bfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int maxConnectedComponent (Graph& g) int n = g.n; vector<bool > visited (n, false ) ; int max_size = 0 ; for (int i = 0 ; i < n; ++i) { if (!visited[i]) { int size = 0 ; vector<int > q = {i}; visited[i] = true ; for (int j = 0 ; j < q.size (); ++j) { int u = q[j]; ++size; for (int v : g.adj[u]) { if (!visited[v]) { visited[v] = true ; q.push_back (v); } } } max_size = max (max_size, size); } } return max_size; }
dfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <vector> using namespace std;int dfs (int u, const vector<vector<int >>& adj, vector<bool >& visited) visited[u] = true ; int cnt = 1 ; for (int v : adj[u]) { if (!visited[v]) { cnt += dfs (v, adj, visited); } } return cnt; } int maxConnectedComponent (int n, const vector<vector<int >>& adj) vector<bool > visited (n, false ) ; int maxSize = 0 ; for (int i = 0 ; i < n; ++i) { if (!visited[i]) { int size = dfs (i, adj, visited); if (size > maxSize) maxSize = size; } } return maxSize; }
用visited数组来保证取到所有的连通分量,从而找到最大连通分量
特点:使用队列,可以得到最短路径,无论是否会重复访问,都能一个节点一直是最优状态.以大佬的八数码解法为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <map> #include <queue> #include <algorithm> #define ll long long using namespace std;const ll dx[]={-1 ,0 ,0 ,1 },dy[]={0 ,-1 ,1 ,0 };ll n; int main () cin>>n; queue<ll> q; q.push (n); map<ll,ll> m; m[n]=0 ; while (!q.empty ()) { int u=q.front (); int c[3 ][3 ],f=0 ,g=0 ,n=u;q.pop (); if (u==123804765 )break ; for (ll i=2 ;i>=0 ;i--) for (ll j=2 ;j>=0 ;j--) { c[i][j]=n%10 ,n/=10 ; if (!c[i][j])f=i,g=j; } for (ll i=0 ;i<4 ;i++) { ll nx=f+dx[i],ny=g+dy[i],ns=0 ; if (nx<0 ||ny<0 ||nx>2 ||ny>2 )continue ; swap (c[nx][ny],c[f][g]); for (ll i=0 ;i<3 ;i++) for (ll j=0 ;j<3 ;j++)ns=ns*10 +c[i][j]; if (!m.count (ns)) { m[ns]=m[u]+1 ; q.push (ns); } swap (c[nx][ny],c[f][g]); } } cout<<m[123804765 ]<<endl; return 0 ; }
特点:有时候会使用栈,可以得到方案总数,有次数要求时使用这个方法.以最经典的八皇后问题为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;const int N = 30 ;int n, cnt = 0 , sum = 0 ;int col[N], d1[N], d2[N]; int pos[N]; void dfs (int row) if (row > n) { if (cnt < 3 ) { for (int i = 1 ; i <= n; i++) cout << pos[i] << " " ; cout << "\n" ; } cnt++; sum++; return ; } for (int c = 1 ; c <= n; c++) { if (col[c] || d1[row + c] || d2[row - c + n]) continue ; col[c] = d1[row + c] = d2[row - c + n] = 1 ; pos[row] = c; dfs (row + 1 ); col[c] = d1[row + c] = d2[row - c + n] = 0 ; } } int main () cin >> n; dfs (1 ); cout << sum; return 0 ; }
可以注意到,无论是dfs还是bfs,重点是将当前状态判定后再重置状态,保证后来的方案不会受到这次修改影响.
dfs有两种结构
1 2 3 4 5 6 7 8 void dfs1 (int l, int r, ll sum) if (l > r) { s1. push_back (sum); return ; } dfs1 (l+1 , r, sum); dfs1 (l+1 , r, sum + a[l]); }
这种就像背包问题,一般都能用动态规划解决,每一步都只有两个分支
1 2 3 4 5 6 7 8 void dfs (int n) for (int c = 1 ; c <= n; c++) { dfs (x + 1 ); } } 在每一步都有多个选择
(突然发现下面这部分期末不考算法,懒得挂代码上来了)
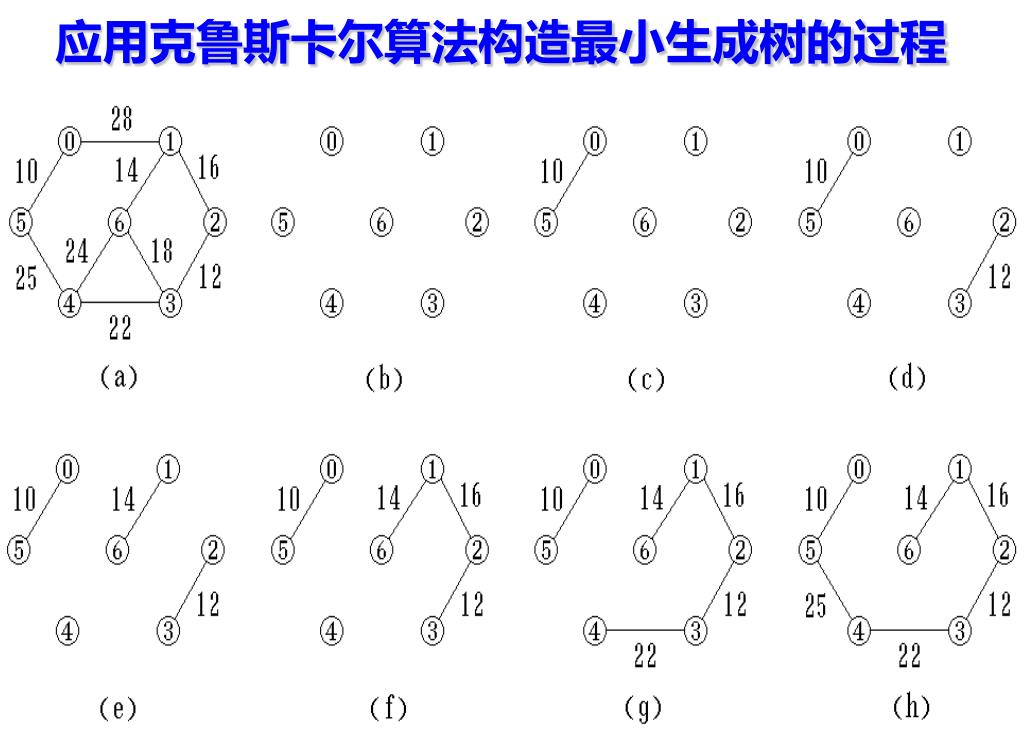
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <bits/stdc++.h> using namespace std;struct Edge { int u, v, w; bool operator < (const Edge& other) const { return w < other.w; } }; const int MAXN = 5005 ;int fa[MAXN];int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } void unite (int x, int y) x = find (x); y = find (y); if (x != y) fa[x] = y; } int main () ios::sync_with_stdio (false ); cin.tie (nullptr ); int n, m; cin >> n >> m; vector<Edge> e (m) ; for (int i = 0 ; i < m; i++){ cin >> e[i].u >> e[i].v >> e[i].w; } for (int i = 1 ; i <= n; i++) fa[i] = i; sort (e.begin (), e.end ()); long long ans = 0 ; int cnt = 0 ; for (auto &ed : e){ if (find (ed.u) != find (ed.v)){ unite (ed.u, ed.v); ans += ed.w; cnt++; if (cnt == n - 1 ) break ; } } if (cnt != n - 1 ){ cout << "orz\n" ; } else { cout << ans << "\n" ; } return 0 ; }
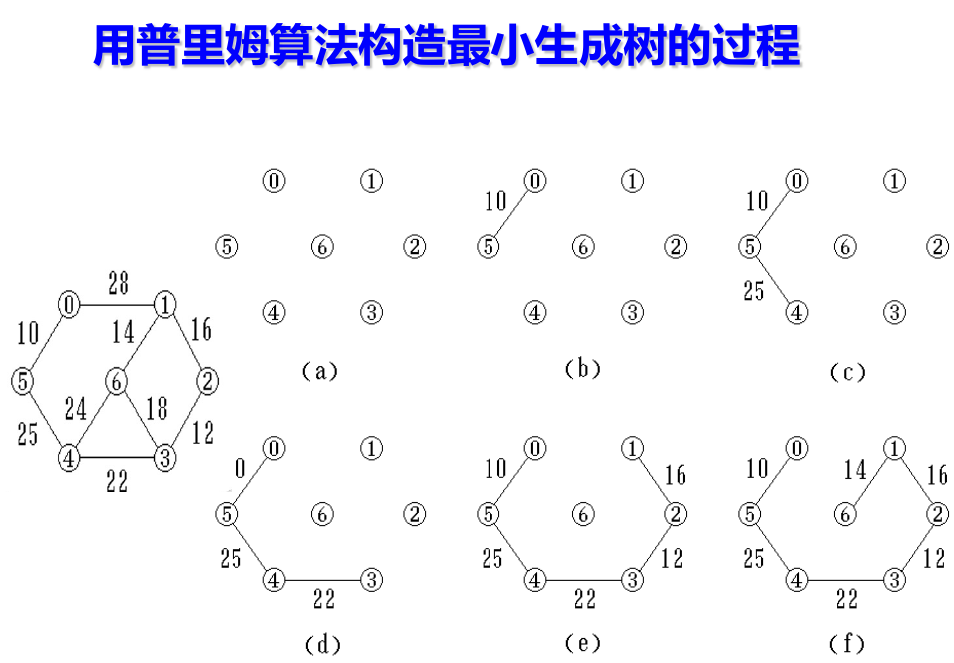
重点是用避圈法,难点是确保不形成圈,
点击展开 Kruskal 最小生成树演示
下面是 Kruskal 最小生成树演示:
下一步
重置
当前 MST 总权值: 0
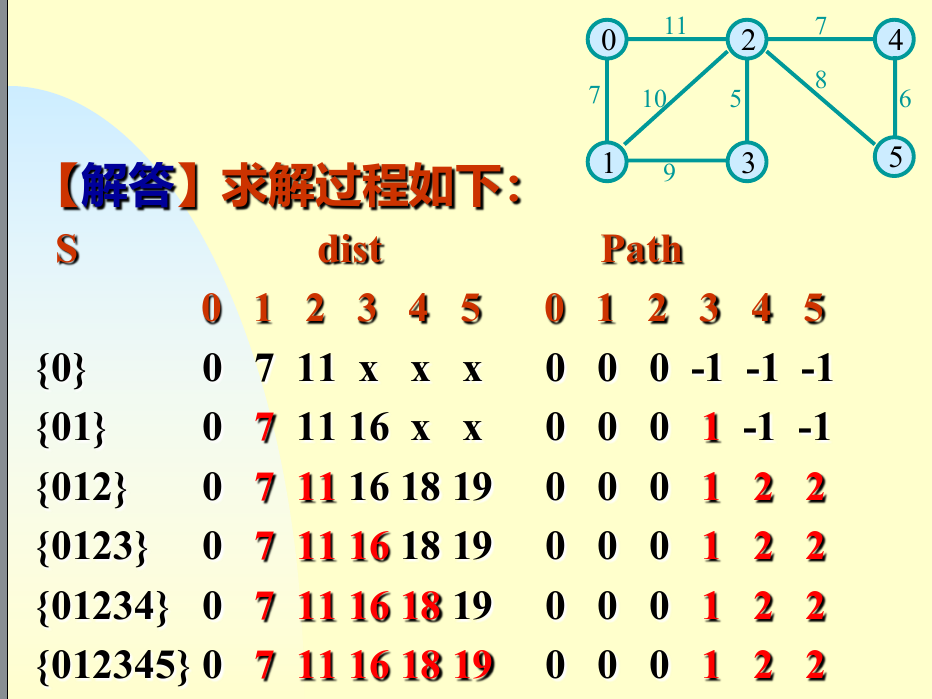
P1194 的时候脑袋卡壳了,怎么都想不出如何得到和更新当前的最小代价
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <bits/stdc++.h> using namespace std;const int MAX = 505 ;const int INF = 1e9 ;int a, b;int k[MAX][MAX];int dist[MAX];bool vis[MAX];int main () cin >> a >> b; for (int i = 1 ; i <= b; i++) { for (int j = 1 ; j <= b; j++) { cin >> k[i][j]; if (k[i][j] > a||k[i][j]==0 ) k[i][j] = a; } } for (int i = 1 ; i <= b; i++) { dist[i] = a; vis[i] = false ; } int ans = 0 ; for (int i = 1 ; i <= b; i++) { int u = -1 ; int mn = INF; for (int j = 1 ; j <= b; j++) { if (!vis[j] && dist[j] < mn) { mn = dist[j]; u = j; } } vis[u] = true ; ans += dist[u]; for (int v = 1 ; v <= b; v++) { if (!vis[v]) { dist[v] = min (dist[v], k[u][v]); } } } cout << ans << endl; return 0 ; }
确实好理解不少,可以看出来prim是点驱动的,每次找到代价最小的点,起点任意选择;
极好的证明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1. 归纳基础:k = 1 时,T 中只包含起点 s,dist[s] = short[s] = 0,因此命题在 k = 1 时成立。 2. 归纳假设:假设命题在第 k 步时成立,即 T 中所有节点的 dist 值都是最短路径长度。 3. 归纳步骤:证明第 k+1 步时命题也成立: 设第 k+1 步选择的节点为 v(v 是未访问节点中 dist 值最小的);v 与集合 T 中的某个节点 u 相连; 需要证明:dist[v] = short[v]。 这里用反证法: 假设存在一条从起点 s 到 v 的路径 P,其长度是 short[v],且 short[v] < dist[v]。 由于起点 s 在集合 T 中,而终点 v 不在集合 T 中,路径 P 必然至少经过一个集合 T 中的节点(除起点外)。因为起点 s 到任何不在 T 中节点的距离,都是通过 T 中的节点来计算和更新的。 设路径 P 上最后一个在集合 T 中的节点为 last,之后经过未访问集合中的节点 y 最终到达 v;下面看路径 P 的长度计算: short[v] = dist[last] + distance[last,y] + distance[y,v] // 路径 P 的长度 ≥ dist[y] + distance[y,v] // 根据 dist[y] 的更新规则 ≥ dist[v] 要理解下面这两个点才能明白上面的推导: 首先由归纳假设,到达 last 的距离 dist[last] 是最短的;对于节点 y,根据 Dijkstra 算法的更新规则:dist[y] ≤ dist[last] + distance[last,y] 又因为算法第 k+1 步选择了 v 作为当前最小距离节点,所以 dist[v] ≤ dist[y] + distance[y,v]。 于是就推导出 short[v] >= dist[v],这和我们的假设 short[v] < dist[v] 矛盾,因此假设不成立,dist[v] 就是从起点到 v 的最短路径长度。这也证明了算法每一步选择的节点的距离都是最短路径长度。
这个归纳证明直接讲明白了算法的核心步骤,每次取未vis的最短路后更新其他未vis的最短路,直到遍历完所有节点就可以了
重点是确认初始状态,之后将所有点遍历作为中间点更新最短路径,写一个三重循环,可得到任意两点之间的最短路径.
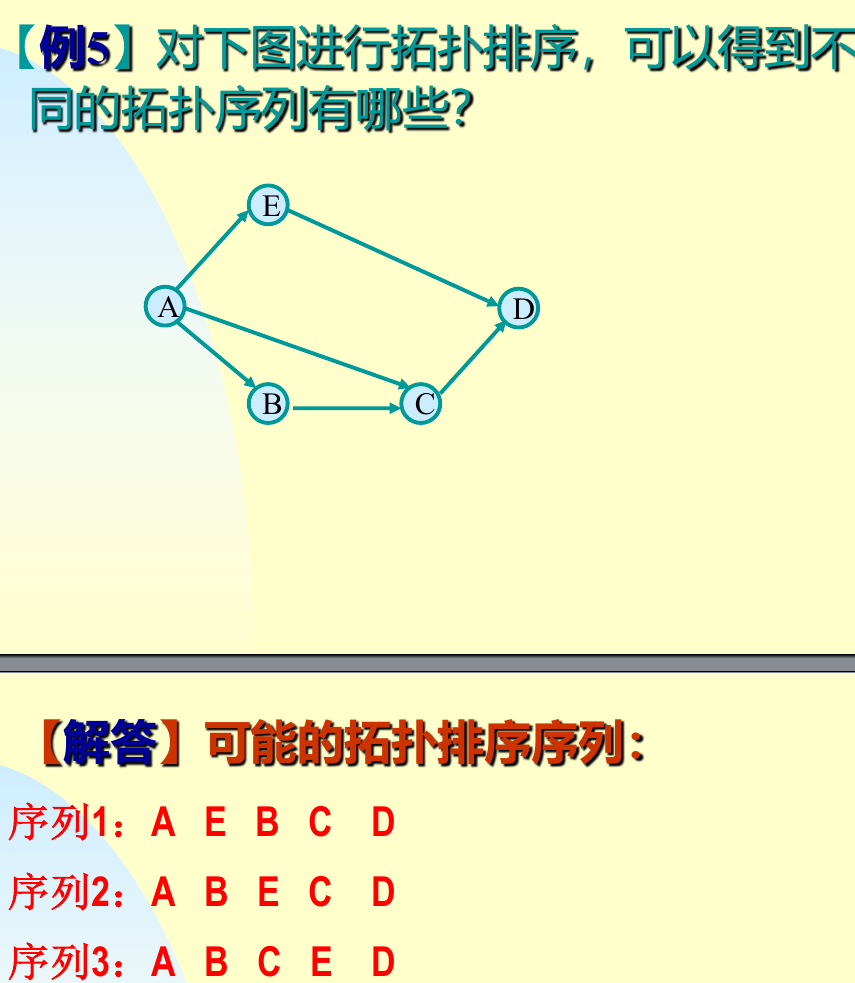
算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void Graph::TopologicalSort () int top = -1 ; for (int i = 0 ; i < n; i++) { if (count[i] == 0 ) { count[i] = top; top = i; } } for (int i = 0 ; i < n; i++) { if (top == -1 ) { cout << "图中存在环路" << endl; return ; } int j = top; top = count[top]; cout << j << " " ; for (Edge<float >* l = NodeTable[j].adj; l != nullptr ; l = l->link) { int k = l->dest; if (--count[k] == 0 ) { count[k] = top; top = k; } } } cout << endl; }
看得出来教材已经扣到不愿意用队列了,每次更新的时候把原栈顶top指针存入最新入栈的count数组对应位置,然后将top指针指向这个位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void Graph::TopologicalSort () std::queue<int > q; int count_processed = 0 ; for (int i = 0 ; i < n; i++) { if (count[i] == 0 ) { q.push (i); } } while (!q.empty ()) { int j = q.front (); q.pop (); cout << j << " " ; count_processed++; for (Edge<float >* l = NodeTable[j].adj; l != nullptr ; l = l->link) { int k = l->dest; if (--count[k] == 0 ) { q.push (k); } } } if (count_processed < n) { cout << "\n网络中有回路(有向环)" << endl; } }
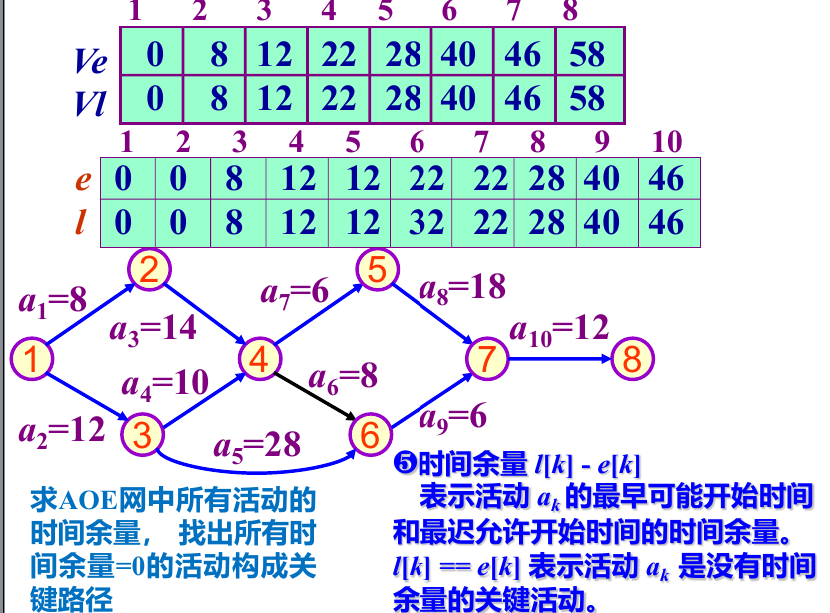
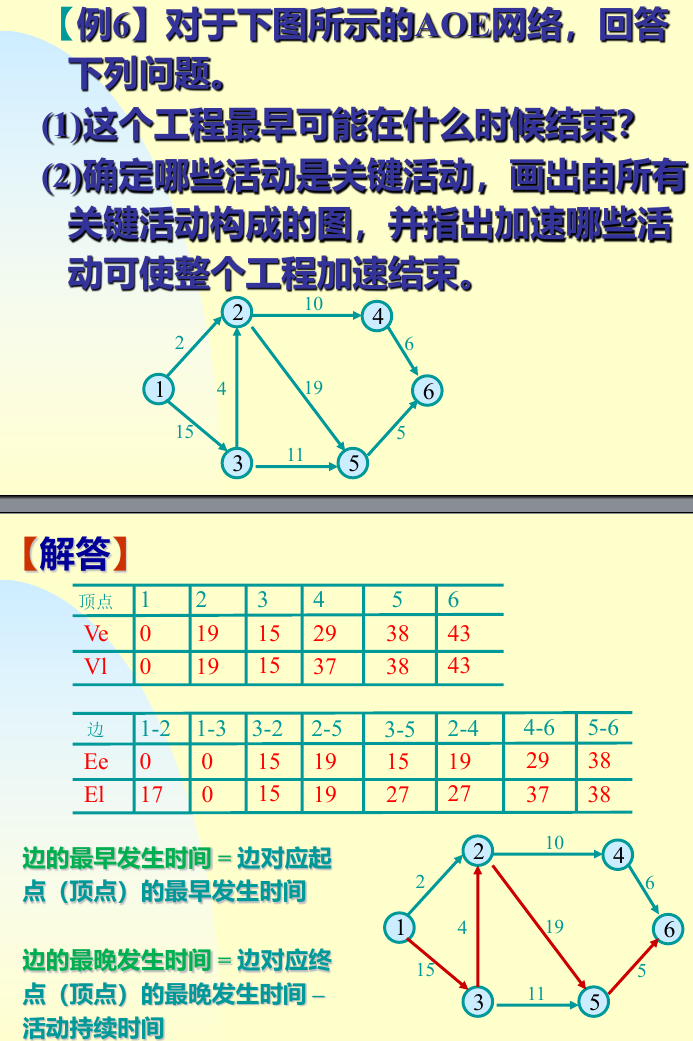
讲的最清楚
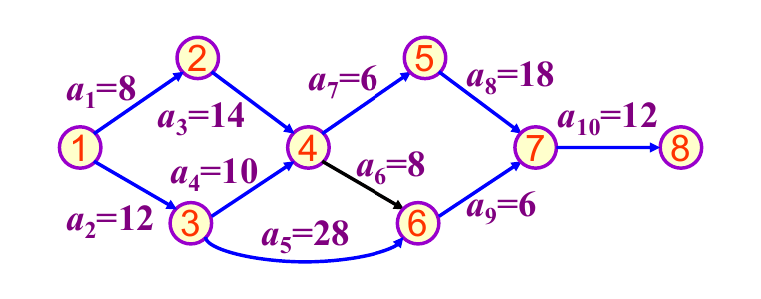
关键路径所经过的结点的最迟发生时间和最早发生时间是一致的。如果不好理解的话,打个比方,比如小组作业中,有个同学做的特别慢(关键路径)。所有人同时开始做,其他组员都做完了,他还没有做完,而小组只有等所有人都做完才能上交作品,那么完成小组作业所需的总时间就取决于他的时间。为了不拖后腿,对于他来说,他所做的n个事情就没有“最早什么时候做”“最晚什么时候做”这个说法,而是要马不停蹄地一直做。其他组员则可以选择早一点或晚一点做,只要不比他(关键路径)慢就行。https://blog.csdn.net/ROBOT_a/article/details/147289874
这个解释非常妙,让我一下看懂了.
关键是先求每个节点的最早发生时间和最迟发生时间,
注意到递推的时候应该按照拓扑排序和逆拓扑排序 的顺序来进行,才能保证不遗漏点和边