样即使在同一个物理网络,VLAN也能将网络隔离开来,而无需部署多套电缆和网络设备。
无线网络概览
前面谈的都是有线网络,现在来谈谈WiFi,4G等无线网络,它由以下三个要素组成:
- 无线主机: 可以是手机,电脑,家用电器,可以是移动的,也可以是位置固定不动的
- 无线链路: 主机通过无线链路连接到一个基站或者另一个主机
- 基站: 负责收发无线链路数据
我们可以把无线网络分为四类:
- 具有基站的单跳: 基站和主机之间可以直接通信,不需要经过中继节点,日常见到的无线网络如WiFi和4G都属于这一类型
- 无基站的单跳: 由一个主机进行收发无线数据,其他设备与该主机通信,而不通过基站,蓝牙协议便是典型的例子
- 具有基站的多跳: 主机与基站通信需要经过中继节点
- 无基站的多跳: 通过多个主机节点进行通信,这显然是最难设计的一类网络
无线链路的特征
与有线链路相比,无线链路有以下三个特点:
- 信号强度递减: 电磁波穿过物体时强度将减弱,也就是路径损耗
- 来自其他通信源的干扰: 同一频段的电磁波会相互干扰
- 多路径传播: 电磁波会经过地面或者物体反射,导致出现多径传播的问题
显然,无线网络更容易出现差错,因此我们需要使用更为可靠的传输方法.
- 信噪比( Signal-to-Noise Ratio,SNR):单位为dB,是接收到的信号振幅与噪声幅度比值的以10为底的对数的20倍,显然,信噪比越大,信号就越干净.
- 比特差错率(BER): 接收方收到的一个比特为错误的概率
物理层的通信有以下特点:
- 使用同一个调制方法,SNR越高,BER越低: 因此发送方可以通过增加传输功率提高SNR来降低BER,但是这样会消耗更多的能量,并且当功率超过阈值时不再有实际增益
- 对于给定的SNR,调制方法的传输速度越高BER越高,这很容易理解,速度越快越容易出差错
- 对于给定的信道我们可以采用不同的调制技术
CDMA(待补充)
WiFi
尽管无线局域网(WLAN)的通信有很多技术可以选用,但是WiFi占据着统治地位.
WiFi的正式名称为IEEE 802. 11 无线局域网
基本服务集 (BSS) 是WiFi的基本构件,有两个部分:
- 无线站点 (Station):手机、笔记本等终端设备。
- 接入点 (Access Point,AP):起中央基站作用的节点。
信道与关联
当管理员安装AP时,需要为AP分配一个服务集标识(Service Set Identifier,SSID)和一个信道号.
802.11运行在 2. 4GHz ~ 2. 485GHz的频段中,由11个部分重叠的信道组成, 当且仅当两个信道由 4 个或更多信道隔开时它们才无重叠,因此管理员需要指示AP的信道号避免影响到其他AP.
显然,当你进入咖啡馆时,你可以收到很多个AP传来的信号,那么我们是符合与一个特定AP连接的呢?
802.11协议要求每个AP周期性的发送信标帧,该帧包括该AP的SSID和MAC地址,供无线站点接收并处理;当然,主机也可以自己发送广播帧来主动扫描附近的AP,选定关联AP,具体过程如图所示:
选定与之关联的 AP 后,无线主机向该 AP 发送一个关联请求帧,并且该 AP 以一个关联响应帧进行响应。注意,对于主动扫描需要第二个请求 / 响应握手 ,因为一个对初始探测请求的帧进行响应的 AP 并不知道主机选择哪个 ( 可能多个 ) 响应的 AP 进行关联 , 这与 DHCP 客户能够从多个 DHCP 服务器中进行选择有诸多相同之处
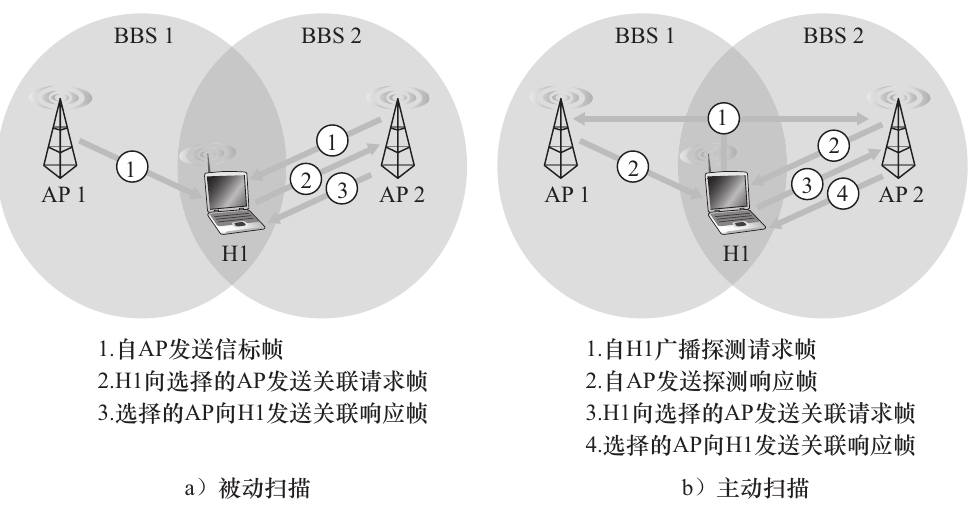
与AP连接之后,主机便会发送DHCP报文获取自己的IP地址,从而与互联网连接.
802. 11采用的传输协议: CSMA/CA
802.11采用的MAC协议类型为随机接入协议,称为带碰撞避免的CSMA(CSMA with collision avoidance), 简称为CSMA/CA.
之所以802.11采用碰撞避免而非和以太网相同的碰撞检测,有以下两个原因:
- 检测碰撞需要主机同时具有发送信号和接收其他站点信号的能力,而802.11适配器接收到的信号强度往往远小于发送出去的信号强度
- 无线信号存在衰减,多路传播,隐藏终端等问题,无法检测到所有的碰撞
802.11的链路层确认方案
由于无线链路中的帧不能无损的到达目的地,因此802.11采用链路层确认方案来实现重传机制.
目的站点收到一个通过CRC校验的帧后,等待一小段时间-这被称为短帧间间隔(short inter-frame spacing),然后发回一个确认帧,如果发送站点在给定时间内没有收到确认帧,它就假定出现了错误并进行重传,如果若干次重传后仍未收到确认帧,则放弃发送并丢弃该帧.
为什么现代以太网不重传而802.11重传
因为802.11的环境极易丢包,如果依靠上层协议如TCP的重传机制,由于跨越了多层硬件,传输速率将会大幅度下降;而以太网线路的环境非常稳定,发生丢包的概率几乎为零,将少量的丢包问题交给上层协议处理可以减少不必要的设计复杂度.
CSMA/CA协议的详细原理
- 如果有一个帧要发送,发送站监听到信道空闲时,它等待一小段时间后发送该帧-这被称为分布式帧间间隔(distributed inter-frame space)
- 如果信道被占据,则站点选取一个随机回退值,在侦听到信道空闲时减小该值,信道繁忙时则保持该值不变
- 计数值减到零时,该站点发送帧并等待确认
- 如果收到确认,则帧被正确接收.如果要传输另一个帧,站点将从第二步重新开始;如果没收到确认,则站点进入第二步并在一个更大的范围内选取随机值
满格信号网速仍然很慢的原理
当大量主机使用同一个AP时,为了避免碰撞,单一主机的等待时间大量延长,从而导致了网速的降低;同时,AP的上行光纤容量有限,不允许所有设备以最大功率同时传输.
处理隐藏终端问题
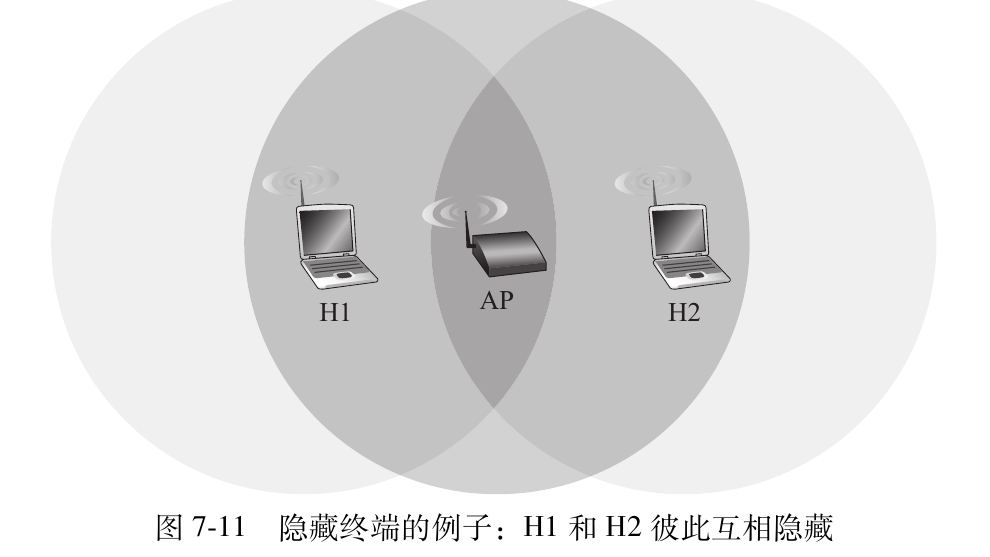
- 尽管每个无线站点对AP都不隐藏,但两者彼此是隐藏的
当H1和H2要发送帧时,由于它们彼此是看不见的,因此都以为信道是空闲的,就会同时发送并导致碰撞.
为了避免碰撞,802.11通过让站点使用请求发送(Request to Send,RTS)控制帧和允许发送(Clear to Send,CTS)控制帧来预约何时访问信道.
发送方在发送帧之前,首先向AP发送一个RTS帧,指示自己传输帧和收到确认帧所需的总时间,AP收到该帧后广播一个CTS帧,指示发送方明确的发送许可并告知其他站点在这段时间内不要发送,从而避免碰撞.
- 这两个控制帧都很短,所以在这个过程中发生碰撞的可能性很小
尽管 RTS / CTS 交换有助于减少碰撞 , 但它同样引入了时延并消耗了信道资源。因此 ,RTS / CTS 交换仅仅用于为长数据帧预约信道 。 在实际中,每个无线站点可以设置一个 RTS门限值,仅当帧长超过门限值时,才使用 RTS / CTS 序列。对许多无线站点而言 ,默认的RTS 门限值大于最大帧长值 , 因此对所有发送的 DATA 帧,RTS / CTS 序列都被跳过。
802.11的帧结构
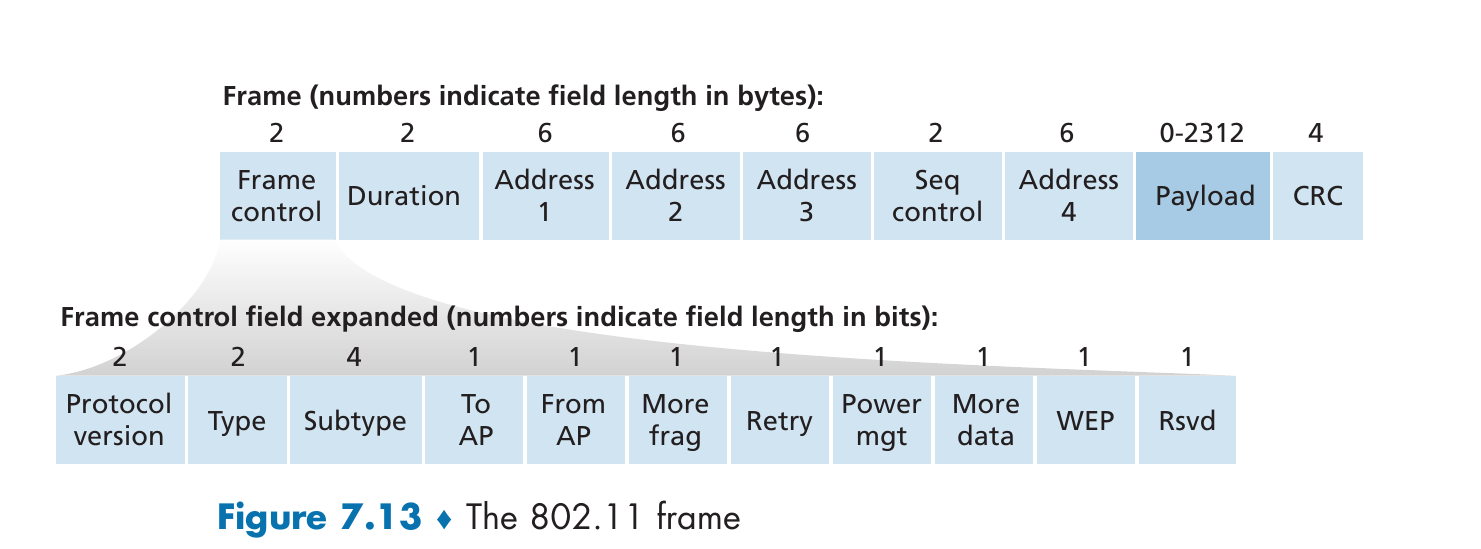
接下来对其中的重要组成部分做一点分析:
- 有效载荷与CRC字段
- 地址字段: 地址4仅在AP相互转发时使用,前三个字段的定义如下:
- 地址1是要接收该帧的站点MAC地址
- 地址2是传输该帧的站点MAC地址
- 地址3是子网默认网关的MAC地址
- 序号,持续期,帧控制字段
无线站点在同一子网中的不同BSS之间移动
随着 H1 逐步远离 AP1 ,H1 检测到来自 AP1 的信号逐渐减弱并开始扫描一个更强的信号.H1 收到来自 AP2 的信标帧.
H1然后与 AP1 解除关联,并与AP2 关联起来,同时保持其 IP 地址和维持正在进行的 TCP 会话.新AP2 会发送以太网广播,强制沿途交换机更新路径.
蓝牙
蓝牙网络运行在 2.4 GHz ISM(工业、科学、医学) 免授权频段。由于该频段同时被微波炉、车库门遥控器和无绳电话等多种设备占用,蓝牙在设计之初就将抗噪与抗干扰作为核心目标。
蓝牙的物理原理
- 时分复用(TDM):蓝牙无线信道被划分为时长为 625 微秒 的时间隙。
- 频分跳频扩展频谱(FHSS):在每个时间隙中,发送端在 79 个信道中的某一个进行传输。信道(频率)在每个时隙间按照已知但伪随机的规律切换。
- 抗干扰逻辑:通过跳频技术,即使 ISM 频段内存在其他设备的干扰,也只会影响到极少数特定时隙的蓝牙通信,从而保证了整体链路的稳健性。目前蓝牙数据速率最高可达 3 Mbps。
蓝牙网络的结构
在蓝牙网络(Piconet)中,设备角色分为以下三类:
- 主节点 (Master Device):核心控制单元,负责管理连接数量、调度时隙以及控制所有连接设备的传输功率。
- 客户设备 (Client/Slave Device):受控单元,遵循主节点的跳频序列进行通信。
- 存放设备 (Parked Device):低功耗睡眠模式设备。它们保持与主节点的同步,但不参与数据传输,仅在需要时由主节点唤醒进入活跃状态。
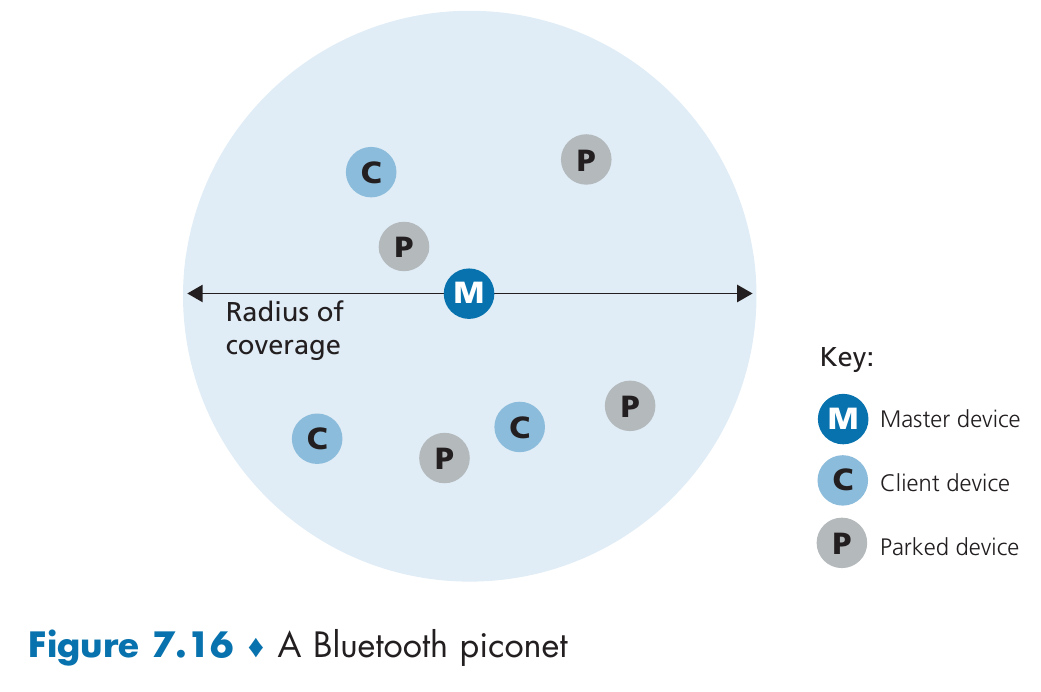
主节点如何与其他设备连接
连接过程本质上是一个从“频率盲区”到“时间与频率双重同步”的过程,分为 查询(Inquiry) 和 寻呼(Paging) 两个阶段:
第一阶段:设备发现(查询)
- 广播探测:主节点在 32 个不同的信道上轮流发送询问消息,并将该序列重复传输多达 128 次,以确保覆盖所有可能的监听频率。
- 被动监听:潜在的客户设备在自己随机选择的频率上进行监听。
- 随机回退机制:一旦客户设备接收到查询,它会在 0 ~ 0.3 秒 之间选择一个随机时间量进行回退。这种“随机退避”设计是为了防止多个客户设备同时响应主节点而引发信号冲突。
- 身份响应:回退结束后,客户设备发送包含其唯一设备 ID 的报文响应主节点。
第二阶段:建立连接(寻呼)
- 定向寻呼:主节点在发现范围内所有潜在设备后,开始针对特定设备发送 32 条寻呼邀请报文。由于此时客户设备尚未获得跳频序列,主节点仍需在多个频率上重复发送。
- 确认握手:客户设备接收到寻呼报文后,返回 ACK(确认) 报文。
- 参数交付:主节点随后向客户设备发送关键配置信息,包括:
- 跳频序列模式(告知未来的频率路径)。
- 时钟同步信息(校准通信时间基准)。
- 活跃成员地址(分配逻辑地址)。
- 轮询激活:最后,主节点使用已同步的跳频模式对该客户设备进行轮询(polling)。一旦回复成功,双方正式进入连接状态,实现网络层面的握手。
更上层发生了什么
我们可以发现,蓝牙的链路层连接逻辑与其他的协议完全不同,这从而说明蓝牙的上层逻辑也与其他的协议不同,这里就不介绍了.
Cellular Networks: 4G and 5G
无线网络分为无线局域网和无线广域网,我们前面所说的WiFi和蓝牙就属于局域网,而这里的4G/5G就属于广域网了.
The term cellular(蜂窝) refers to the fact that the region covered by a cellular network is partitioned into a number of geographic coverage areas, known as cells.
Each cell contains a base station that transmits signals to, and receives signals from, the mobile devices currently in its cell.
4G LTE Cellular Networks: Architecture and Elements
The 4G networks that are pervasive as of this writing in 2020 implement the 4G Long-Term Evolution standard, or more succinctly 4G LTE.
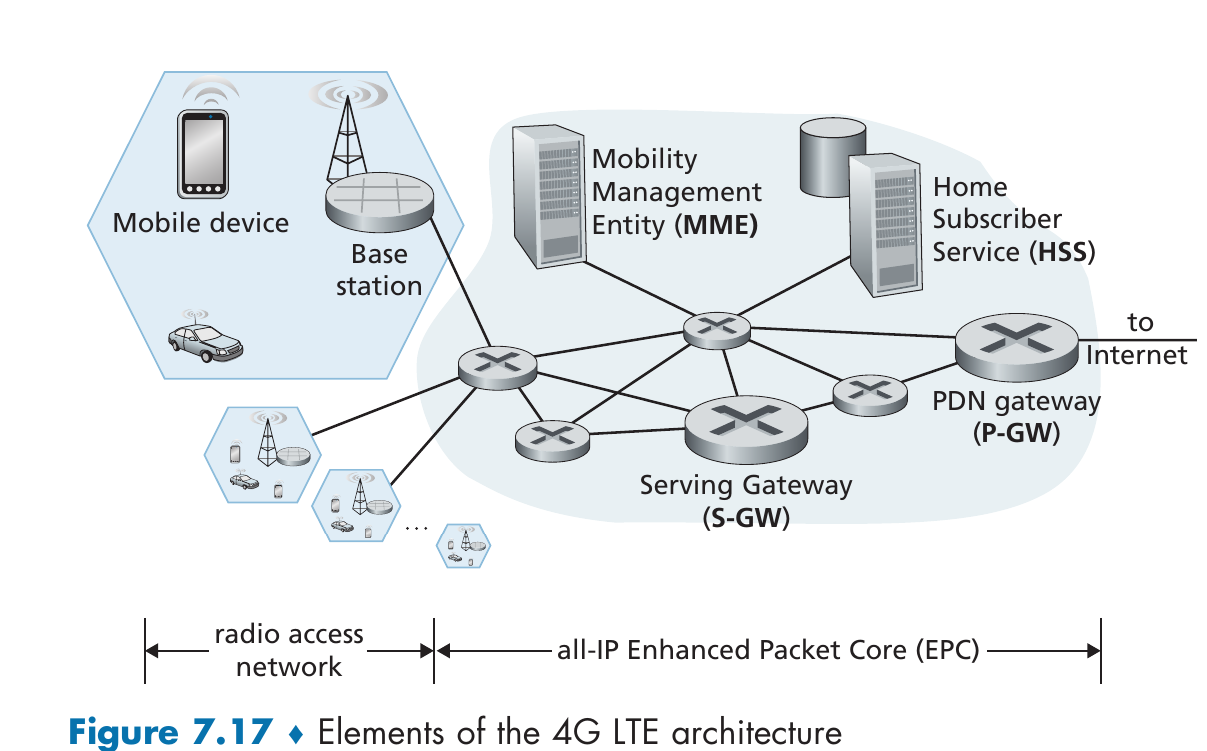
4G网络由以下几个部件构成:
- Mobile device: 连接到蜂窝运营商网络的智能手机 、 平板电脑、笔记本电脑或物联网设备
- 该移动设备还具有全球唯一的 64 位标识符,称为国际移动用户身份 ( IMSI),存储在其 SIM ( 用户身份模块) 卡上。IMSI 在全球蜂窝网络系统中识别用户,包括用户所属的国家和归属蜂窝网络 。
- Base Station: The base station is responsible for managing the wireless radio resources and the mobile devices with its coverage area.
- 这类似于WiFi中的AP,但还有很多额外的功能
- Home Subscriber Server (HSS): The HSS is a database, storing information about the mobile devices for which the HSS’s network is their home network.
- Serving Gateway (S-GW), Packet Data Network Gateway (P-GW), and other network routers: 用于实现NAT,路由转发等功能
- Mobility Management Entity (MME): 控制平面部件,用于验证设备,设置路径,追踪设备位置
无线链路对高层协议的影响
鉴于无线链路传播的比特差错率远高于有线链路,因此需要对上层协议如TCP连接做出针对性的处理
在所有情况下,TCP 的接收方到发送方的 ACK 都仅仅表明未能收到一个完整的报文段,发送方并不知道报文段是由于拥塞或切换 , 还是由于检测到比特错误而被丢弃的。在所有情况下 ,发送方的反应都一样 , 即重传该报文段 。 TCP 的拥塞控制响应在所有场合也是相同的 ,即 TCP 减小其拥塞窗口,这会导致带宽利用率骤降.
链路层重传 (LL-ARQ)
这是解决无线丢包的最前线。LTE、5G 或 Wi-Fi 协议在数据链路层(MAC/RLC 层)实现了快速重传。
- 机制: 基站与终端之间发现包序列不连续时,直接在二层进行重传,不向网络层汇报。
- 代价: 引入了抖动 (Jitter),因为链路层重传会导致部分包延迟到达。
拥塞控制算法的进化 (BBR)
Google 提出的 BBR (Bottleneck Bandwidth and RTT) 算法改变了判断逻辑。
- 原理: BBR 不再将“丢包”作为减速信号。它通过周期性探测带宽极大值和延迟极小值来构建网络模型。
- 实战表现: 在一定比例(如 5% ~ 15%)的随机丢包环境下,BBR 能维持几乎满带宽的传输速率,而 CUBIC 则会因为不断减半窗口而彻底卡死。
选择性确认 (SACK)
原生 TCP 采用累积确认,丢一个包可能导致后续一连串包被重传。
- 机制: 启用
TCP_SACK选项。接收端在 ACK 中告知发送端具体哪些数据块(Ranges)已收到。 - 效果: 发送端可以精确补齐缺失的数据,而不是盲目重传所有未确认的包。
拆分连接协议 (Split-TCP / Proxy)
在移动通信核心网中,常使用 PEP (Performance Enhancing Proxy)。
- 拓扑:
终端 <——无线链路——> 基站/边缘网关 <——有线主干——> 服务器。 - 机制: 将一个 TCP 连接拆分为两段。无线段使用针对高丢包优化的协议(如调整过初始窗口、禁用慢启动退避的私有协议),有线段保持标准 TCP。
- 逻辑: 避免了无线端的局部丢包反馈到远端服务器,缩短了重传的往返时间 (RTT)。
网络安全
网络通信中的安全需要满足以下要求:
- 机密性(confidentiality): 仅有发送方和希望的接收方能够理解传输报文的内容,这需要报文能够被加密和解密
- 完整性(message integrity): 通信内容在传输过程中不应该被篡改,这需要我们实现数据检验和可靠的传输通道
- 通信认证(end-point authentication): 发送方和接收方都需要能够证明另一方的身份是真实的
- 防御恶意攻击(operational security): 通过防火墙和入侵检测系统来防御网络攻击
密码学
我们现在假设A要向B发送一个报文,最初的文本被称为明文(plaintext),A使用密钥(key)m来加密明文,从而得到密文(ciphertext),并将其发送出去.
B为了解密这个密文,需要使用密钥n来处理这个密文,从而得到明文.
显然,加密过程中最关键的就是密钥了,根据密钥是否对称(相同)可以将加密方式分为两种:
- 对称密钥系统: A和B所用的密钥是相同而且保密的,否则就没有任何意义了
- 非对称密钥系统(也称为公开密钥系统): 有两个密钥,一个是公开的密钥,称为公钥,所有人都可以获取;另一个是只有A或者B才知道的密钥
攻击手段
根据攻击者掌握的信息,大致有三种攻击手段:
- 密文攻击: 入侵者只截取到了密文,破解难度最高
- 已知明文攻击: 攻击者事先知道部分明文对应的密文
- 选择明文攻击: 攻击者能够选择任意一段明文并获取对应的密文,破解难度最低
对称密钥
Caesar Cipher(凯撒密码)
密钥为字母表偏移量,很容易被破解
Block Cipher(块密码)
- TLS采用的就是这个加密方式
将明文划分为固定长度k的块,通过一一对应的映射函数将其转换为相同长度的密文块.如果我们让k=3,就需要让000到111这8个输入转换到对应的三比特输出.
尽管当增大k值时转换表的破解难度大幅度上升,但交流的双方都需要维护一张2^k大小的转换表,这不太现实.
因此,块密码使用函数来模拟转换表,例如:当k=64时,我们可以把64比特块划成8个子块,每个8比特块按照一张独特的k=8的转换表处理,然后将转换后的64比特按照一定规则打乱后再分为8个子块进行处理,进行多次循环.这种算法的密钥是8张k-8的转换表.
- 如果用 1 秒破解 56 比特 DES 的计算机 ( 就是说,每秒尝试所有 2^56个密钥 ) 来破解一个 128 比特的 AES 密钥 ,要用大约 149 万亿年的时间才有可能成功
Cipher-Block Chaining: 引入随机性
前面的块密码有一个缺陷: 如果有多个块中的明文内容相同,如"HTTP/1.1"这类常见的前缀词,那么将会得到相同的密文,从而被攻击者探测到并进行破解.
因此,我们可以在加密时引入随机数,如下图所示:

这样一来,即使明文相同,得到的密文也会不同,而密文相同时,得到的明文可能相同,破解难度大幅上升.
同时,实际应用中不太可能一个个传输随机数,故块密码使用密码块链接(Cipher-Block Chaining,CBC)来高效传输接收方所需的随机数,基本方法如下:
- 在发送数据之前,发送方生成一个随机的k比特串(对应k比特块加密),称为初始向量(Initialization Vector,IV).表示为c(0),并以明文方式发给接收方
- 对第一个块,发送方计算 c(1) = Ks(m(1) ⊕ c(0))后发送密文
- 对于第 i 个块,发送方根据 c(i) = Ks(m(i) ⊕ c(i-1)) 生成第 i 个密文块
非对称密钥
该类型的密钥有三个关键要素:
- 一个公开的加密算法和一个公开的解密算法
- 一个公开的密钥,称为公钥
- 只有通信中的某一方才知道的密钥,称为私钥
使用非对称密钥的通信过程如下:
发送者用加密算法和公钥来加密报文,接收者使用解密算法和私钥来解密报文.
但是,这种加密方式有不少问题:
- 如何保证加密后的报文不会被破解?
- 由于任何人都可以通过公钥加密报文后发送给接收方,如何确定发送者是可靠的?
尽管有很多算法可以解决上述问题,但RSA算法已经成为了非对称密钥的代名词.
RSA算法
为了生成RSA的公钥和私钥,接收方需要执行以下步骤:
- 选择两个大素数p和q,值越大就越难破解.
- 计算
n=pq和z=(p-1)(q-1) - 选择小于n的一个数e,使得e和z互质.
- 选择一个数d,满足
ed mod z = 1 - 那么接收方的公钥由(n,e)组成,私钥由(n,d)组成
通信过程如下:
- 发送方发送的报文以二进制形式表示为一个整数m,由于报文的位数有限,故m一般不会很大,在RSA算法中要求m < n,然后计算
c = m^e mod n,从而得到密文c,并交给接收方. - 为了解密c,接收方计算
m = c^d mod n,得到报文m.
举一个简单的例子:
- 接收方选择p=5和q=7,得到n=35和z=24,在5,7,11等与24互质的数中选择一个数,比如说5,那么由于
(5x29)-1可以被24整除(尽管5x5-1等取值也可以被24整除,但假设我们是随机取值取到了29),则d=29. - 发送方使用(35,5)加密报文,接收方使用(35,29)报文.
会话密钥
由于大数据的指数运算非常耗时,所以实际应用中我们可以把对称密钥和RSA结合在一起,用RSA来加密对称密钥算法中所需的密钥.这个被加密的密钥称为会话密钥(session key)
RSA原理
RSA运用了两个数论中的结论,这里不做说明,我们只需要知道通过(n,e)和(n,d)就足够进行加密和解密,攻击者如果想暴力破解,唯一的方法是:
- 试图从公开的 n 中分解出两个原始质数 p 和 q。
- 只有得到 p 和 q,才能计算出
z = (p-1)(q-1)。 - 通过
ed ≡ 1 mod z解出私钥 d。
RSA 的安全性依赖于这样的事实:目前没有已知的算法可以快速进行一个数的因数分解 ,这种情况下公开值 n 无法快速分解成素数 p 和 q。如果已知 p 和 q ,则给定公开值 e,
就很容易计算出秘密密钥 d 。 另一方面,不确定是否 存在 因数分解一个数的快速算法 , 从这种意义上来说,RSA 的安全性也不是确保的 。
报文完整性的鉴别和数字签名
接收方验证某条消息是否可靠,需要检测以下两个因素:
- 该报文来自可靠的发送方
- 该报文在途中没有被篡改
加密哈希函数(cryptographic hash function)
- hash function: 任意输入都会得到相同长度的输出
- cryptographic hash function: 在哈希函数的基础上,需要额外保证: 找到一个不同的输入得到相同的输出是基本不可能的.
从加密哈希函数的定义就可以看出来,攻击者一般来说是无法用其他报文伪造原报文的,从而保证该报文不会被篡改.
常用的加密哈希函数有以下几种:
| 算法 | 哈希长度 | 基本逻辑 | 安全性现状与建议 |
|---|---|---|---|
| MD5 | 128 位 | 将输入信息按 512 位分组,通过复杂的压缩函数进行多轮迭代处理,生成 128 位哈希值。 | ❌ 已破解,可人为制造碰撞。任何安全场景下都不应使用。 |
| SHA-1 | 160 位 | 逻辑与 MD5 类似,哈希值更长(160 位),处理步骤更复杂,安全性有所提升。 | ⚠️ 已不足够安全,存在理论碰撞攻击,Google 等已在 2017 年实现碰撞。应避免使用。 |
| SHA-2 | 224 / 256 / 384 / 512 位 | 采用 Merkle-Damgård 结构,更多轮次和更复杂的逻辑(如更多常量)。其中 SHA-256 和 SHA-512 最常用。 | ✅ 广泛认为安全,是替代 MD5 和 SHA-1 的首选标准。 |
| SHA-3 | 224 / 256 / 384 / 512 位 | 采用全新的 Keccak 海绵函数结构,与 SHA-2 设计思路完全不同,提供更高的安全冗余。 | ✅ 安全性高,可作为 SHA-2 的备选方案。 |
报文鉴别: 使用哈希函数和鉴别密钥
使用哈希函数,我们可以这样验证报文的完整性:
- Alice生成报文m并计算散列H(m).
- 然后Alice将H(m)附到报文m上,生成一个扩展报文(m, H(m)),并将该扩展报文发给Bob.
- Bob接到一个扩展报文(m, h)并计算H(m). 如果H(m) = h,Bob得出结论:一切正常.
但这种方法有一个问题: 攻击者可以声称他就是Alice,并将报文发送给Bob,这显然可以通过报文完整性的验证.
因此,我们还需要加入鉴别密钥(authentication key),即一个被双方共享的秘密比特串,在下述过程中我们将其称为s.
- Alice生成报文m,加入s生成m+s,并计算H(m+s),这被称为报文鉴别码(Message Authentication Code,MAC).
- 然后Alice将MAC附加到报文m上,生成扩展报文(m, H(m+s)),并将该扩展报文发送给Bob.
- Bob接收到一个扩展报文(m,h),由于知道s,计算出报文鉴别码H(m+s).如果H(m+s)=h,Bob得出结论:一切正常.
数字签名
有时候,我们会需要用一个数字签名(digital signature)来标识某个文件,这个数字签名一定是独一无二,不可篡改的,这样才可以保证能够分辨出该文件的所有者.
一种方法是发送方使用某一加密哈希函数取得报文的hash值,并用私钥加密该hash值;而在验证这个签名时,接收方只需要用公钥去解密这个hash值,如果计算结果与该文件的hash值一致,则证明报文的来源可靠
公钥认证
要让公钥密码生效,必须要证明你使用的公钥来源可靠,比如A和B通信时,A需要证明报文中的公钥确实来自B.
因此,我们需要通过CA(certification authority)来将公钥与特定实体(一个人,一台路由器,一个网站等)绑定.
CA有以下两个作用:
- 证实一个实体的身份.这需要该CA能够执行严格的身份验证,具有权威性,常见的CA有"Let’s Encrypt","DigiCert"等
- 将某个实体的身份与其公钥绑定为证书,由CA对这个证书进行数字签名
end-point authentication(端点鉴别)
前面的数字签名和公钥认证更像是被动被检测的,而这里提到的端点鉴别则是通信的某一方主动向另一方证明自己的身份.
应用层的安全服务: 安全电子邮件(过)
运输层的安全服务: TLS
TLS(Transport Layer Security)协议是由Netscape设计的安全协议-SSL(Secure Sockets Layer)协议-的升级版,所有的浏览器和服务器都支持该协议(看一下某个网站的URL,如果以https开始,就是启用了TLS),它有以下几个功能:
- 机密性: 攻击者可能截获购买者的订单并得到银行卡信息
- 完整性: 攻击者可能会修改购买者的订单地址或者购买数量
- 服务器鉴别: 证明这个网站是官方的,安全的
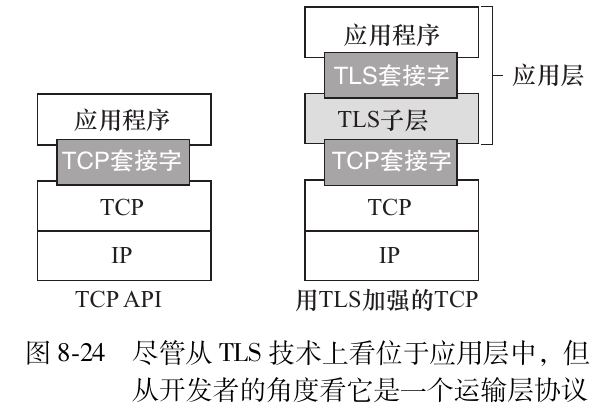
可以看到,TLS只在应用层进行了加密而已,并没有深入运输层
TLS Intro
先大致描述一下TLS的简化版本(称为类TLS),它具有三个阶段: 握手,密钥生成和传输数据
现在以客户B与服务器A之间的通信来举例说明
握手
在建立TCP连接后,B向服务器A发送一个hello报文,A在响应报文中返回该服务器的证书,里面包含了它的公钥.
由于该证书被某个CA证实过,B知道了这个公钥真的来自A,然后B生成一个主密钥(MS)用于此次TLS会话,使用A的公钥加密MS生成加密的主密钥(EMS),再发给服务器A,A再用私钥解密该EMS得到MS.
如此依赖,双方都知道了这次会话的主密钥MS.
密钥生成
事实上,出于安全性的考量,通信双方都会使用MS生成4个密钥:
- E_B: 从B发送到A时所用的加密密钥
- M_B: 从B发送到A时所用的HMAC密钥(用于验证报文完整性)
- E_A: 从A发送到B时所用的加密密钥
- M_A: 从A发送到B时所用的HMAC密钥
传输数据
TLS breaks the data stream into records, appends an HMAC to each record for integrity checking, and then encrypts the record + HMAC.
比如说B要发送数据,它需要将数据流分割为一个个record,为每个record附上HMAC,然后使用M_B加密这个record+HMAC包后发送出去.
事实上,这个HMAC中海含有这次发送的record所属的序号,从而保证攻击者不会打乱record的顺序.
record的结构
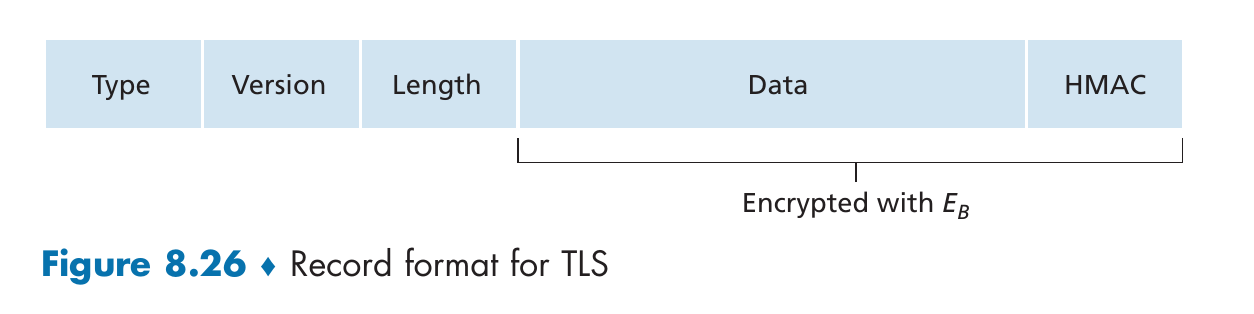
- Type字段: 判断这是握手报文还是传输数据的报文,也用于关闭TLS连接
对于TLS更为精确的描述
握手阶段
TLS不强制通信双方使用特定的加密算法,而是允许双方在TLS会话开始时就统一决定加密算法,真实的步骤如下:
- 客户发送它支持的密码算法的列表和它选取的不重数(在本次会话中不会第二次出现的数字)
- 服务器从列表中选择一个对称密钥算法,一种非对称密钥算法和一种HMAC算法,它把这些选择联通证书和另一个不重数发给服务器
- 客户验证证书后提取服务器的公钥,生成PMS(Pre-Master Secret),用公钥加密该PMS后发送给服务器.
- 客户和服务器根据PMS和各自的不重数得到上述的四种密钥.
- 双方发送一段用新生成的密钥加密过的握手信息摘要,用于验证双方计算出的密钥是否一致,以及握手过程是否被篡改
你可能想知道在步骤 1 和步骤 2 中存在**不重数(Nonce)**的原因。序号不足以防止报文段重放攻击吗?答案是肯定的,但它们并不只是防止“连接重放攻击”
假设 Trudy 嗅探了 Alice 和 Bob 之间的所有报文。第二天,Trudy 冒充 Bob 并向 Alice 发送正好是前一天 Bob 向 Alice 发送的相同的报文序列。
- 若未使用不重数:Alice 将以前一天发送的完全相同的序列报文进行响应。由于接收到的每个报文都能通过完整性检查,Alice 不会怀疑任何异常。如果 Alice 是一个电子商务服务器,她将认为 Bob 正在进行第二次相同的订购。
- 若使用不重数:Alice 将对每个 TCP 会话发送不同的不重数,使得两天的加密密钥完全不同。当 Alice 接收到 Trudy 重放的 TLS 记录时,由于密钥不匹配,该记录将无法通过完整性检查,假冒的事务便不会成功。
连接终止
如果仅通过TCP连接来终止TLS会话的话,攻击者可以通过截断攻击(truncation attack)来提前结束会话,也就是说他可以在会话中发送一个TCP FIN报文,从而让用户不能获取完整的信息.
因此,我们可以用最后一个record指示终止会话.
网络层的安全服务: IPsec(过)
补充: 有线网络的安全服务
有线网络不提供安全服务,因为链路通信是很难被攻击和篡改的,只需依靠上层的安全服务即可.
无线网络的安全服务(待补充)
防火墙和入侵检测系统(待补充)
总结
显然,有这么多的防护措施,普通的cracker是很难通过截获IP数据报的形式来进行攻击的,相反,通过恶意软件(病毒,木马等)可以很轻易的跨越多层封锁,进入最薄弱的环节-主机-中,但这部分就不是网络通信所能负责的范畴了.
ppt概念补充
Intro
OSI七层协议
事实上,OSI协议的前三层对应了本书中的应用层,后面的都是一一对应的
Modem v.s. Router
Modem (调制解调器) 的本质是信号转换器。由于计算机内部处理的是二进制数字信号(Binary stream),而广域网传输介质(如电话线、光纤)传输的是模拟信号(Sinusoidal waves),Modem 负责将数字信号调制为模拟信号发出,并将接收到的模拟信号解调回数字信号。如果家中只有一个上网设备且不需要防火墙等功能,理论上仅需 Modem 即可拨号上网。
Circuit Switching and Packet Switching
Circuit Switching (电路交换)
核心流程:
- 建立电路 (Establishment):在发送数据前,必须先预留一条端到端的物理路径。
- 信息传输 (Transfer):数据(模拟或数字)沿专用路径实时流动。
- 电路拆除 (Termination):释放沿途占用的所有资源。
关键特性:
- 优势:由于资源独占,数据传输速率恒定、带宽有保障,且数据严格按序到达,对用户而言网络是“透明”的。
- 劣势:存在明显的拨号/建立延迟。资源利用率低,即便不传输数据,信道依然被占用,无法分配给其他用户。
- 复用方式:通常通过多路复用 (Multiplexing) 将物理链路划分为多个子信道
Packet Switching (分组交换)
核心流程:
- 分组化 (Packetization):将长报文拆分为带有首部(源地址、目的地址、校验码)的小数据包。
- 存储转发 (Store-and-forward):路由器必须接收完一个分组的所有比特后,才能开始向下一跳转发。
关键特性:
- 优势:
- 带宽利用率高:单个分组可以使用链路的全带宽,资源按需分配,支持更多用户接入。
- 应对突发流量 (Bursty Data):互联网流量通常是爆发式的,分组交换通过路由器内的缓冲区 (Buffer) 吸收临时流量峰值。
- 劣势:资源竞争可能导致拥塞和丢包;路由算法复杂;分组可能乱序到达目的地。
核心对比总结
| 特性 | 电路交换 (Circuit) | 分组交换 (Packet) |
|---|---|---|
| 资源分配 | 预先静态分配(独占) | 动态按需分配(共享) |
| 延迟来源 | 建立连接延迟 | 存储转发延迟、排队延迟 |
| 性能表现 | 稳定、无抖动、带宽保证 | 可能拥塞、有抖动、高并发 |
| 典型应用 | 传统电话网 (PSTN) | 现代计算机网络 (Internet) |
物理层
outline
- Bandwidth (带宽) and Data Rate
- Modulation (调制) of a Signal (ASK, PSK, QPSK, QAM)
- Medium and Transmission (传输)
- Multiplexing (复用) (FDMA, TDMA, CDMA)
Bandwidth (带宽) and Data Rate
- Bandwidth: 单位时间内从一个节点传送到另一个节点的数据量
奈奎斯特采样定理 (Nyquist Sampling Theorem)
核心物理含义
在进行模数转换(将连续信号变为数字点)时,如果模拟信号包含的最高频率为 Hz,那么每秒钟至少需要进行 次采样(即采样频率 ),才能通过这些采样点无失真地重建原始信号。这个最小值 被称为奈奎斯特速率。
采样频率与波形还原
为了识别一个周期的波形,数学上至少需要记录其一个波峰和一个波谷。如果采样率低于 ,采样点分布太稀疏,捕捉到的数据点在还原时会连成一个错误的低频波形,这种现象称为混叠 (Aliasing)。
混叠 (Aliasing) 的直观理解
当采样频率不足时,高频信号会“伪装”成低频信号。
- 视觉现象:在电影(每秒 24 帧采样)中看到快速转动的车轮时,车轮似乎在缓慢倒转,这就是典型的视觉混叠。
- 音频后果:若采样率过低,录入的高音会变成诡异的低频杂音,且这种失真是永久性的,无法通过软件修复。
工程应用实例
- CD 音质:人耳听觉上限约为 。根据定理,采样率必须大于 。CD 标准采用 ,正是为了确保完全覆盖人耳带宽并留出滤过缓冲带。
- 通信带宽:在带通信号传输中,该定理限制了在给定频率范围内可以传输的最大符号速率,是数字通信设计的底层物理约束。
信道容量与编码定理 (Channel Capacity & Coding Theorems)
奈奎斯特准则 (Nyquist Theorem) —— 无噪声信道
在理想的、没有噪声的信道中,由于信号在传输时存在码间串扰(带宽限制了信号的变化速率),最大数据传输速率由带宽和信号电平数(量化等级)决定。
- 公式:$$R_{max} = 2 \times BW \times \log_2 V \text{ bps}$$
- 参数含义:
- :信道带宽(Hz)。
- :信号的离散电平数(量化等级)。
- 物理本质:在无噪声情况下,理论上可以通过无限增加量化电平数 来提升速率,但受限于实际硬件对电平分辨的精确度。
香农定理 (Shannon’s Theorem) —— 有噪声信道
在存在随机热噪声的实际信道中,由于噪声会掩盖信号的电平细节,最大可靠传输速率(信道容量)存在一个物理极限。
- 公式:$$C = BW \times \log_2 (1 + \frac{S}{N}) \text{ bps}$$
- 参数含义:
- :信道容量,即该信道能实现的理论最大信息传输速率。
- :信噪比(SNR),信号功率与噪声功率的比值。
- 物理本质:噪声决定了我们能区分的最小信号电平差。即使无限增加发送电平 ,如果电平差小于噪声强度 ,接收方也无法识别。因此,带宽和信噪比共同限定了信息交换的上限。
信噪比与分贝 (SNR in Decibels)
在工程实践中,信噪比通常跨越多个数量级,因此常使用对数单位分贝 (dB) 来表示。
- 分贝换算公式:$$SNR(dB) = 10 \times \log_{10} (\frac{S}{N})$$
- 典型值参考:
- 如果 ,则 。
- 如果 ,则 。
- 如果 (信号是噪声的两倍),则 。
核心逻辑总结
- 奈奎斯特告诉我们:由于带宽限制,采样率有上限(不能跑太快,否则波形会糊)。
- 香农告诉我们:由于噪声存在,信息的精细度有上限(不能分太细,否则分不清信号和噪声)。
- 实际应用:在设计网络系统(如 5G 或 Wi-Fi)时,通常会同时计算这两个值,取其中的较小者作为实际物理层的理论瓶颈。
Modulation
专业名词(即使前面提过也会放在这里)
- adapter: 适配器,主机与特定网络连接的硬件接口,俗称网卡.
- Internet: 是由无数个使用 TCP/IP 协议族 相互连接的计算机网络,物理上通过路由器和交换机在全球范围内实现数据交换与资源共享的网际网路。
- packet(分组): 在特定层传输的数据包,从应用层,运输层,网络层,到链路层,每经过一层增加一个头部修饰
- MAC: Medium Access Control,介质访问控制协议
- ISP: Internet Service Provider
- NAT: Network Address Translation
- WAN: Wide Area Network - 广域网
- LAN: Local Area Network - 局域网
- SDN: Software Defined Networking,通过软件管理路由转发
- CIDR: Classless Inter-Domain Routing,无类别域间路由,是一个用于给用户分配IP地址的方法
- CSMA: Carrier Sense Multiple Access,发送信号前先监听,从而判断是否要在这个时候发送信号
- 全双工(full-duplex): 可以同时接收和发送数据
- 半双工(half-duplex): 同一时刻要么接收,要么发送,不能同时进行
实战
URL解析
如何给一个新房联网
网站证书
备案流程
wiki
个人网站备案需要准备:1份网站负责人的身份证件彩色扫描件或复印件;负责人的半身彩色照片(带接入商名称背景);网站所使用的独立域名注册证书复印件(加盖公章);主办单位所在地的详细联系方式;填写《信息安全管理协议》;填写《真实性核验单》。根据相关行政法规,所有在中国境内的互联网信息服务提供者都应完成备案登记手续方可开办,未按规定备案的不得开展服务。
2005年2月8日,原中华人民共和国信息产业部部长王绪东签发《非经营性互联网信息服务备案管理办法》,并于3月20日正式实施。该办法要求从事非经营性互联网信息服务的网站进行备案登记,否则将予以关站、罚款等处理。
根据《互联网信息服务管理办法》,提供非经营性互联网信息服务需办理备案,而办理备案的前提是使用中国境内服务商提供的内地机房IP
事实上,在中国内地,合规运行网站需要两个核心要素:域名实名认证和ICP备案。
- 后缀限制:并非所有域名后缀都能备案。只有在工信部正式批复的顶级域名列表中的后缀(如 .com, .cn, .net 等)才允许备案。如果你使用 .io, .ai 等部分未批复后缀,即便服务器在国内也无法通过备案。
- 注册商要求:办理 ICP 备案的域名,其注册商必须在中国内地经过许可。如果你的域名是在 Namecheap、GoDaddy 或 Google Domains 注册的,必须先将域名转入国内注册商(如万网、新网),才能提交备案申请。
(补充): 事实上,所有的备案都是通过第三方的,小程序上线需要通过微信开发者平台备案;网站上线需要通过阿里云,腾讯云备案…
平台初审(一般需要1-2个工作日)通过后,再由平台提交给工信部审核(时间范围不确定,但一般不短),审核通过后会发短信提醒你.
这还没完,当你通过备案后,需要再进行公安联网备案,并提交审核,一般为2-3个工作日.
瑟瑟发抖…




