
重构 改善既有代码的设计
ch1: Intro
如果你要给程序添加一个特性,但发现代码因缺乏良好的结构而不易于进行更改,那就先重构那个程序,使其比较容易添加该特性,然后再添加该特性。
无论每次重构多么简单,养成重构后即运行测试的习惯非常重要。 犯错误是很容易的——至少我知道我是很容易犯错的。做完一次修改就运行测试,这样在我真的犯了错时,只需要考虑一个很小的改动范围,这使得查错与修复问题易如反掌。 这就是重构过程的精髓所在:小步修改,每次修改后就运行测试。如果我改动了太多东西,犯错时就可能陷入麻烦的调试,并为此耗费大把时间。小步修改,以及它带来的频繁反馈,正是防止混乱的关键。
- 这章用了巨量的篇幅来修改一个几十行的js代码,从而说明了一个良好的早期架构是有多么的重要,一旦那些架构混乱的项目开始变得复杂,就算是神仙来了也未必能够轻易看懂并重构
关键点: 尽可能多的使用OOP,通过多态,继承,接口来实现代码复用和类型统一;通过将复杂表达式拆分为工具函数并择合适的名字来增强代码的可读性
ch2: 重构的原则
重构有两种词性,一种是动词,一种是名词:
- 重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
- 重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
如果我看见一块凌乱的代码,但并不需要修改它,那么我就不需要重构它。如果丑陋的代码能被隐藏在一个 API 之下,我就可以容忍它继续保持丑陋。只有当我需要理解其工作原理时,对其进行重构才有价值。 另一种情况是,如果重写比重构还容易,就别重构了。这是个困难的决定。如果不花一点儿时间尝试,往往很难真实了解重构一块代码的难度。决定到底应该重构还是重写,需要良好的判断力与丰富的经验,我无法给出一条简单的建议。
如果一支团队想要重构,那么每个团队成员都需要掌握重构技能,能在需要时开展重构,而不会干扰其他人的工作。这也是我鼓励持续集成的原因:有了 CI,每个成员的重构都能快速分享给其他同事,不会发生这边在调用一个接口那边却已把这个接口删掉的情况;如果一次重构会影响别人的工作,我们很快就会知道。自测试的代码也是持续集成的关键环节,所以这三大实践——自测试代码、持续集成、重构——彼此之间有着很强的协同效应。
ch3: 代码的坏味道
需要重构的特征有以下几个:
- 难以捉摸的命名
- 重复的代码段
- 函数太长: 将值得用注释说明的部分拆分成函数
- 过长参数列表: 使用类来传入参数
- 全局数据: 用函数或者类来封装这个全局数据,尽量控制其作用域
- 可变数据: 如果一个数据有不同的用途,最好将它按照用途分成不同的类
- 模块边界不清晰
- 修改一次需要在多个地方更改
ch4: 构筑测试体系
确保所有测试都完全自动化,让它们检查自己的测试结果。
频繁地运行测试。对于你正在处理的代码,与其对应的测试至少每隔几分钟就要运行一次,每天至少运行一次所有的测试。
考虑可能出错的边界条件,把测试火力集中在那儿。
每当你收到 bug 报告,请先写一个单元测试来暴露这个 bug。
ch6: 第一组
提炼函数(Extract Function)
用例
| |
对于“何时应该把代码放进独立的函数”这个问题,我曾经听过多种不同的意见。有的观点从代码的长度考虑,认为一个函数应该能在一屏中显示。有的观点从复用的角度考虑,认为只要被用过不止一次的代码,就应该单独放进一个函数;只用过一次的代码则保持内联(inline)的状态。但我认为最合理的观点是“将意图与实现分开”:如果你需要花时间浏览一段代码才能弄清它到底在干什么,那么就应该将其提炼到一个函数中,并根据它所做的事为其命名。以后再读到这段代码时,你一眼就能看到函数的用途,大多数时候根本不需要关心函数如何达成其用途(这是函数体内干的事)。
如果想要提炼的代码非常简单,例如只是一个函数调用,只要新函数的名称能够以更好的方式昭示代码意图,我还是会提炼它;但如果想不出一个更有意义的名称,这就是一个信号,可能我不应该提炼这块代码。不过,我不一定非得马上想出最好的名字,有时在提炼的过程中好的名字才会出现。有时我会提炼一个函数,尝试使用它,然后发现不太合适,再把它内联回去,这完全没问题。只要在这个过程中学到了东西,我的时间就没有白费。
- “如果需要返回的变量不止一个,又该怎么办呢?”
有几种选择。最好的选择通常是:挑选另一块代码来提炼。我比较喜欢让每个函数都只返回一个值,所以我会安排多个函数,用以返回多个值。如果真的有必要提炼一个函数并返回多个值,可以构造并返回一个记录对象—不过通常更好的办法还是回过头来重新处理局部变量
内联函数(Inline Function)
这里的内联指的是将不必要的中间层删除,从而让函数更加清晰
| |
- 这显然与前面说的提炼函数正好相反,从而说明重构并不是一个简单的活儿,你不好判断加入函数和删除函数这两种做法哪一种会让代码更清晰
break&总结
后面的部分都是一些具体用例了,大部分内容都需要真正去实践才能体会,所以就不建议去看了.
提炼一下本书的精华:
- 软件的初步架构需要是合理的,工程化的,否则后期的重构难度甚至超过推翻重写
- 重构一般是一次一小步进行的,如果你的重构会让项目暂时无法运行,说明你做的不是重构
- 重构的方法有以下几种:
- 提炼/删除 函数
- 用类来存放函数和变量
- 去除不必要的全局变量
- 改一个好的名字
- 重构与添加新功能可以是同时进行的
程序员自我修养
- 讲的很深,可惜的是逻辑比较混乱,如果能再版后重构一下就真的是神书了 GitHub下载链接
OUTLINE
- 简介
- 编译和链接
- 目标文件里有什么
- 静态链接
- windows PE/COFF
- exe的装载与进程
- 动态链接
- Linux的共享库
- Windows中的动态链接
- 内存
- 运行库
- 系统调用与API
- 运行库的实现
可以很明显的看出来,这本书主要涉及的是C语言程序经过编译与链接后装载的过程.
编译和链接
程序运行的过程
当我们使用GCC编译Hello World程序时,只需要这样写:
| |
上述过程可以分解为4个步骤:
- 预处理(Preprocessing)
- 编译(Compilation)
- 汇编(Assembly)
- 链接(Linking)
预处理
c文件和h文件会被预处理成.i文件,cpp文件和hpp文件会被预处理为.ii文件.
- 对应的命令为
gcc -E hello.c -o a.i该阶段主要处理源代码中以"#“打头的预编译指令,如’#include’,’#define’等,主要运行过程如下:
- 将所有的”#define"删除,并展开所有的宏定义,比如,将含有"#define PI 3.14"的文件中的所有PI替换为3.14
- 处理所有的条件预编译指令,如"#if",“endif"等
- 处理”#include",将被包含的文件插入到文件中该预编译指令所在的行,该过程是递归执行的
- 删除所有的注释"//“和”/* */"
- 添加行号和文件名标识,如 " #2 “hello.c” 2 “,这就是我们在程序报错的时候看到的那些行号和文件名的来历,至于行尾的2,是一个给编译器看的标志位
- 保留所有的”#pragma"指令
因此,经过预处理后的.i文件不包含任何宏定义,包含的文件也被插入到.i文件中
编译
对.i文件进行一系列词法分析,语法分析,语义分析和优化,生成相应的汇编代码文件.
- 对应的命令为
gcc -S hello.i -o hello.s
汇编
根据汇编代码构建目标文件
- 对应的命令为
gcc -c hello.s -o hello.o- 或者一步完成:
gcc -c hello.c -o hello.o
- 或者一步完成:
链接
| |
可以看到需要链接一堆文件才可以得到最终的可执行文件
编译的详细原理
下面我们来以一段简单的c语言代码为例来分析编译的全过程:
| |
词法分析
源代码被输入到扫描器(Scanner),产生一系列记号:关键字,标识符,数字,字符串和特殊符号(加号,等号)等.
语法分析
语法分析器(Grammar Parser)对扫描器产生的记号进行语法分析,产生由表达式组成的语法树(Syntax Tree)
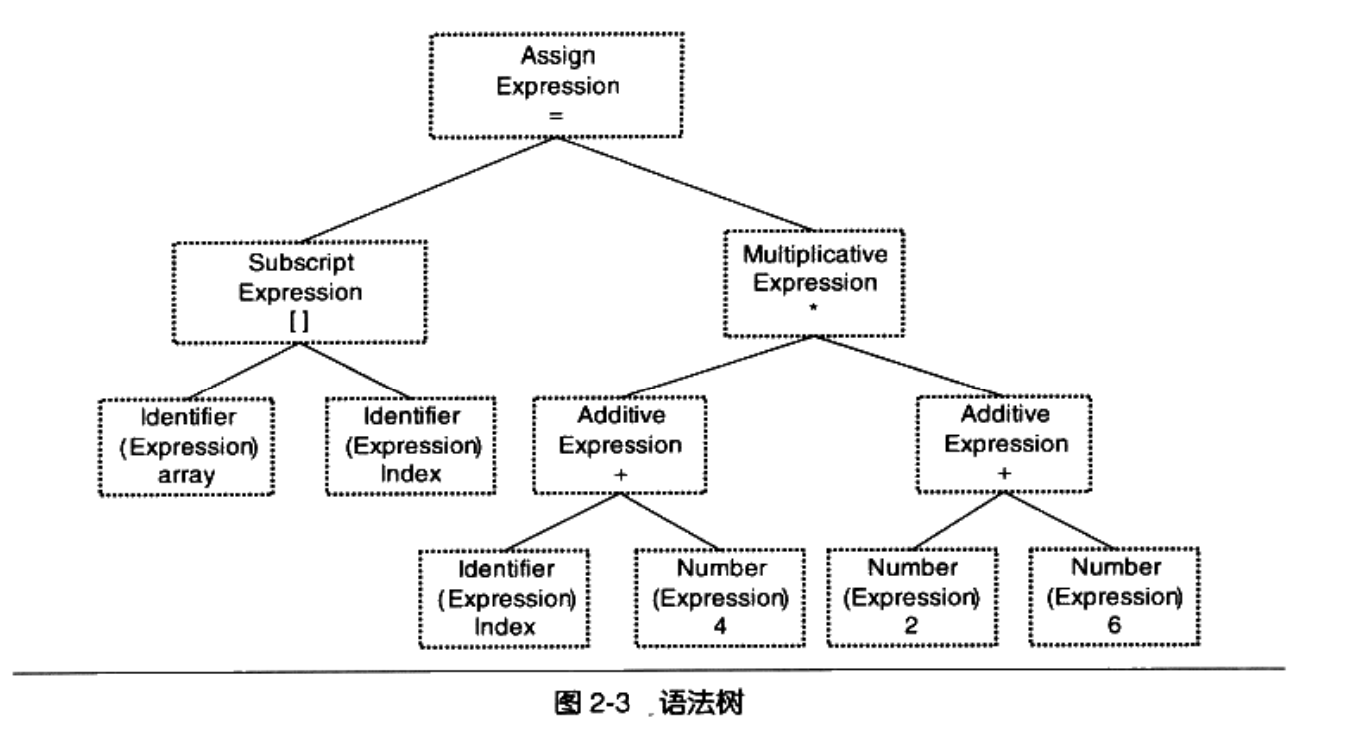
语义分析
语义分析器(Semantic Analyzer)对表达式进行静态的语义分析,标识各个表达式的类型;动态语义则只能在运行期确定.
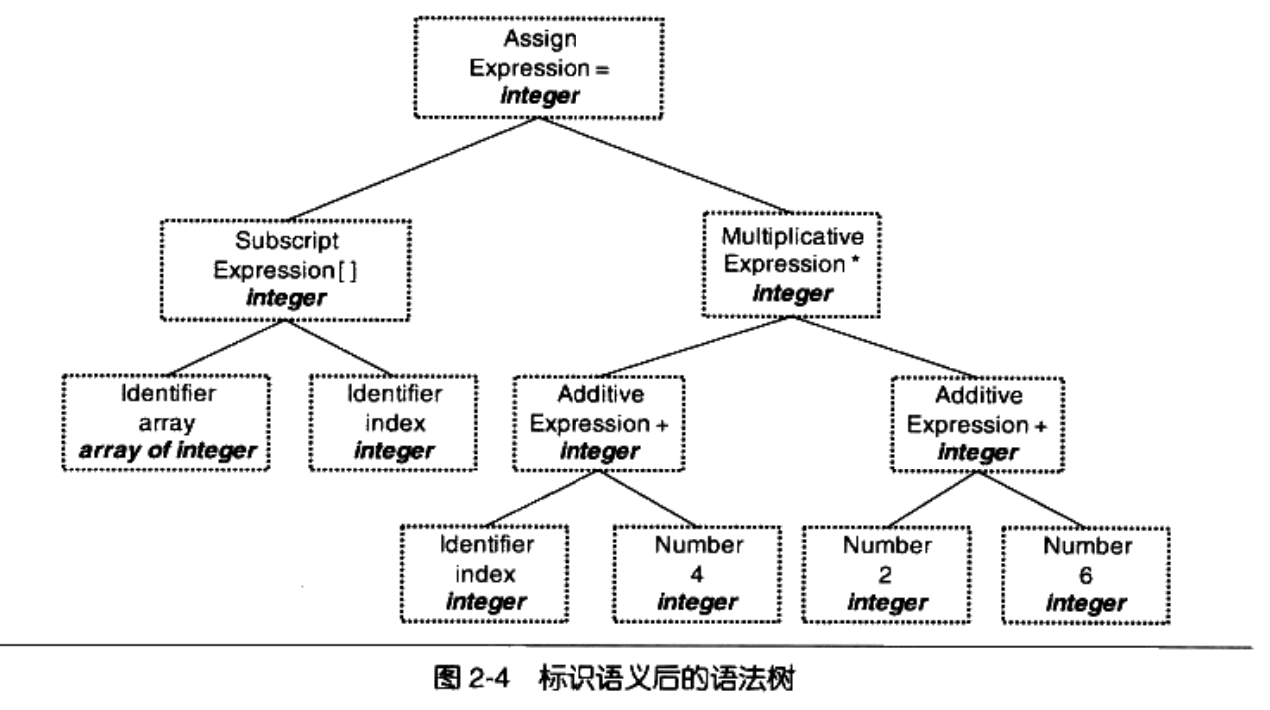
中间代码的生成
现代编译器会对源代码进行优化,将整个语法树转换成中间代码,尽管非常接近目标代码,但它与运行的操作系统无关,不包含数据尺寸,变量地址和寄存器名字等信息. 根据中间代码可以把编译器分为前端和后端.前端负责产生于操作系统无关的中间代码,后端负责将中间代码转换成目标文件 Java 编译体系 (Bytecode)
前端:javac。它将 .java 源码编译成与平台无关的 Java Bytecode (.class 文件)。这就是所谓的中间代码。
后端:JVM (Java Virtual Machine) 中的 JIT 编译器 (如 C1、C2)。当程序运行时,JIT 将字节码转换为当前运行机器(Windows x64、Linux ARM 等)的具体指令集。
目标代码的生成与优化
编译器后端主要包括代码生成器和目标代码优化器二者. 代码生成器将中间代码转换成目标机器代码,例如:
| |
然后由目标代码优化器对上述目标代码进行优化,比如选择合适的寻址方式,使用位移来代替乘法运算,删除冗余指令等
总结
经过这么多步骤后,源代码被编译成了目标代码,但有一个问题,变量的存储地址还没有确定,而且如果这个变量是来自其他模块的话又该怎么办?这就是链接派上用场的地方了
链接概览
 链接有以下几个步骤:
链接有以下几个步骤:
- 地址和空间分配(Address and Storage Allocation)
- 符号决议(Symbol Resolution)
- 重定位(Relocation)
补充: 编译全过程;编译器的前端和后端
由于书上对这些概念没有做一个很清晰的介绍,因此我再在这里做一点辨析方便后续的阅读: 流水线解释
- 预处理: 转换宏定义,删除注释
- 编译(狭义): 将cpp源码翻译成汇编代码(人类可读)
- 汇编:
- 将汇编代码翻译成机器指令(二进制码)
- 根据机器指令,地址位置等信息构造目标文件
- 链接: 将目标文件与系统库,用户库关联起来,得到可执行文件
- 编译(广义): 由于大多数人对cpp的装载过程没有一个清晰的认识,故通常使用编译代指从
.cpp到.exe的全过程,也就是说我们一般都用广义的编译概念,很少特指"真正的编译"
但是,我们所用的编译器如gcc,clang等都是广义上的编译器,也就是说不仅仅做的是编译,而是包揽了从.cpp到目标文件的全构建过程.
如果用前端和后端的概念来划分的话,是这样的:
前端(Frontend)
范畴: 仅包含“编译”这一步的前半部分。
- 输入: 预处理后的源码。
- 任务: 词法分析(Lexical Analysis)、语法分析(Syntax Analysis)、语义分析(Semantic Analysis)、生成中间表示(IR, Intermediate Representation)。
- 特性: 与具体的硬件架构(如 x86、ARM)无关,只与 C++ 语言本身的规则有关。
后端(Backend)
范畴: 包含“编译”这一步的后半部分,以及“汇编”的全部。
- 任务: * 中端优化(Optimizer):对 IR 进行架构无关的优化。
- 代码生成(Code Generator):将 IR 转换为特定硬件的汇编代码。
- 汇编器(Assembler):将汇编代码转换为机器指令,产出目标文件。
- 特性: 强依赖于硬件架构。
其他项
- 预处理(Preprocessing):通常被视为编译前的“文本清洁工作”,不属于狭义编译器(Compiler Core)的前后端逻辑。
- 链接(Linking):属于编译链的下游,是一个独立的二进制处理过程,不属于编译器(Compiler)的范畴。
目标文件: 汇编的产物
目标文件的格式
可执行文件的格式主要有Windows中的PE(Portable Executable,不是那个重装windows用的Preinstallation Environment)和Linux中的ELF(Executable Linkable Format),两者都是COFF(Common file format)的变种.从广义上看,可执行文件的格式与目标文件基本相同,故这里将它们看作一种类型的文件,在Windows中称为PE-COFF文件格式,在Linux中称为ELF文件格式.(也就是说我们这里把目标文件就看成是ELF文件)
- 事实上,动态链接库(DLL,Dynamic Linking Library)(Windows.dll和Linux的.so)和静态链接库(Static Linking Library)(Windows的.lib和Linux的.a)的存储方式也是可执行文件.
更为标准的分类方法如下:
| ELF 文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定向文件 (Relocatable File) | 包含代码和数据,可被用来链接成可执行文件或共享目标文件,静态链接库也归为此类。 | Linux 的 .oWindows 的 .obj |
| 可执行文件 (Executable File) | 包含可以直接执行的程序。 | Linux 的 /bin/bashWindows 的 .exe |
| 共享目标文件 (Shared Object File) | 包含代码和数据。可由链接器与其他可重定向/共享目标文件链接产生新目标文件;或由动态链接器与可执行文件结合,作为进程映像的一部分运行。 | Linux 的 .soWindows 的 DLL |
| 核心转储文件 (Core Dump File) | 当进程意外终止时,系统将该进程的地址空间内容及终止时的其他信息转储到该文件。 | Linux 下的 core dump |
ELF文件的内容
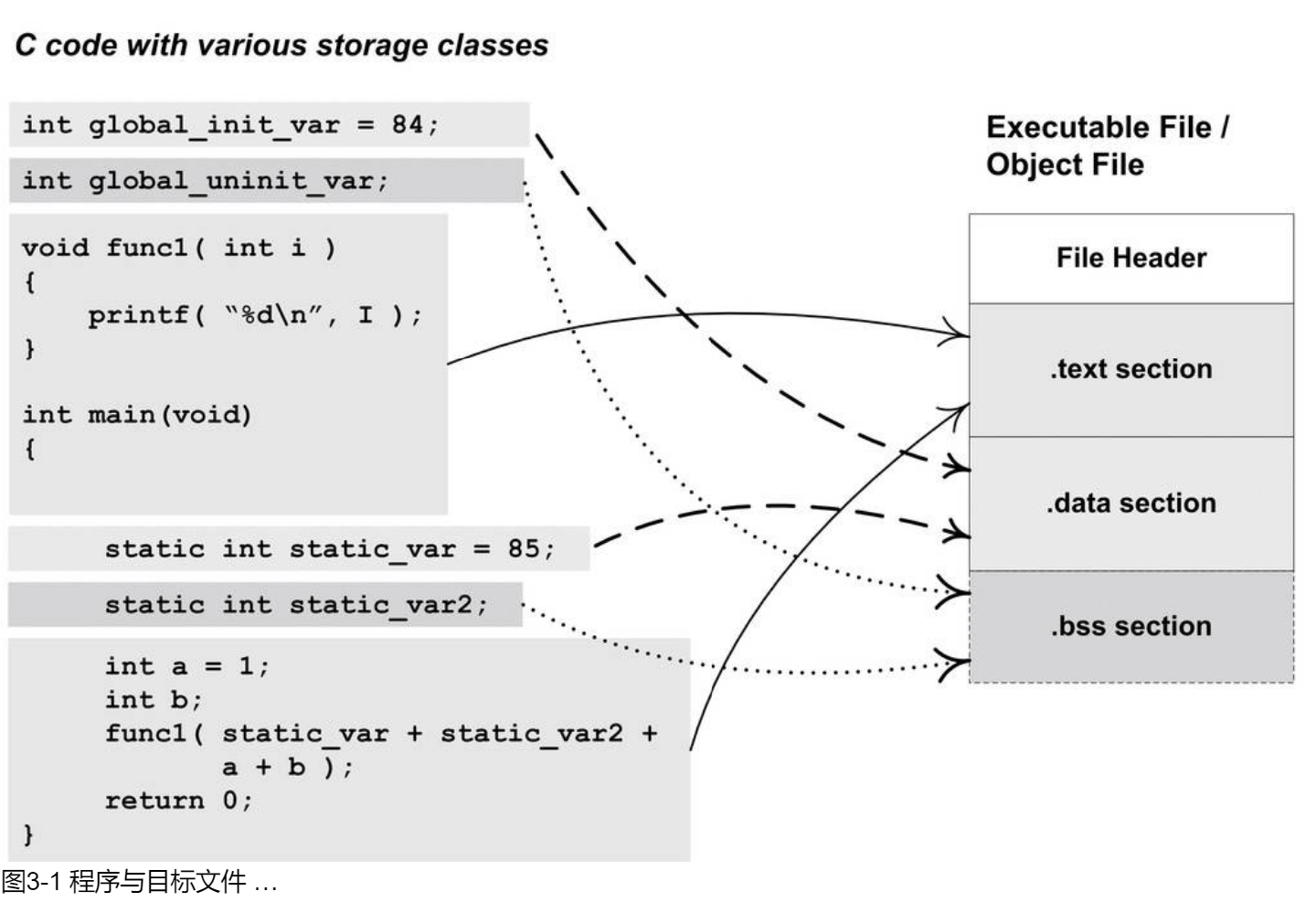
目标文件将不同类型的信息用段(section)的形式存储:
- File Header: 描述了整个文件的文件属性,包括文件是否可执行,目标硬件,目标操作系统等信息;还包括一个段表(section table),描述目标文件中各段的属性
- 使用C语言的结构体来定义
- .text section: 保存汇编得到的及其代码
- .data section: 保存已经初始化的全局变量和局部静态变量
- .bss section: 保存未初始化的全局变量和局部静态变量,由于它们都是0,故没有必要放入.data段中,同时,由于程序运行时需要记录这两类变量,因此需要用.bss段来额外预留位置.该段并没有内容,故在目标文件中也不占据空间.
bss的来历 BSS(Block Started by Symbol)来源于1950年代IBM大型机的汇编器中的一个伪指令,后来被引入标准汇编器FAP中,用于定义符号并且为该符号预留给定数量的未初始化空间
整体来说,源代码被编译后分成两段:程序指令(代码段),程序数据(数据段和.bss段).
事实上,ELF文件的内部结构比上述所说的四段式结构要复杂的多:
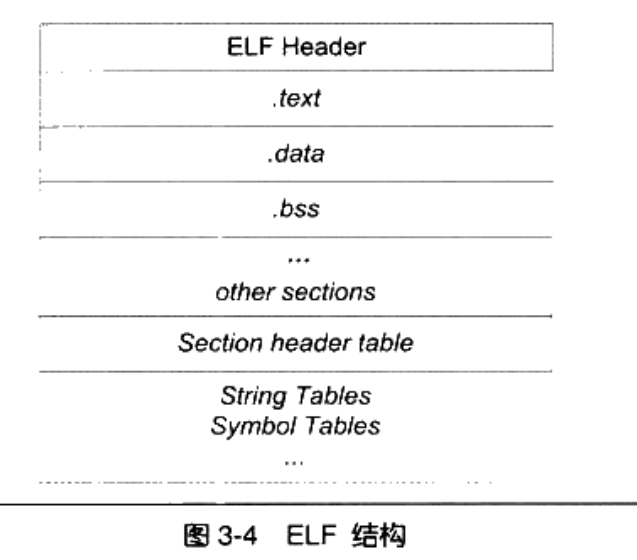
- [ 0] (NULL):索引为 0 的段物理上必须存在且全为空,用于标识无效引用。
- [ 1] .text:代码段。存放程序经过编译后的物理机器指令。
- [ 2] .rel.text:代码重定位段。记录
.text段中哪些物理地址需要在链接时进行修正。 - [ 3] .data:已初始化数据段。存放程序中已初始化的全局变量和局部静态变量。
- [ 4] .bss:未初始化数据段。为未初始化的全局变量预留的物理占位符,在文件中不占实际磁盘空间。
- [ 5] .rodata:只读数据段。存放常量(如字符串常量、
const修饰的变量)。 - [ 6] .comment:注释段。物理记录编译器版本信息(如 “GCC: (GNU) …")。
- [ 7] .note.GNU-stack:堆栈属性段。物理标识堆栈是否可执行,用于系统安全防御(NX 位)。
- [ 8] .shstrtab:段表字符串表。存储所有段名(如 “.text”, “.data”)的物理字符串池。
- [ 9] .symtab:符号表。记录程序中定义和引用的所有函数名、变量名及其物理偏移。
- [10] .strtab:字符串表。存储符号表中所使用的所有名称字符串。
下面我们来一个个解析:
文件头,段表,重定位表
文件头
本书使用的示例c程序分析得到的文件头内容如下:
- Magic (魔数):
7f 45 4c 46 01 01 01 00 ...- 物理意义:文件开头的 16 个字节,用于标识该文件是一个 ELF 格式的可执行或目标文件。
- Class (类别):
ELF32- 物理意义:该文件是为 32 位 架构设计的。
- Data (数据存储方式):
2's complement, little endian- 物理意义:采用二补码形式,且为 小端序(低位字节存储在低地址)。
- Version (版本):
1 (current)- 物理意义:当前 ELF 格式的版本号。
- OS/ABI (操作系统/接口):
UNIX - System V- 物理意义:该文件遵循的物理调用约定标准。
- Type (文件类型):
REL (Relocatable file)- 物理意义:这是一个可重定位文件(通常为
.o文件),尚未经过链接。
- 物理意义:这是一个可重定位文件(通常为
- Machine (硬件平台):
Intel 80386- 物理意义:物理运行的目标指令集架构。
- Entry point address (入口地址):
0x0- 物理意义:由于是可重定位文件,尚未装载,因此物理入口地址为 0。
- Start of program headers (程序头起点):
0 (bytes into file)- 物理意义:目标文件中通常不包含程序头表(Program Header Table),该表仅在可执行文件中存在。
- Start of section headers (段表起点):
280 (bytes into file)- 物理意义:**段表(Section Header Table)**在文件内部的物理偏移地址。
- Size of this header (ELF 头大小):
52 (bytes)- 物理意义:ELF Header 本身物理占据的字节长度。
- Size of section headers (单段描述符大小):
40 (bytes)- 物理意义:段表中每个条目物理占据的空间。
- Number of section headers (段的数量):
11- 物理意义:该文件物理包含 11 个段(如
.text,.data,.bss等)。
- 物理意义:该文件物理包含 11 个段(如
- Section header string table index (段表字符串表索引):
8- 物理意义:存储段名字符串的表在段表中的物理下标。
事实上,这些信息是以C语言的结构体存储的:
| |
在 ELF 文件格式定义中,为了屏蔽不同平台下
int或long长度不一带来的物理对齐问题,官方定义了一套标准数据类型:
| 自定义类型 | 描述 | 原始类型 | 长度(字节) |
|---|---|---|---|
| Elf32_Addr | 32 位版本程序地址 | uint32_t | 4 |
| Elf32_Half | 32 位版本无符号短整型 | uint16_t | 2 |
| Elf32_Off | 32 位版本偏移地址 | uint32_t | 4 |
| Elf32_Sword | 32 位版本有符号整型 | int32_t | 4 |
| Elf32_Word | 32 位版本无符号整型 | uint32_t | 4 |
| Elf64_Addr | 64 位版本程序地址 | uint64_t | 8 |
| Elf64_Half | 64 位版本无符号短整型 | uint16_t | 2 |
| Elf64_Off | 64 位版本偏移地址 | uint64_t | 8 |
| Elf64_Sword | 64 位版本有符号整型 | int32_t | 4 |
| Elf64_Word | 64 位版本无符号整型 | uint32_t | 4 |
带上示例来解释:
| 成员 | 内容 | 物理/逻辑解释 |
|---|---|---|
| e_ident | Magic: 7f 45 4c 46 01 01 01 00… | ELF 魔数。包含文件机器字节长度、数据存储方式、版本、运行平台及 ABI 版本。 |
| e_type | Type: REL (Relocatable file) | ELF 文件类型。标识是可重定位文件、可执行文件还是共享对象文件。 |
| e_machine | Machine: Intel 80386 | CPU 平台属性。相关常量以 EM_ 开头(如 EM_386)。 |
| e_version | Version: 0x1 | ELF 版本号。通常为常数 1。 |
| e_entry | Entry point address: 0x0 | 入口地址。规定程序开始执行的虚拟地址。可重定位文件(.o)通常为 0。 |
| e_phoff | Start of program headers: 0 | 程序头(Program Header)偏移。在链接视图中暂不关心,执行视图的核心。 |
| e_shoff | Start of section headers: 280 | 段表(Section Header)偏移。即段表在文件内的起始物理位置。 |
| e_word | Flags: 0x0 | ELF 标志位。标识特定平台相关的属性,格式通常为 EF_machine_flag。 |
| e_ehsize | Size of this header: 52 (bytes) | ELF 文件头本身的大小。在本例中物理占据 52 字节。 |
| e_phentsize | Size of program headers: 0 | 程序头描述符的大小。 |
| e_phnum | Number of program headers: 0 | 程序头描述符的数量。 |
| e_shentsize | Size of section headers: 40 (bytes) | 段表描述符的大小。物理上等于 sizeof(Elf32_Shdr)。 |
| e_shnum | Number of section headers: 11 | 段的数量。物理记录了 ELF 文件中拥有的段表描述符总数。 |
| e_shstrndx | Section header string table index: 8 | 段表字符串表下标。存储段名字符串的表在段表中的物理索引位置。 |
魔数详解
e_ident成员的前四个字节7f 45 4c 46中,第一个字节对应的是ASCII中的DEL控制符,后三个字节刚好是ELF这三个字母的ASCII码,从而唯一标识了ELF文件,故被称为ELF文件的魔数.
接下来的一个字节用来标识ELF的文件类,
01表示是32位的,02表示是64位的;第六个字节是字节序,规定该文件是大端存储还是小端存储;第七个字节为该文件的主版本号,一般是1,因为ELF标准从1.2版后就没有更新过.后面的9个字节ELF标准没有定义,一般填0. 至于为什么要多出来这9个字节,主要是为了兼容老编译器的考量.
自然,所有的可执行文件都有一个魔数用来标识自己,比如PE/COFF文件的最开始两个字节为4d,5a,即ASCII字符MZ.
段表
段表用于保存ELF文件中各个section(段)的基本信息,比如段的名字,长度,存储位置,读写权限等属性.编译器,链接器和装载器都是依靠段表来定位和访问各个段的属性的,至于段表的位置则是由文件头中的
e_shoff字段来定义的.
- 尽管书上讲的很详细,但我想只需要大概知道段表的作用即可
重定位表
链接器在处理目标文件的时候,需要对目标文件中的某些部分进行重定位,即.text段和.data段中对绝对地址引用的位置.
对于每个要重定位的.text段和.data段,都会有一个相应的重定位表.
链接的接口: symbol
如果目标文件B用到了目标文件A中的函数foo,那么就称A定义(define)了foo,B引用(reference)了A中的函数foo.
在链接中,函数和变量统称为符号(symbol),函数名和变量名则为符号名(symbol name).
链接中很关键的一部分就是符号的管理,每一个目标文件都有一个相应的符号表,记录该目标文件中用到的所有符号,每个定义的符号有一个对应的符号值,对于变量和函数来说,符号值就是它们的地址.
除了函数和变量之外,还存在其他几种不常用到的符号。我们将符号表中所有的符号进行分类,它们可能是下面这些类型中的一种:
- 定义在本目标文件的全局符号,可以被其他目标文件引用。比如 SimpleSection.o 里面的 “func1”、“main” 和 “global_init_var”。
- 在本目标文件中引用的全局符号,却没有定义在本目标文件,这一般叫做外部符号(External Symbol),也就是我们前面所讲的符号引用。比如 SimpleSection.o 里面的 “printf”。
- 段名,这种符号往往由编译器产生,它的值就是该段的起始地址。比如 SimpleSection.o 里面的 “.text”、“.data” 等。
- 局部符号,这类符号只在编译单元内部可见。比如 SimpleSection.o 里面的 “static_var” 和 “static_var2”。调试器可以使用这些符号来分析程序或崩溃时的核心转储文件。这些局部符号对于链接过程没有作用,链接器往往也忽略它们。
- 行号信息,即目标文件指令与源代码中代码行的对应关系,它也是可选的。
符号修饰与函数签名
在cpp中我们可以通过命名空间(namespace)和函数重载定义多个同名函数,那么编译器和链接器就需要在链接过程中区分这两个函数.
首先,我们可以使用函数签名(function signature)来区分不同的函数,它包含了函数的名字,参数类型,命名空间,所在的类及其他信息.这样可以保证每一个函数都有一个独特的函数签名.
其次,我们可以根据函数签名在编译过程中修饰这些函数,例如:
| 函数签名 | 修饰后名称(符号名) |
|---|---|
| int func(int) | _Z4funci |
| float func(float) | _Z4funcf |
| int C::func(int) | _ZN1C4funcEi |
| int C::C2::func(int) | _ZN1C2C24funcEi |
| int N::func(int) | _ZN1N4funcEi |
| int N::C::func(int) | _ZN1N1C4funcEi |
自然,cpp中的全局变量和静态变量也有同样的签名和修饰机制,而C语言由于不存在重名机制,故不需要对涉及的符号进行任何修改.
强弱符号
在C/CPP中,函数和初始化的全局变量为强符号(strong symbol),未初始化的全局变量为弱符号(weak symbol).
编译器按照以下三个规则来处理强弱符号:
- 不允许强符号被多次定义,否则链接器会报出符号重复定义的错误
- 如果一个符号在某个目标文件中是强符号,在其他目标文件中是弱符号,则将它看作为强符号
- 如果一个符号在所有目标文件中都是弱符号,那么选择占用空间最大的一个作为它的定义,如int和double中选择double.
强弱引用
当目标文件中引用外部符号时,如果在链接时,没有找到该符号的定义,那么就会报出未定义错误,这类引用被称为强引用(strong reference).
但是还有一类特殊的引用即使在链接时没找到该符号的定义也不报错,被称为弱引用(weak reference).这允许了冗余代码和缺失功能模块的设计.
调试信息
目标文件里还会保存调试信息,如果我们用GCC编译时加上 “-g” 参数,编译器就会在产生的目标文件里面加上调试信息,我们通过 readelf 等工具可以看到,目标文件里多了很多 “debug” 相关的段:
| [Nr] | Name | Type | Addr | Off | Size | ES | Flg | Lk | Inf | Al |
|---|---|---|---|---|---|---|---|---|---|---|
| … | ||||||||||
| [ 4] | .debug_abbrev | PROGBITS | 00000000 | 000040 | 000034 | 00 | 0 | 0 | 1 | |
| [ 5] | .debug_info | PROGBITS | 00000000 | 000074 | 0000af | 00 | 0 | 0 | 1 | |
| [ 6] | .rel.debug_info | REL | 00000000 | 000738 | 000038 | 08 | 9 | 5 | 4 | |
| [ 7] | .debug_line | PROGBITS | 00000000 | 000123 | 000037 | 00 | 0 | 0 | 1 | |
| [ 8] | .rel.debug_line | REL | 00000000 | 000770 | 000008 | 08 | 19 | 7 | 4 | |
| [ 9] | .debug_frame | PROGBITS | 00000000 | 00015c | 000034 | 00 | 0 | 0 | 4 | |
| [10] | .rel.debug_frame | REL | 00000000 | 000778 | 000010 | 08 | 19 | 9 | 4 | |
| [11] | .debug_loc | PROGBITS | 00000000 | 000190 | 00002c | 00 | 0 | 0 | 1 |
- 调试信息在目标文件和可执行文件中占用了很大的空间,往往比程序的代码和数据本身大好几倍,因此,发布程序时,我们需要去除这些对于用户没有用的调试信息,从而节省大量的空间
- 例如可以在VS中选用Release模式而非Debug模式,从而将大部分调试信息排除在打包的可执行文件以外.
静态链接(4/15)
 当我们运行
当我们运行gcc -c a.c b.c后,得到两个目标文件a.o和b.o,如何将他们链接起来,形成一个可执行文件?这个过程中发生了什么?
链接方法
对于多个目标文件,链接器有以下两种方法,将他们的各个段(section)合并到一个可执行文件中:
- 按序叠加
- 相似段合并
按序叠加
这种方法将输入的目标文件按照次序叠加起来:
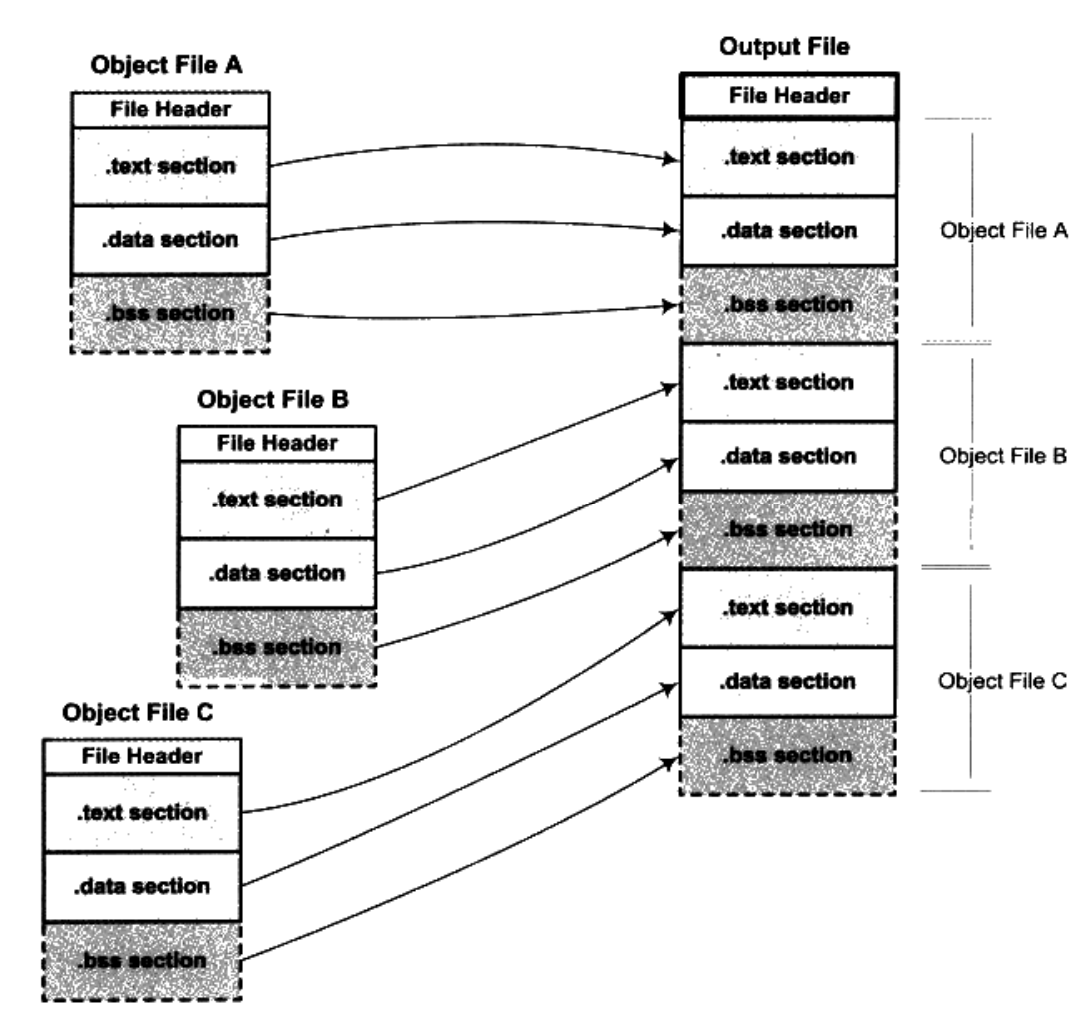 显然,这种做法非常浪费空间,会堆积一大堆冗余数据
显然,这种做法非常浪费空间,会堆积一大堆冗余数据
相似段合并
将相同性质的段合并到一起是一个更为实际的方法,也是主流的链接器空间分配策略:
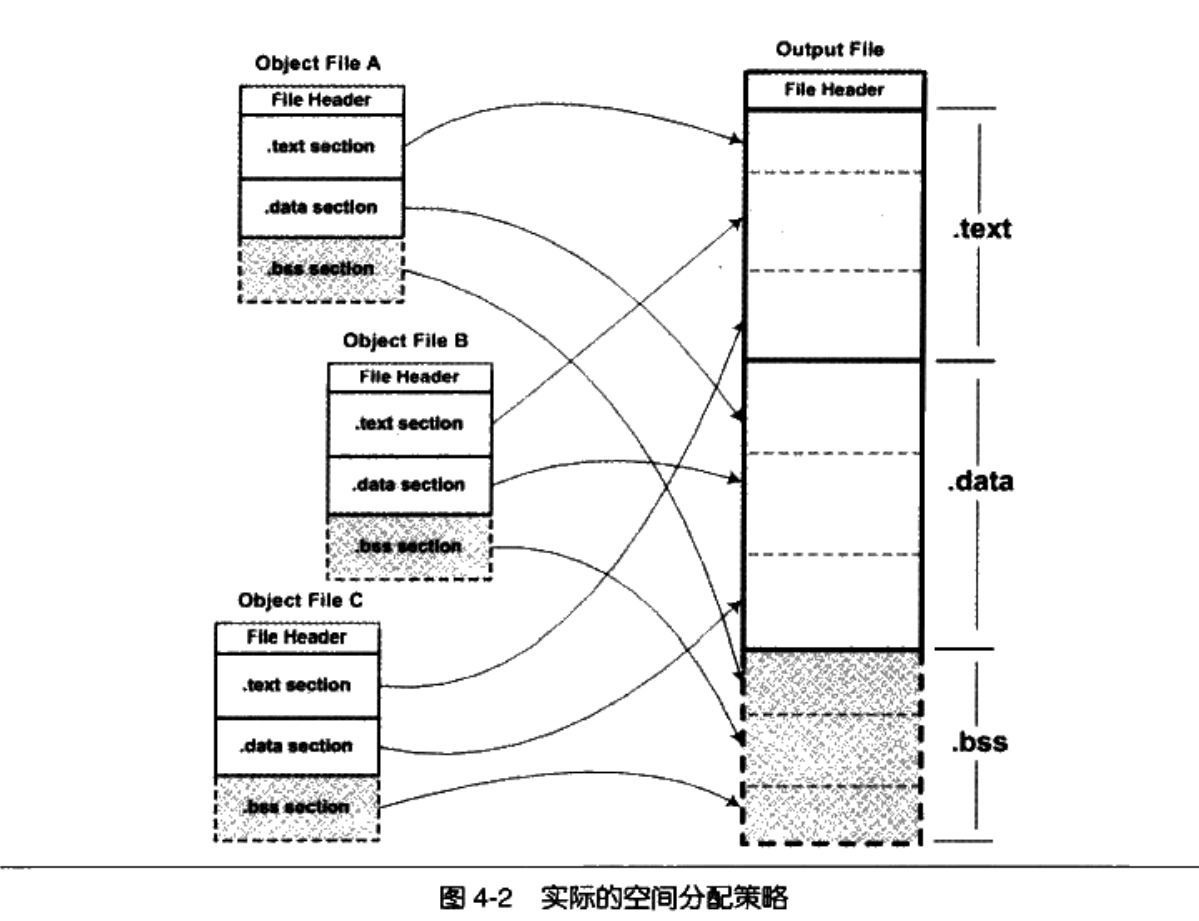 这种链接方式分为两步:
这种链接方式分为两步:
- 空间和地址分配: 扫描所有的目标文件,将符号表中的所有信息统一放到一个全局符号表
- 符号解析和重定位: 根据上一步的信息,进行符号解析和重定位,调整代码中的地址
空间与地址分配
通过 objdump -h 命令观察目标文件 a.o、b.o 以及链接后的可执行文件 ab 的段分配情况:
a.o (目标文件)
| Idx | Name | Size | VMA | LMA | File off | Algn | Flags |
|---|---|---|---|---|---|---|---|
| 0 | .text | 00000034 | 00000000 | 00000000 | 00000034 | 2**2 | CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE |
| 1 | .data | 00000000 | 00000000 | 00000000 | 00000068 | 2**2 | CONTENTS, ALLOC, LOAD, DATA |
| 2 | .bss | 00000000 | 00000000 | 00000000 | 00000068 | 2**2 | ALLOC |
b.o (目标文件)
| Idx | Name | Size | VMA | LMA | File off | Algn | Flags |
|---|---|---|---|---|---|---|---|
| 0 | .text | 0000003e | 00000000 | 00000000 | 00000034 | 2**2 | CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE |
| 1 | .data | 00000004 | 00000000 | 00000000 | 00000074 | 2**2 | CONTENTS, ALLOC, LOAD, DATA |
| 2 | .bss | 00000000 | 00000000 | 00000000 | 00000078 | 2**2 | ALLOC |
ab (链接后的可执行文件)
| Idx | Name | Size | VMA | LMA | File off | Algn | Flags |
|---|---|---|---|---|---|---|---|
| 0 | .text | 00000072 | 08048094 | 08048094 | 00000094 | 2**2 | CONTENTS, ALLOC, LOAD, READONLY, CODE |
| 1 | .data | 00000004 | 08049108 | 08049108 | 00000108 | 2**2 | CONTENTS, ALLOC, LOAD, DATA |
- VMA (Virtual Memory Address):链接前目标文件的 VMA 均为
0,因为尚未物理分配虚拟地址;链接后ab中的段被物理分配到了以0804xxxx开头的地址空间。- LMA(Load Memory Address): 装载地址,正常情况下该值与VMA相同,但在部分嵌入式系统中,两个值是不同的.
- Size 合并:
ab的.text段大小(0x72)约等于a.o(0x34)与b.o(0x3e)之和,体现了链接器的段合并策略。 - Flags 变化:链接后的
ab移除了RELOC标志,说明物理重定位已完成。
可执行文件里没有物理地址,在执行时才由操作系统将虚拟地址映射到物理地址
符号解析与重定位(4/22)
- 重定位: 修正编译器产生的符号(函数与变量)地址
- 符号解析: 根据全局符号表查找所需符号的地址,用于重定位
C++相关的链接问题(待补充)
Windows PE/COFF
之所以叫PE/COFF,是因为windows32位的可执行文件格式PE与ELF一样,都是从古老的COFF格式发展来的.换句话说,PE(Portable Executable)是COFF的一种扩展,结构上大致相同,与ELF格式也基本相同,都采用了段的格式
- windows64位中,对原本的PE格式做了一点修改,叫做PE32+,它没有增加新的字段,只是把原来的32位字段变成了64位,因此我们也可以把它看作是一般的PE文件.
总的来说的话,在Windows中目标文件为COFF格式,为.obj后缀;可执行文件/动态链接库为PE格式,为.exe/dll后缀
COFF文件结构
COFF 目标文件格式 (COFF Object File Format) 的常见结构如下:
- Image Header (
IMAGE_FILE_HEADER) - Section Table (
IMAGE_SECTION_HEADER[]) - .text(代码节)
- .data(数据节)
- .drectve(指示节)
- .debug$S(调试符号节)
- other sections(其他节)
- Symbol Table(符号表)
- 与ELF文件格式确实很像
前两个部分是COFF文件的文件头,分别是描述文件总体结构和属性的映像头和描述各段属性的段表
- 映像(image): PE文件在装载时会被直接映射到进程的虚拟空间中,是进程虚拟空间的映像.
PE文件结构
PE 文件格式 (PE File Format) 的常见结构如下:
- Image DOS Header (
IMAGE_DOS_HEADER) - Image DOS Stub
- PE File Header (
IMAGE_NT_HEADERS)- Image Header (
IMAGE_FILE_HEADER) - Image Optional Header (
IMAGE_OPTIONAL_HEADER32)
- Image Header (
- Section Table (
IMAGE_SECTION_HEADER[]) - .text
- .data
- .drectve
- .debug$S
- other sections
- Symbol Table
第一段和第二段中DOS部分的来历:
在Windows发展的早期,古老的DOS系统还十分盛行,而此时的Windows甚至不能脱离DOS环境独立运行,所以为Windows1编写的程序必须加入这两个DOS段来兼容DOS系统. 为了兼容古老的程序,直到现在的Windows可执行文件都包含了这两个段
Image DOS Header详解
“IMAGE_DOS_HEADER”结构也被定义在 WinNT.h 里面,该结构的大多数成员我们都不关心,唯一值得关心的是“e_lfanew”成员,这个成员表明了 PE 文件头(IMAGE_NT_HEADERS)在 PE 文件中的偏移,我们需要使用这个值来定位 PE 文件头。
这个成员在 DOS 的“MZ”文件格式中的值永远为 0,所以当 Windows 开始执行一个后缀名为“.exe”的文件时,它会判断“e_lfanew”成员是否为 0。如果为 0,则该“.exe”文件是一个 DOS“MZ”可执行文件,Windows 会启动 DOS 子系统来执行它;如果不为 0,那么它就是一个 Windows 的 PE 可执行文件,“e_lfanew”的值表示“IMAGE_NT_HEADERS”在文件中的偏移。
Image DOS Stub详解
当 PE 可执行映像在 DOS 下被加载的时候,DOS 系统检测该文件,发现最开始两个字节是“MZ”,于是认为它是一个“MZ”可执行文件。然后 DOS 系统就将 PE 文件当作正常的“MZ”文件开始执行。
DOS 系统会读取 “e_cs” 和 “e_ip” 这两个成员的值,以跳转到程序的入口地址。然而 PE 文件中,“e_cs”和“e_ip”这两个成员并不指向程序真正的入口地址,而是指向文件中的 “DOS Stub”。
“DOS Stub” 是一段可以在 DOS 下运行的一小段代码,这段代码的唯一作用是向终端输出一行字:
“This program cannot be run in DOS”
然后退出程序,表示该程序不能在 DOS 下运行。所以我们如果在 DOS 系统下运行 Windows 的程序就可以看到上面这句话,这是因为 PE 文件结构兼容 DOS “MZ” 可执行文件结构的缘故。
可执行文件的装载
可执行文件只有装载到内存以后才能被 CPU 执行。早期的程序装载十分简陋,装载的基本过程就是把程序从外部存储器中读取到内存中的某个位置。随着硬件 MMU 的诞生,多进程、多用户、虚拟存储的操作系统出现以后,可执行文件的装载过程变得非常复杂。
进程虚拟地址空间
Transformers快速入门
标题很具有迷惑性,事实上,这篇文章的前面几章深入浅出的讲述了大语言模型(LLM)的前世今生,让人受益匪浅
自然语言处理
- 这一章的介绍相当精彩,通俗易懂
要让计算机处理自然语言,首先需要为自然语言建立数学模型,这种模型被称为语言模型(Language Model,LM),其核心思想是判断一个文字序列是否构成人类能理解并且有意义的句子,即建模文本序列的生成概率。
统计语言模型

- 可以看到,这里的数学原理是非常简单的,并不怎么难懂
即使是使用三元、四元甚至是更高阶的语言模型,依然无法覆盖所有的语言现象。在自然语言中,上下文之间的关联性可能跨度非常大,例如从一个段落跨到另一个段落,这是马尔可夫假设解决不了的。此时就需要使用 LSTM、Transformer 等模型来捕获词语之间的远距离依赖(Long Distance Dependency)了。
神经语言模型
NNLM模型
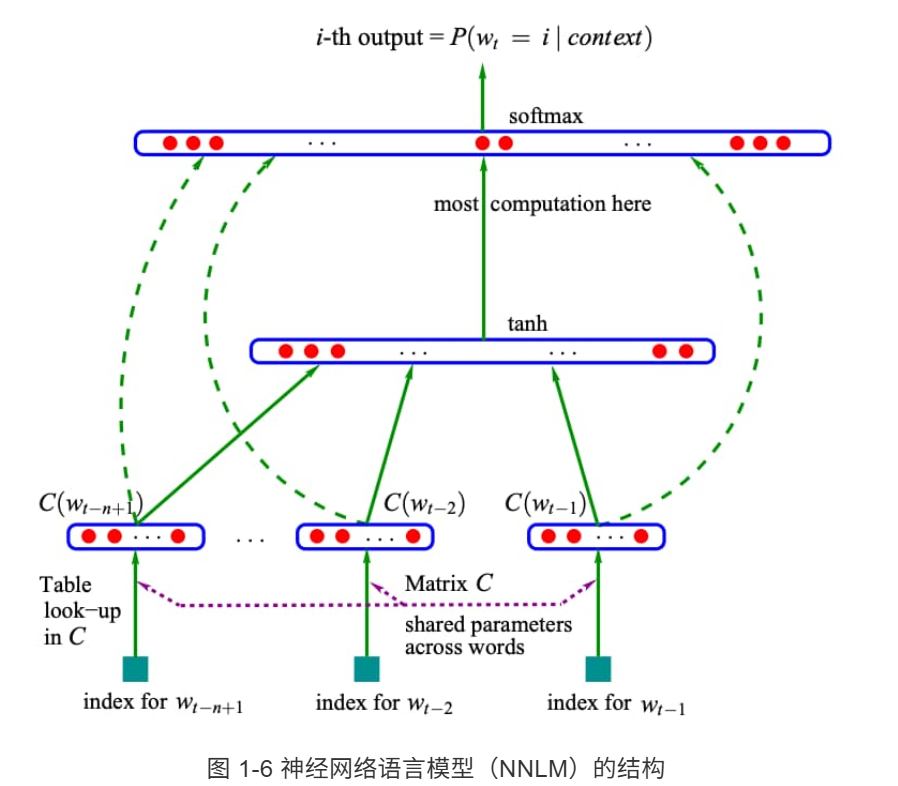
具体来说,NNLM 模型首先从词表C中查询得到前面N个词语对应的词向量,然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过Softmax函数预测当前词语的概率,它不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量
Word2Vec模型
Word2Vec 的模型结构和 NNLM 基本一致,只是训练方法有所不同,分为 CBOW (Continuous Bag-of-Words) 和 Skip-gram 两种:
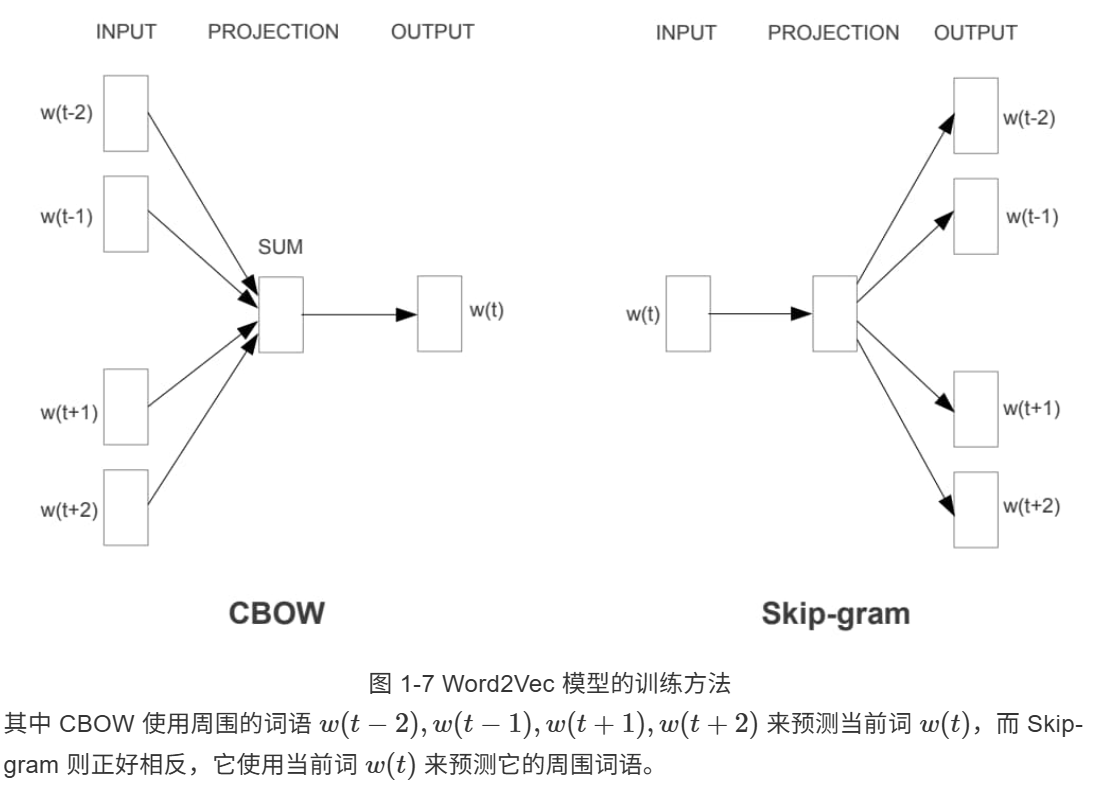
可以看到,与严格按照统计语言模型结构设计的 NNLM 模型不同,Word2Vec 模型在结构设计上更加自由,训练目标也更多是为获得词向量服务。特别是 CBOW 训练方法同时通过上文和下文来预测当前词语,打破了语言模型“只通过上文来预测当前词”的固定思维,为后续一系列神经网络语言模型的发展奠定了基础
预训练语言模型
然而,有一片乌云始终笼罩在 Word2Vec 模型的上空——多义词问题。一词多义是语言灵活性和高效性的体现,但是 Word2Vec 模型却无法处理多义词,一个词语无论表达何种语义,Word2Vec 模型都只能提供相同的词向量,即将多义词编码到完全相同的参数空间。
实际上在 20 世纪 90 年代初,雅让斯基(Yarowsky)就给出了一个简洁有效的解决方案——运用词语之间的互信息(Mutual Information) 具体来说,对于多义词,可以使用文本中与其同时出现的互信息最大的词语集合来表示不同的语义。例如对于“苹果”,当表示水果时,周围出现的一般就是“超市”、“香蕉”等词语;而表示“苹果公司”时,周围出现的一般就是“手机”、“平板”等词语
ELMo 模型
为了更好地解决多义词问题,2018 年研究者提出了 ELMo 模型(Embeddings from Language Models)。与 Word2Vec 模型只能提供静态词向量不同,ELMo 模型会根据上下文动态地调整词语的词向量。
但是 ELMo 模型存在两个缺陷:首先它使用 LSTM 模型作为编码器,而不是当时已经提出的编码能力更强的 Transformer 模型;其次 ELMo 模型直接通过拼接来融合双向抽取特征的做法也略显粗糙
GPT 模型
不久之后,OpenAI 将 ELMo 模型中的 LSTM 更换为 Transformer 提出了 GPT 模型(Generative Pre-trained Transformer)。并且 GPT 模型继续追随 NNLM 的脚步,采用仅有解码器的 Transformer 架构,只通过词语的上文进行预测。
虽然解码器架构适合于完成自然语言生成任务(如文本摘要),但是在一定程度上也限制了模型的应用场景,例如对于文本分类、阅读理解等任务,如果不把词语的下文信息也嵌入到词向量中就会白白丢掉很多信息。
BERT 模型
2018 年底,Google 基于 Transformer 模型进一步提出了 BERT 模型(Bidirectional Encoder Representations from Transformers),这一阶段神经网络语言模型的发展终于出现了一位集大成者,BERT 模型在发布时在 11 个任务上都取得了最好性能.
BERT 模型采用和 GPT 模型类似的两阶段框架,首先对语言模型进行预训练,然后通过微调来完成下游任务。但是,BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且采用了类似 ELMo 模型的双向语言模型结构,如图 1-11 所示。因此 BERT 模型不仅编码能力强大,而且对各种下游任务,BERT 模型都可以通过简单地改造输出部分来完成。
大语言模型
除了优化模型结构,研究者发现扩大模型规模也可以提高性能。在保持模型结构以及预训练任务基本不变的情况下,仅仅通过扩大模型规模就可以显著增强模型能力,尤其当规模达到一定程度时,模型甚至展现出了能够解决未见过复杂问题的涌现(Emergent Abilities)能力。例如 175B 规模的 GPT-3 模型只需要在输入中给出几个示例,就能通过上下文学习(In-context Learning)完成各种小样本(Few-Shot)任务,而这是 1.5B 规模的 GPT-2 模型无法做到的。为了区分这两代模型之间的差异,业界将大型预训练语言模型命名为“大语言模型”(Large Language Model,LLM)。
在规模扩展定律(Scaling Laws)被证明对语言模型有效之后,研究者基于 Transformer 结构不断加深模型深度,构建出了许多大语言模型 可以说,大语言模型的出现改变了自然语言处理的范式,从为特定 NLP 任务构建专用模型转变为使用单一的大型模型,通过提示或微调来处理各种语言任务,这使得复杂的语言处理更容易实现。相比早期的语言模型主要面向自然语言的建模与生成,最新的语言模型则侧重于复杂任务的求解。从语言建模到任务求解,这是人工智能科学思维的一次重要跃升。
- (26/4/15): 尽管直到现在都没人彻底搞明白为什么扩大模型规模就能实现性能的跃升,但还是有很多人都信誓旦旦的认为AI将会取代一切.
Transformer模型
正如第一章所述,自从 BERT 和 GPT 模型取得重大成功之后, Transformer 模型已经替代循环神经网络(RNN)、卷积神经网络(CNN)等传统神经网络结构,成为各种 NLP 模型的标配。
- 换句话说,出于工程应用的角度,不太有必要去学传统神经网络架构了
Transformer的架构
标准 Transformer 模型主要由**编码器(Encoder)和解码器(Decoder)**两个模块组成
其中编码器负责接收输入并构建输入的语义表示(语义特征),从而理解输入内容,而解码器则利用编码器输出的语义表示(语义特征)以及前序输出来生成目标序列。
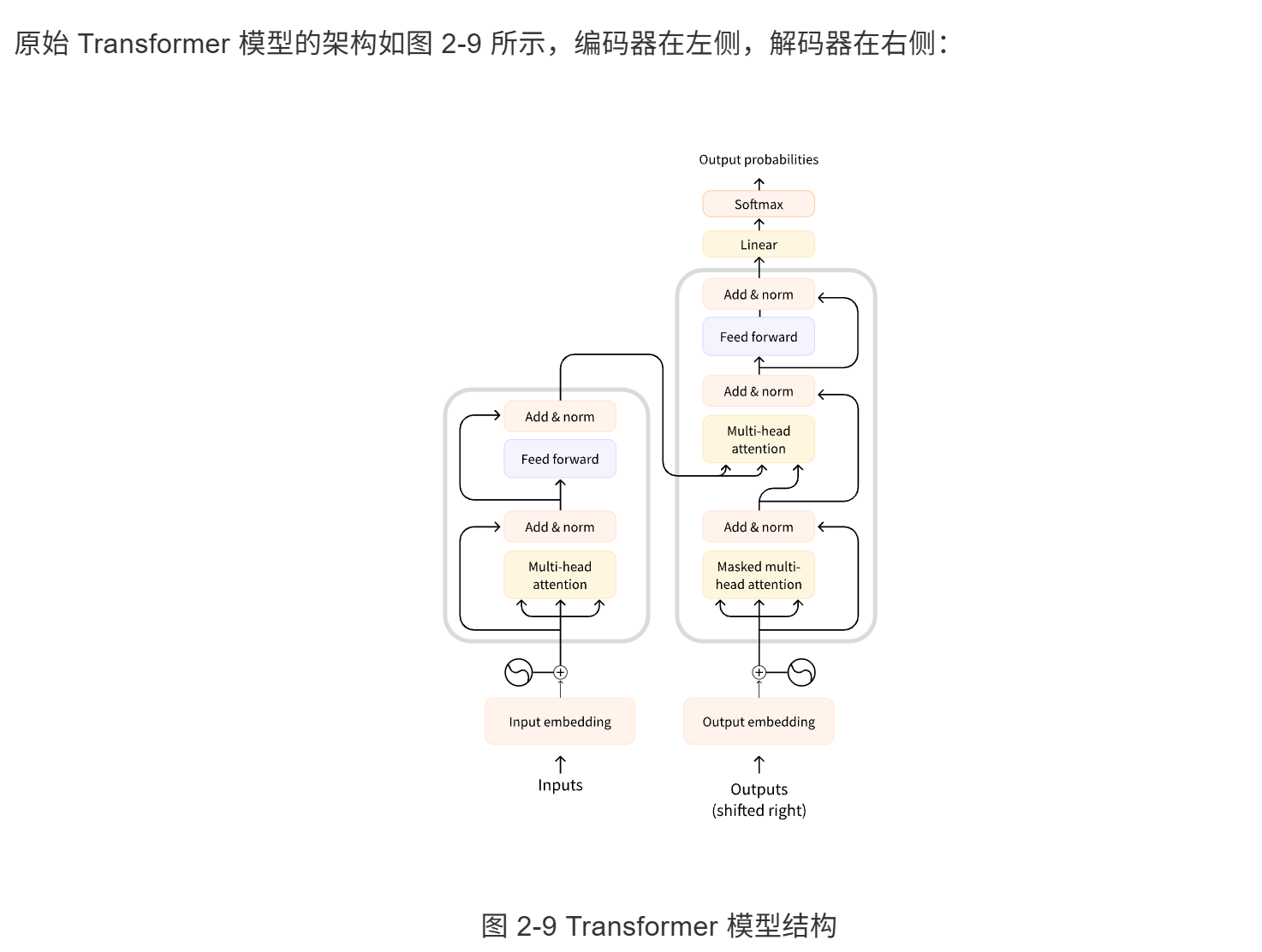
Transformer模型分类
纯编码器模型(Encoder-Only) 只包含编码器部分,采用双向语言建模,从两个方向理解上下文。适合需要深度理解文本的任务,例如文本分类、命名实体识别等,典型代表如 BERT。
纯解码器模型(Decoder-Only) 只包含解码器部分,从左到右处理文本。尤其擅长文本生成任务,可以根据提示完成句子、撰写文章,甚至生成代码,典型代表如 GPT、Llama。
- 大多数大语言模型(LLM)都采用纯解码器架构,这些模型在过去的几年中规模和功能都得到了显著提升,一些最大的模型包含数千亿个参数。
编码器-解码器模型(Encoder-Decoder) 结合了编码器和解码器,使用编码器理解输入,解码器生成输出。擅长序列到序列任务,例如翻译、摘要、问答等,典型代表如 T5、BART。
大语言模型的工作原理
推理是指大语言模型利用训练中积累的知识,根据给定的输入提示逐字逐句地生成生成类似人类语言文本的过程。具体来说,大语言模型会按照顺序生成的方式,利用从数十亿个参数中学习到的概率来预测和生成序列中的下一个词元(Token),从而生成连贯且与上下文相关的文本。
注意力的作用
注意力机制赋予大语言模型理解上下文并生成连贯响应的能力,在预测下一个词时,句子中的每个词并非都具有相同的权重。 例如,在句子“法国的首都是……”中,“法国”和“首都”这两个词对于确定下一个词是“巴黎”至关重要.
这种识别最相关词以预测下一个词元的方法已被证明非常有效。简而言之,注意力机制是语言模型能够生成既连贯又具有上下文感知能力的文本的关键,它也是使现代语言模型区别于前几代语言模型的关键
想要了解大语言模型实际能够处理多少上下文信息,就需要引出上下文长度,或者说模型的“注意力跨度”。上下文长度是指大语言模型一次可以处理的最大词元数量,这会受到模型的架构和尺寸、可用计算资源以及输入和期望输出的复杂性等多个因素的限制。
当我们向大语言模型传递信息时,会以某种方式组织输入以引导模型生成所需的输出,这被称为提示词工程(Prompting)。由于模型的主要任务就是通过注意力机制分析每个输入词元的重要性来预测下一个词元,因此输入序列的措辞至关重要。相比口语化的简单任务描述,精心设计的提示(Prompt)可以更容易地引导大语言模型生成符合预期的输出。
两阶段推理过程
大语言模型生成文本的过程主要分为两个阶段:预填充(Prefill)和解码.
预填充阶段就像烹饪中的准备阶段,所有初始食材都在此阶段进行加工和准备,该阶段包含三个关键步骤:
- 分词(Tokenization):将输入文本转换为模型可以理解的基本语言单元——词元(token)。
- 嵌入转换(Embedding Conversion):将词元转换为能够表示其语义的密集嵌入表示。
- 初始处理:将这些嵌入向量输入模型的神经网络,以深入了解上下文。
这个阶段计算量很大,因为模型需要一次性处理完所有输入的词元,就像人类在回复消息之前,先需要阅读并理解消息中的所有文字。
预填充阶段处理完输入后,就进入实际生成文本的解码阶段。在这个阶段,模型会逐个生成词元以构建完整的输出,称之为自回归过程(每个新词元都依赖于所有先前的词元)。这一阶段包含了针对每个新词元执行的多个关键步骤:
- 注意力计算:回顾所有先前的词元以理解上下文;
- 概率计算:确定下一个可能出现的词元的概率;
- 词元选择:根据这些概率选择下一个词元;
- 持续性检查:决定是否继续或停止生成。
此阶段会占用大量内存,因为模型需要跟踪所有先前已经生成的词元以及它们之间的关系。
采样策略
在模型生成过程中,就像作家可以选择更具创意还是更精确一样,我们也可以调整模型选择词元的方式。当模型生成下一个词元时,它首先会得到词汇表中每个词的原始概率(称为logits),然后基于这些概率来选择下一个词元,这个过程包含以下几个步骤:
- 原始概率:可以将其视为模型对每个可能的下一个词的初始直觉。
- 温度控制(Temperature Control):就像控制创造力的旋钮,设置较高的值(>1.0)会使选择更随机、更具创造性,而较低的值(<1.0)则会使选择更集中、更具确定性。
- Top-p 采样(核采样):不考虑所有可能的词语,而是只关注那些概率总和达到选定阈值的最可能词语(例如前 90%)。
- Top-k 过滤:一种替代方法,只考虑最有可能的 k 个下一个词。
此外,大语言模型面临的一个常见挑战是重复性问题,即生成重复的内容。为了解决这个问题,通常可以采用两种惩罚机制:
- 出现惩罚(Presence Penalty):对任何已出现过的词元,无论其出现频率如何都施加固定惩罚,从而防止模型重复使用相同的词;
- 频度惩罚(Frequency Penalty):根据词元使用频率递增的惩罚机制,一个词出现得越多,再次被选中的可能性就越小。
这些惩罚项会在词元选择的早期阶段就被应用,从而在其他采样策略实施之前就调整原始概率。可以被视为一种温和的引导,鼓励模型探索新的词汇。
最后,考虑到局部最优解未必是全局最优解,如果每次只是简单地选择当前最合适的词元,未必能获得全局质量最好的生成结果,因此还可以使用束搜索(Beam search),同时生成多个词元序列,最后选择总体概率最高的作为最终输出:
- 在每个步骤中,维护多个候选序列(通常为 5-10 个)。
- 对于每个候选词,计算其成为下一个词元的概率;
- 只保留最可能的序列和后续词元组合;
- 重复此过程,直至达到所需长度或停止;
- 选择总体概率最高的序列作为输出。
束搜索通常能生成更连贯、语法更正确的文本,但需要更多的计算资源。
- 但它其实也是局部最优解,要想输出更合理的答案就可以根据之前所说的调整温度和引入惩罚机制
实际挑战与优化
在实际部署大模型时,通常需要考虑以下几个关键指标:
- 首次响应时间(Time to First Token,TTFT):获得首次响应的时间,这主要受预填充阶段的影响,对于用户体验非常重要。
- 输出每词元所需时间(Time Per Output Token,TPOT):用户衡量生成后续词元的速度,这决定了整体生成速度。
- 吞吐量(Throughput):可以同时处理的请求数量。
- 显存使用情况:GPU 显存的消耗量,这通常会成为实际应用中的主要瓶颈。
此外,有效管理上下文长度是大语言模型推理中最具挑战性的问题之一。虽然更长的上下文可以提供更多信息,但也会带来巨大的成本:内存使用量通常随上下文长度呈二次方增长,而处理速度则通常随上下文长度呈线性下降。例如像 Qwen2.5-1M 这样的新模型支持数百万个 token 的上下文窗口,但这也导致推理速度显著降低,因此关键在于找到适合实际场景的最佳平衡点。
为了应对这些挑战,最有效的优化方法之一是 KV 缓存(Key-Value Caching),通过存储和重用中间计算结果来提高推理速度。这项优化可以减少重复计算,从而提升生成速度,使长上下文生成成为可能。虽然代价是会占用更多内存,但性能提升通常远远超过这一成本。
Transformer详解
- 都是latex公式,就不摘抄了 由于太过专业,因此我自己找AI通俗化了一下:
注意力是什么
注意力机制(Attention Mechanism)的本质是资源的最优分配。它让模型学会从大量信息中,筛选出对当前任务最关键的少数核心信息。
1. 核心逻辑:图书馆借书
要理解注意力,最经典的模型是 Query(查询)、Key(键)、Value(值)。你可以将其想象成在图书馆找书:
- Query (Q):你想找的东西。比如你脑子里的搜索词:“人工智能的历史”。
- Key (K):书架上每本书的标签/书名。模型会计算你的 Query 和每一个 Key 的匹配程度(相关性)。
- Value (V):书里的具体内容。
操作流程:
- 你拿着 Q 去跟所有的 K 比对,发现《AI简史》匹配度 0.9,《高等数学》匹配度 0.1。
- 这个匹配度就是权重(Attention Weight)。
- 最后你带走的知识,就是根据权重加权后的结果:0.9 x
《AI简史》的内容+ 0.1 x《高数》的内容。
2. 为什么需要它?(对比传统方法)
在注意力机制出现之前,机器处理信息像吞枣:
- 传统模型(如 RNN):像一个记性不太好的翻译官。读完一个长句后,他试图把所有信息压缩成一个固定长度的向量。结果就是:读到句尾,句头的信息就模糊了。
- 注意力模型:像一个带着荧光笔的读者。在处理每个词时,它会瞬间扫描全句,把相关的重点划出来。
3. 不同的注意力类型
- 自注意力(Self-Attention):自己跟自己找关系。
- 例子:句子“它在马路上跑,因为它累了”。当处理第二个“它”时,注意力机制会高亮“跑”和“马路”,从而让模型明白这个“它”是指那个运动的物体。
- 交叉注意力(Cross-Attention):在两个不同序列间找关系。
- 例子:翻译时。当准备输出英文单词 “Apple” 时,解码器会去中文原句里寻找权重最高的词——“苹果”。
深入理解注意力机制
Transformer 能够“一眼读完全文”且不丢失信息,主要靠的是位置编码和全连接的并行架构。
1. 为什么它能“一眼读完”?
传统的 RNN 像排队进场,信息必须一个接一个传递,前面的信息在传递过程中会像“传声筒游戏”一样逐渐失真。
Transformer 像航拍全景。它利用矩阵运算,在计算的第一步就让序列中所有的词同时进入模型。
- 物理机制:在自注意力层,每个词都会和全场所有词建立连接。从第 1 个词到第 1000 个词的距离,在矩阵里永远是 $1$。
- 无损传输:因为不存在“中间商”传递,信息是直接从 A 点点对点触达到 B 点的。
2. 既然是一眼读完,怎么知道谁先谁后?
如果只是把词丢进去,模型会觉得“我吃鱼”和“鱼吃我”是一样的。为了解决这个问题,它引入了位置编码(Positional Encoding)。
- 硬性叠加:在词向量进入模型之前,会加上一个代表位置的“指纹”。这个指纹是用余弦和正弦函数生成的独特数值序列。
- 坐标系化:这就好比给每个进场的词发了一个带编号的座位号。
- “我”带上了一个“我是第1位”的属性;
- “鱼”带上了一个“我是第3位”的属性。
- 特征融合:模型在处理时,不仅能看到“鱼”的含义,还能感知到它携带的“第3位”这个特征。
3. 为什么信息不会丢失?
信息丢失通常发生在“压缩”阶段。Transformer 采用以下手段锁定信息:
- 全连接注意力(All-to-All):每一个词在每一层都有机会重新审视全句。即使在第 10 层,它依然可以直接调用第 1 层输入的原始位置信息和语义信息。
- 残差连接(Residual Connection):这是最关键的**“保底机制”**。
- 每一层加工完后,都会把“加工前的原始数据”直接加到“加工后的数据”上。
- 这相当于给信息铺设了多条高速公路。如果某一层加工坏了,原始信息可以直接跳过加工层往后传。
Transformer概览
Transformer 的核心逻辑是放弃了“排队处理数据”,改用全连接矩阵并行运算。它将语言处理变成了一个空间几何问题:通过计算词与词之间的距离和权重,捕捉语义。
1. 输入层:数据数字化
计算机不认识文字,第一步是向量化(Embedding)。
- 词嵌入(Embedding):将每个词映射到一个高维空间的坐标(向量)。意思相近的词,坐标距离更近。
- 位置编码(Positional Encoding):由于 Transformer 是同时读入所有词,它无法区分语序。我们必须给每个词的向量叠加上一个“位置指纹”(通常使用正弦/余弦函数生成),让模型知道谁在谁前面。
2. 核心机制:自注意力(Self-Attention)
这是 Transformer 的“灵魂”。它解决了**“联系”**的问题。
- 计算逻辑:每个词都生成三个身份:Q(查询)、K(键)、V(值)。
- 物理过程:
- 每个词拿自己的 Q 去跟全场所有词的 K 做点积,算出匹配度。
- 匹配度经过 Softmax 变成权重(比如 0.8、0.1…)。
- 根据权重去提取对应的 V(值)。
- 本质:它让每个词在处理时,都能根据上下文自动聚焦到相关的词上。比如在“他过马路”中,“他”会通过注意力强力连接到语境中的具体人物。
3. 编码器(Encoder):特征提取
编码器由 $N$ 个相同的块堆叠而成。
- 多头机制(Multi-Head):并行运行多组自注意力,一组看语法,一组看逻辑,类似于多个人从不同角度审题。
- 残差连接(Residual)与归一化(Norm):每一层加工完都会把原始输入加回来,防止深层网络信息丢失或梯度消失。
- 前馈网络(FFN):对注意力提取的信息进行非线性转换,进一步强化特征。
4. 解码器(Decoder):序列生成
解码器负责预测下一个词,它比编码器多了两样东西:
- 掩码注意力(Masked Attention):训练时把后面的词遮住,强制模型只能根据已有的上文预测未来。
- 交叉注意力(Cross-Attention):解码器会去“盯着”编码器输出的特征矩阵。就像写作文时,一边写(解码),一边看题目要求(编码器的输出)。
5. 输出层:概率映射
- 线性层:将解码器的输出映射回词表大小。
- Softmax:将数值转换为概率。概率最高的那个词,就是模型认为的“下一个词”。
总结:Transformer 为什么强大?
- 并行性:不再像 RNN 那样一个字一个字读,大大缩短了训练时间。
- 长程依赖:因为是全连接,句子开头和结尾的词距离永远是 $1$,不会遗忘。
- 可扩展性:支持模型做大(Scaling Law),参数越多,学到的世界知识就越深邃。
现在的 LLM(如 GPT 系列)多采用 Decoder-Only 架构,即去掉了显式的编码器,让解码器自己处理输入并直接续写。
编码器是什么
将编码器(Encoder)想象成一个**“深度阅读理解器”**。它的任务是将一串单词,通过层层理解,翻译成机器能懂的“思想地图”。
1. 零件拆解:它由什么组成?
如果把编码器比作一个加工车间,它主要有三个工位:
- 特种雷达(自注意力机制):每个词都在扫描全场。比如读到“苹果”这个词,雷达会看周围有没有“好吃”或者“乔布斯”。如果有“乔布斯”,它就把“苹果”理解为科技公司;如果有“好吃”,它就理解为水果。
- 多角度摄像头(多头机制):不只用一个雷达,而是用 8 个或更多。有的看语法,有的看语气,有的看逻辑,最后汇总。
- 深加工机床(前馈网络):雷达看清关系后,机床会对每个词的特征进行非线性强化,把零散的信号固定成深刻的记忆。
2. 运作流程:数据是怎么走的?
- 打标签(位置编码):Transformer 是一眼看完一整行字的,为了不让它分不清词序,进门前先给每个词贴个“我是第1个”、“我是第2个”的编号。
- 找关系(注意力计算):每个词伸出无数条线连接其他词,根据关联程度分配权重。
- 加总与校准(残差与归一化):算完之后,把原始信息和加工后的信息加在一起(怕算丢了),然后把数值拉回到一个标准范围,防止网络“走火入魔”。
3. 本质区别:为什么它更强?
- RNN(老方法):像一个学生背课文,读了后面忘前面,且必须一个字一个字读。
- Encoder(新方法):像摄影师拍全景。一眼望去,所有的词同时入画,所有的联系瞬间建立。
4. 结论
编码器的最终输出不是词,而是一组有“灵魂”的向量。这些向量已经不再是孤立的符号,而是吸收了整句话上下文精华的特征集合。
解码器是什么
1. 结构本质:一个“定向生成器”
如果说编码器是理解全文,解码器(Decoder)则是根据理解,逐字产出。它在编码器的基础上多了一个关键组件:交叉注意力(Cross-Attention)。
2. 核心工作机制
- 带掩码的自注意力(Masked Self-Attention):
- 物理约束:生成时,模型不能“偷看”未来的词。
- 实现:通过掩码(Mask)屏蔽掉当前时刻之后的词,确保预测第 $n$ 个词时,只参考前 $n-1$ 个词。
- 交叉注意力(Cross-Attention):
- 桥梁作用:这是解码器最核心的工位。它一边看着已经生成的词,一边盯着编码器传过来的“思想地图”(特征向量)。
- 逻辑:它在问编码器:“根据你刚才理解的原文,我现在写到这一步了,下一步最该接哪个信息?”
- 线性层与 Softmax:
- 将高维向量映射到词表大小的维度,通过概率分布选出得分最高的词。
3. 数据流向:从“过去”和“原文”中找答案
- 输入:输入的是已经生成出来的词(起始符或前文)。
- 自我对齐:通过 Masked Attention 整理已生成内容的逻辑。
- 吸取原文:通过 Cross-Attention 强行去对齐原文的重点。
- 预测输出:产出一个概率,选出一个词,然后把这个词再丢回输入端,循环往复。
4. 通俗比喻:像是在写“命题作文”
- 编码器(出题人):把复杂的背景资料读完,提炼出一张写满考点的纸。
- 解码器(考生):
- 他右手拿着已经写好的半篇作文(已生成的词);
- 左手按着出题人的考点纸(编码器输出);
- 他一边看左手确认别跑题,一边看右手确认逻辑连贯,最后写出下一个字。
新型模型架构
- 混合专家架构(Mixture-of-Experts,MoE): 将Transformer模块中的特定前馈层替换成MoE层,即换成具有不同权重参数的独立网络(称为专家),对于每次输入,选取概率最高的k个专家进行激活,然后加权输出
- 状态空间模型(State Space Model,SSM): 试图取代Transformer模型,性能依然有差距,代表模型有RetNet,Mamba等.
Transformer库使用
Transformers 库将目前的 NLP 任务归纳为几下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER) 等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等。
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
- feature-extraction:获得文本的向量化表示
- fill-mask:填充被遮盖的词、片段
- ner:命名实体识别
- question-answering:自动问答
- sentiment-analysis:情感分析
- summarization:自动摘要
- text-generation:文本生成
- translation:机器翻译
- zero-shot-classification:零训练样本分类
情感分析
断更原因
后面的论述和代码过于专业了,不是我现在能看得懂的,显然这并不是真正的快速入门.
设计数据密集型应用
数据系统
数据系统有以下几个作用:
- 存储数据,以便自己或其他应用程序之后能再次找到 (数据库,即 databases)
- 记住开销昂贵操作的结果,加快读取速度(缓存,即 caches)
- 允许用户按关键字搜索数据,或以各种方式对数据进行过滤(搜索索引,即 search indexes)
- 向其他进程发送消息,进行异步处理(流处理,即 stream processing)
- 定期处理累积的大批量数据(批处理,即 batch processing) 因此,常规的数据库,消息队列等信息处理系统都可以被归类为数据系统.
我们可以从三个维度来评价一个数据系统写的怎么样:
- 可靠性: 出了故障仍然可以正常运行
- 可伸缩性: 能够应付系统的扩大和其他变化
- 可维护性: 架构清晰,职责分明,方便维护
可靠性
处理硬件故障
当想到系统失效的原因时,硬件故障(hardware faults) 总会第一个进入脑海。硬盘崩溃、内存出错、机房断电、有人拔错网线…… 任何与大型数据中心打过交道的人都会告诉你:一旦你拥有很多机器,这些事情总会发生!
我们可以通过硬件冗余(redundancy of hardware)来解决这个问题,即提供后备组件来及时接替故障硬件,防止系统崩溃.
软件故障
软件故障有以下几个例子:
- 接受特定的错误输入,便导致所有应用服务器实例崩溃的 BUG。例如 2012 年 6 月 30 日的闰秒,由于 Linux 内核中的一个错误,许多应用同时挂掉了。
- 级联故障,一个组件中的小故障触发另一个组件中的故障,进而触发更多的故障
管理员的失误导致的故障
一项关于大型互联网服务的研究发现,运维配置错误是导致服务中断的首要原因,而硬件故障(服务器或网络)仅导致了 10-25% 的服务中断
可伸缩性
系统今天能可靠运行,并不意味未来也能可靠运行。服务 降级(degradation) 的一个常见原因是负载增加,例如:系统负载已经从一万个并发用户增长到十万个并发用户,或者从一百万增长到一千万。也许现在处理的数据量级要比过去大得多
负载: 以推特为例
以推特在 2012 年 11 月发布的数据为例,推特的两个主要业务是:
- 发布推文
- 用户可以向其粉丝发布新消息(平均 4.6k 请求 / 秒,峰值超过 12k 请求 / 秒)。
- 主页时间线
- 用户可以查阅他们关注的人发布的推文(300k 请求 / 秒)。
大体上讲,这一对操作有两种实现方式。
- 发布推文时,只需将新推文插入全局推文集合即可。当一个用户请求自己的主页时间线时,首先查找他关注的所有人,查询这些被关注用户发布的推文并按时间顺序合并。在如 图 1-2 所示的关系型数据库中,可以编写这样的查询:
| |
- 为每个用户的主页时间线维护一个缓存,就像每个用户的推文收件箱。当一个用户发布推文时,查找所有关注该用户的人,并将新的推文插入到每个主页时间线缓存中。因此读取主页时间线的请求开销很小,因为结果已经提前计算好了。
推特的第一个版本使用了方法 1,但系统很难跟上主页时间线查询的负载。所以公司转向了方法 2,方法 2 的效果更好,因为发推频率比查询主页时间线的频率几乎低了两个数量级,所以在这种情况下,最好在写入时做更多的工作,而在读取时做更少的工作。
然而方法 2 的缺点是,发推现在需要大量的额外工作。平均来说,一条推文会发往约 75 个关注者,所以每秒 4.6k 的发推写入,变成了对主页时间线缓存每秒 345k 的写入。但这个平均值隐藏了用户粉丝数差异巨大这一现实,一些用户有超过 3000 万的粉丝,这意味着一条推文就可能会导致主页时间线缓存的 3000 万次写入!及时完成这种操作是一个巨大的挑战 —— 推特尝试在 5 秒内向粉丝发送推文。
推特轶事的最终转折:现在已经稳健地实现了方法 2,推特逐步转向了两种方法的混合。大多数用户发的推文会写入其粉丝主页时间线缓存中。但是少数拥有海量粉丝的用户(即名流)会被排除在外。当用户读取主页时间线时,分别地获取出该用户所关注的每位名流的推文,再与用户的主页时间线缓存合并
如何处理负载
适应某个级别负载的架构不太可能应付 10 倍于此的负载。如果你正在开发一个快速增长的服务,那么每次负载发生数量级的增长时,你可能都需要重新考虑架构 —— 或者更频繁。
大规模的系统架构通常是应用特定的 —— 没有一招鲜吃遍天的通用可伸缩架构(不正式的叫法:万金油(magic scaling sauce) )。应用的问题可能是读取量、写入量、要存储的数据量、数据的复杂度、响应时间要求、访问模式或者所有问题的大杂烩。
举个例子,用于处理每秒十万个请求(每个大小为 1 kB)的系统与用于处理每分钟 3 个请求(每个大小为 2GB)的系统看上去会非常不一样,尽管两个系统有同样的数据吞吐量。
可维护性
众所周知,软件的大部分开销并不在最初的开发阶段,而是在持续的维护阶段,包括修复漏洞、保持系统正常运行、调查失效、适配新的平台、为新的场景进行修改、偿还技术债和添加新的功能。
数据模型
多数应用使用层层叠加的数据模型构建。对于每层数据模型的关键问题是:它是如何用低一层数据模型来 表示 的?例如:
- 作为一名应用开发人员,你观察现实世界(里面有人员、组织、货物、行为、资金流向、传感器等),并采用对象或数据结构,以及操控那些数据结构的 API 来进行建模。那些结构通常是特定于应用程序的。
- 当要存储那些数据结构时,你可以利用通用数据模型来表示它们,如 JSON 或 XML 文档、关系数据库中的表或图模型。
- 数据库软件的工程师选定如何以内存、磁盘或网络上的字节来表示 JSON / XML/ 关系 / 图数据。这类表示形式使数据有可能以各种方式来查询,搜索,操纵和处理。
- 在更低的层次上,硬件工程师已经想出了使用电流、光脉冲、磁场或者其他东西来表示字节的方法。
握一个数据模型需要花费很多精力(想想关系数据建模有多少本书)。即便只使用一个数据模型,不用操心其内部工作机制,构建软件也是非常困难的。然而,因为数据模型对上层软件的功能(能做什么,不能做什么)有着至深的影响,所以选择一个适合的数据模型是非常重要的。
关系模型VS文档模型
关系模型曾是一个理论性的提议,当时很多人都怀疑是否能够有效实现它。然而到了 20 世纪 80 年代中期,关系数据库管理系统(RDBMSes)和 SQL 已成为大多数人们存储和查询某些常规结构的数据的首选工具。关系数据库已经持续称霸了大约 25~30 年 —— 这对计算机史来说是极其漫长的时间。
关系数据库起源于商业数据处理,在 20 世纪 60 年代和 70 年代用大型计算机来执行。从今天的角度来看,那些用例显得很平常:典型的 事务处理(将销售或银行交易,航空公司预订,库存管理信息记录在库)和 批处理(客户发票,工资单,报告)。
NoSQL
采用 NoSQL 数据库的背后有几个驱动因素,其中包括:
- 需要比关系数据库更好的可伸缩性,包括非常大的数据集或非常高的写入吞吐量
- 相比商业数据库产品,免费和开源软件更受偏爱
- 关系模型不能很好地支持一些特殊的查询操作
常见的NoSQL数据库有以下几个:
- Redis: 基于内存的存储,核心逻辑是哈希表
- MongoDB: 存储格式为JSON
文档和关系数据库的融合
随着时间的推移,关系数据库和文档数据库似乎变得越来越相似,这是一件好事:数据模型相互补充,如果一个数据库能够处理类似文档的数据,并能够对其执行关系查询,那么应用程序就可以使用最符合其需求的功能组合。
- (26/4/7): 我发现这本书我现在看太早了,很难有切实的收获,还是等几年再来探索吧
Docker 从入门到实践
比官方文档要简洁清晰的多
入门部分
Docker简介
无论你的应用是用 Python、Java、Node.js 还是其他语言写的,无论它需要什么样的依赖库和环境,一旦被打包成 Docker 镜像,就可以用同样的方式在任何支持 Docker 的机器上运行.
- 也就是说,通过将依赖和软件打包在一起,我们成功实现了无缝的跨环境运行
Docker不是虚拟机
传统虚拟机技术是虚拟出一套完整的硬件,在其上运行一个完整的操作系统,再在该系统上运行应用
而 Docker 容器内的应用直接运行于宿主的内核,容器内没有自己的内核,也没有进行硬件虚拟
Docker历史
Docker 最初是 dotCloud 公司创始人 Solomon Hykes 在法国期间发起的一个公司内部项目,于 2013 年 3 月以 Apache 2.0 授权协议开源
- 很难想象这么优秀的技术竟然只有十年多一点的历史
Docker的核心优势
环境一致性
Docker 镜像包含了应用运行所需的 一切:代码、运行时、系统工具、库、配置。这意味着:
- 开发环境和生产环境完全一致
- 不会再有 “在我机器上能跑” 的问题
快速启动
传统虚拟机启动需要几分钟 (引导操作系统),而 Docker 容器启动通常只需要 几秒甚至几百毫秒
- 当然这得要你先构建好了镜像和容器
Docker 的核心价值可以用一句话概括:让应用的开发、测试、部署保持一致,同时极大提高资源利用效率。 笔者认为,对于现代软件开发者来说,Docker 已经不是 “要不要学” 的问题,而是 必备技能。无论你是前端、后端、运维还是全栈开发者,掌握 Docker 都能让你的工作更高效。
基本概念
Docker里有三个基本概念:
- 镜像(Image): Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数 (如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
- 容器 (Container):镜像 (Image) 和容器 (Container) 的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库 (Repository):镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
镜像
Docker 镜像是一个只读的模板,包含了运行应用所需的一切:代码、运行时、库、环境变量和配置文件。 如果用一个类比:镜像就像是一张光盘或 ISO 文件。你可以用同一张光盘在不同电脑上安装系统,而光盘本身不会被修改。同样,一个镜像可以创建多个容器,而镜像本身保持不变。
镜像的组成部分
| 类别 | 示例 |
|---|---|
| 程序文件 | 应用二进制文件、Python/Node 解释器 |
| 库文件 | libc、OpenSSL、各种依赖库 |
| 配置文件 | nginx.conf、my.cnf 等 |
| 环境变量 | PATH、LANG 等预设值 |
| 元数据 | 启动命令、暴露端口、数据卷定义 |
- 镜像是只读的
- 镜像不包含动态数据
- 镜像构建后内容不会改变
镜像的分层存储
| |
换句话说,只要某一行命令对镜像做了修改,就被docker视为单独的一个构建层,不可以被其他构建层修改,但可以与其他镜像共享
镜像标识
镜像名称和标签
| |
镜像ID
| |
镜像摘要 镜像摘要是基于镜像内容生成的哈希码
| |
容器
容器是镜像的运行实例。如果把镜像比作程序,那么容器就是进程。 用面向对象编程的术语来说:镜像是类 (Class),容器是对象 (Instance)。
容器的本质
笔者认为,理解这一点是理解 Docker 的关键:容器的本质是一个特殊的进程
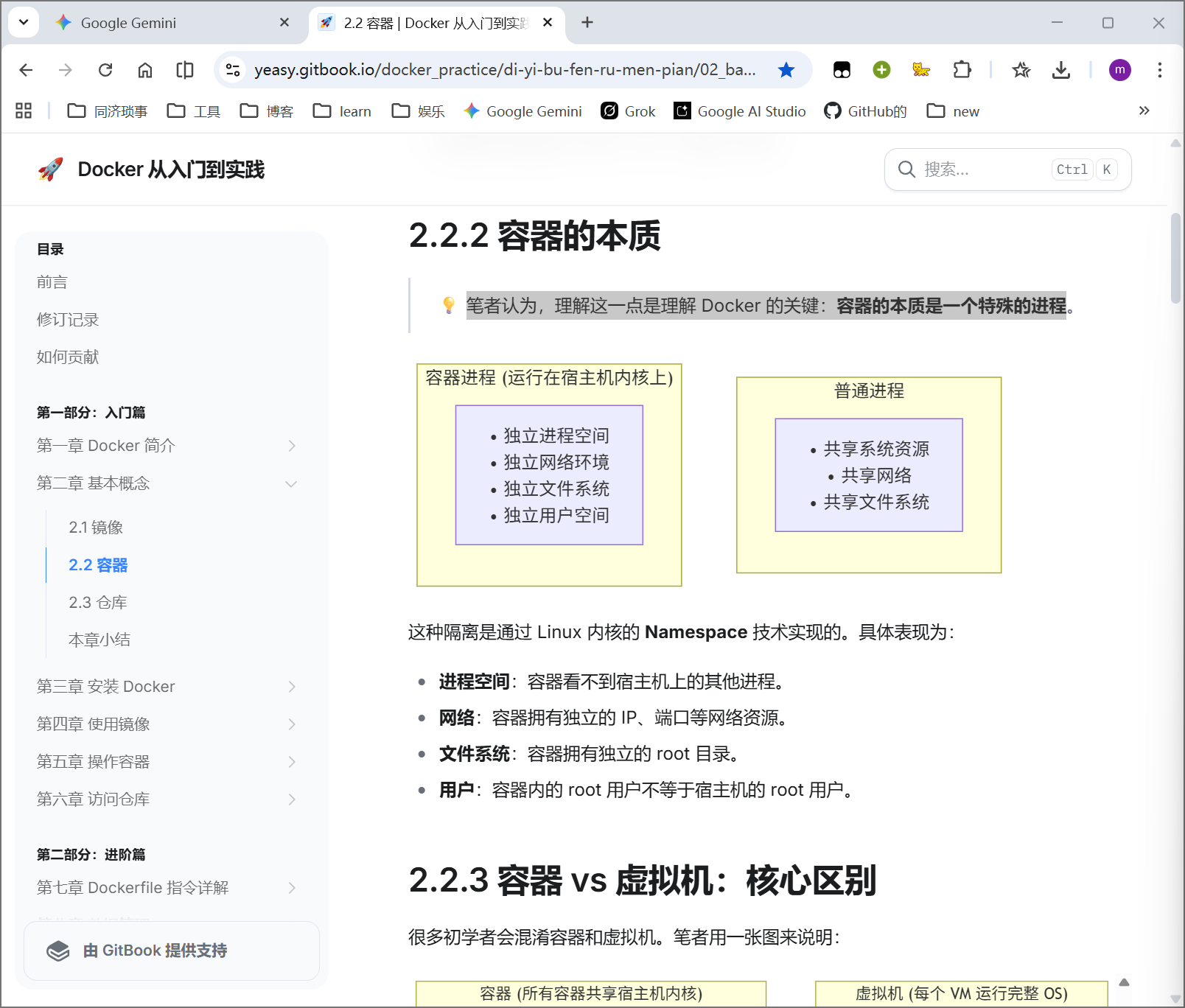
这种隔离是通过 Linux 内核的 Namespace 技术实现的。具体表现为:
- 进程空间:容器看不到宿主机上的其他进程。
- 网络:容器拥有独立的 IP、端口等网络资源
- 文件系统:容器拥有独立的 root 目录。
- 用户:容器内的 root 用户不等于宿主机的 root 用户。
容器的存储层机制
当容器运行时,Docker 会在镜像的只读层之上创建一个可写层(容器存储层);
而当容器需要修改镜像层中的文件时:
- Docker将该文件复制到容器存储层
- 在容器存储层中进行修改
- 原始镜像层保持不变
| |
既然当容器被删除后数据就全部丢失,那么容器存储层就不应该保留任何重要的信息,而是只保留运行时数据.
- 如果我们想要存储数据,可以使用数据卷(Volume)来存储数据库和应用数据,或者使用绑定到宿主机的目录.
| |
容器的生命周期
| |
仓库
Docker Registry 是存储和分发 Docker 镜像的服务,类似于代码的 GitHub 或包管理的 npm。
Docker Registry 中可以包含多个 Repository,每个 Repository 可以包含多个 Tag:
| 概念 | 说明 | 示例 |
|---|---|---|
| Registry | 存储镜像的服务 | Docker Hub、ghcr.io |
| Repository (仓库) | 同一软件的镜像集合 | nginx、mysql、mycompany/myapp |
| Tag (标签) | 仓库内的版本标识 | latest、1.25、alpine |
一个完整的 Docker 镜像名称由 Registry 地址、用户名/组织名、仓库名和标签组成。了解其结构有助于我们更准确地定位镜像。基本格式如下:
[registry 地址/][用户名/]仓库名[:标签]
完整示例如下:
| |
公共 Registry
Docker Hub 是最大的公共 Registry,也是 Docker 的默认 Registry,有以下特点:
- 拥有大量官方镜像(nginx、mysql、redis)
- 免费账户可以创建公开仓库
- 付费账户支持私有仓库
除了 Docker Hub,还有以下几个常见的公共 Registry:
| Registry | 地址 | 说明 |
|---|---|---|
| GitHub Container Registry | ghcr.io | GitHub 提供,与 GitHub Actions 集成好 |
| Google Container Registry | gcr.io | Google Cloud 提供,Kubernetes 镜像常用 |
| Quay.io | quay.io | Red Hat 提供 |
| 阿里云容器镜像服务 | registry.cn-*.aliyuncs.com | 国内访问快 |
| 腾讯云容器镜像服务 | ccr.ccs.tencentyun.com | 国内访问快 |
安装docker
如果是Windows端,开启WSL2后下载官方软件即可运行 如果是Linux端,尽管文章里给了一堆命令,但现在有Dokploy了.如果是部署在国外服务器上或者自己学习使用的话,使用Dokploy就没必要操心那么多了.
Dokploy
支持Dokploy的目前有以下服务器厂商:
- Hostinger
- AmericanCloud
- Teramont
- Hetzner
- DigitalOcean
- Vultr
- Linode
- Scaleway
- Google Cloud
- AWS 而Dokploy目前可以在以下系统里部署:
- Ubuntu 24.04 LTS
- Ubuntu 23.10
- Ubuntu 22.04 LTS
- Ubuntu 20.04 LTS
- Ubuntu 18.04 LTS
- Debian 12
- Debian 11
- Debian 10
- Fedora 40
- Centos 9
- Centos 8
换句话说,主流的Linux操作系统现在都支持Dokploy了
Dokploy is a stable, easy-to-use deployment solution designed to simplify the application management process. Think of Dokploy as your free self hostable alternative to platforms like Heroku, Vercel, and Netlify, leveraging the robustness of Docker and the flexibility of Traefik.
- Dokploy本身就是为了简化在Linux服务器部署Docker而产生的
Dokploy utilizes Docker, so it is essential to have Docker installed on your server. If Docker is not already installed, Dokploy’s installation script will install it automatically.
- 甚至都不用提前安装docker,易用性可见一斑
部署
前置要求
To ensure a smooth experience with Dokploy, your server should have at least 2GB of RAM and 30GB of disk space. This specification helps to handle the resources consumed by Docker during builds and prevents system freezes.
- 官方推荐使用Hetzner的服务器来省钱
避免以下端口被占用:
- Port 80: HTTP traffic (used by Traefik)
- Port 443: HTTPS traffic (used by Traefik)
- Port 3000: Dokploy web interface
我们只需要运行以下命令便可以在服务器的3000端口访问dokploy界面:
| |
第一次进入dokploy界面时需要我们注册管理员账户,然后就可以在面板里部署自己的docker项目了,要进一步了解的话还是去看官方文档吧.
使用镜像
获取镜像
docker pull用于从镜像仓库获取镜像:
| |
镜像名称的标准格式如下:
| |
| 组成部分 | 说明 | 默认值 |
|---|---|---|
| Registry 地址 | 镜像仓库服务的域名或 IP 地址 | docker.io (Docker Hub) |
| 用户名 | 镜像所属的用户、组织或命名空间 | library (官方镜像默认路径) |
| 仓库名 | 镜像的具体名称 | 必须指定 |
| 标签 (Tag) | 镜像的版本标识或分类标签 | latest |
示例
| |
- 镜像是分层下载的,如果本地已经有相同的层(这可以通过ID来识别),那么就会跳过该层继续下载
docker pull常用参数
| 选项 | 说明 | 示例 |
|---|---|---|
| –all-tags, -a | 下载仓库中该镜像的所有版本标签 | docker pull -a ubuntu |
| –platform | 在多架构镜像中指定运行平台(如 arm64, amd64) | docker pull --platform linux/arm64 nginx |
| –quiet, -q | 静默模式,只输出镜像 ID,不显示拉取进度详情 | docker pull -q nginx |
管理镜像
docker image ls
基本用法
| |
| 字段 | 说明 |
|---|---|
| REPOSITORY | 镜像仓库名称 |
| TAG | 镜像的标签(通常代表版本号) |
| IMAGE ID | 镜像的唯一标识符(取 SHA-256 哈希值的前 12 位) |
| CREATED | 镜像在构建服务器上被创建的时间 |
| SIZE | 镜像解压后在本地磁盘占用的实际空间 |
- 上面的 ubuntu:24.04 和 ubuntu:noble 拥有相同的 IMAGE ID——它们是同一个镜像的不同标签,只占用一份存储空间。
查找镜像
可以根据名字来找镜像:
| |
镜像删除
docker rmi/docker image rm
这两个命令等价,用于删除单个镜像: 使用ID删除
| |
使用镜像名删除
| |
- Untagged:移除镜像标签
- Deleted: 删除镜像的存储层
docker image prune
| |
- 虚悬镜像 (dangling):没有标签且未被容器引用的镜像,通常是旧版本被新版本覆盖后产生的
操作容器
启动容器
由于 Docker 容器非常轻量,实际使用中常常是随时删除和新建容器,而不是反复重启同一个容器。
基本语法
| |
基本例子
| |
基础选项
| 选项 | 说明 | 示例 |
|---|---|---|
-d | 后台运行容器(detach) | docker run -d nginx |
-it | 分配交互式终端 | docker run -it ubuntu bash |
--name | 为容器指定自定义名称 | docker run --name myapp nginx |
--rm | 容器退出后自动删除 | docker run --rm ubuntu echo hi |
端口映射
| |
运行容器
当你在终端运行一个程序时,有两种模式:
前台运行:程序占用当前终端,输出直接显示,关闭终端程序就停止 后台运行:程序在后台执行,不占用终端,终端关闭也不影响程序 Docker 容器默认是 前台运行 的。使用 -d (detach) 参数可以让容器在后台运行
前台运行
| |
容器会把输出的结果 (STDOUT) 打印到宿主机上面。此时:
- 终端被占用,无法执行其他命令
- 按 Ctrl+C 会终止容器
- 关闭终端窗口,容器也会停止
后台运行
| |
使用 -d 参数后:
- 容器在后台运行
- 返回容器的完整 ID
- 终端立即释放,可以继续执行其他命令
- 输出不会直接显示 (需要用 docker logs 查看)
终止容器
终止容器有三种方式:
| 方式 | 命令 | 说明 |
|---|---|---|
| 优雅停止 | docker stop | 先发 SIGTERM,超时后发 SIGKILL |
| 强制停止 | docker kill | 直接发送 SIGKILL 信号 |
| 自动终止 | - | 容器主进程退出时自动停止 |
我们还可以在镜像被修改后重启容器
| |
删除容器
随着容器的创建和停止,系统中会积累大量的容器。
使用 docker rm 删除已停止的容器:
| |
- 该命令与docker container rm等效
使用 docker container prune 批量删除:
| |
补充部分: 镜像的文件结构
非常离谱的是,这么详细的文档偏偏没有提到这一点: 镜像内部是怎么存放文件的? 自然,镜像是分层构建存储的,但是这些构建层显然要有个地方放吧.
镜像的默认工作目录是根目录,类似于Linux的根目录,当我们需要切换存储目录或者启动某个目录下的脚本时,,可以显式指明,比如说以下的几个命令:
| |
- 如此一来,我们成功的将本地文件复制到了app文件夹中.
因此,镜像不仅仅是一个iso,我们可以把它抽象成一个文件系统,存储层堆叠在不同的目录中,可以来回切换访问.
进阶部分
dockerfile编写
概览
Dockerfile 是一个文本文件,其内包含了一条条的 指令 (Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
Dockerfile不是脚本,而是镜像的"设计图”。这个区别决定了你如何思考每条指令的作用:
- 合并命令:应将
RUN apt-get update && apt-get install -y ...写入同一个RUN指令中,因为它们是同一层的逻辑 - 优化镜像大小:最后才清理缓存、删除临时文件,让这些"瘦身"操作在同一层完成
(补充)FROM: 基础镜像
很多时候我们都需要在官方镜像的基础上进行构建,这个时候我们可以这么写:
| |
这个AS与python中的as一样,都是为导入的镜像重新设一个名字.
- 事实上,如果你不写任何FROM,根本无法运行任何Linux命令
而FROM命令最厉害的地方在于,每一个FROM指令都会重新开辟一个新的文件系统,取代之前的所有内容. 因此,我们可以这么写:
| |
这样既可以利用上一个阶段的构建内容,又不会将多余的内容打包进镜像
RUN: 执行命令
RUN 是 Dockerfile 中最常用的指令,主要用于在镜像构建阶段执行命令来修改镜像,有以下几个应用场景:
- 安装依赖:
RUN apt-get install nginx - 编译程序:
RUN gcc -o app main.c - 下载文件:
RUN curl -O https://example.com/file.tar.gz - 配置系统:
RUN mkdir -p /app/data
理解 RUN 的核心是理解镜像分层:每一个 RUN 都会在当前层之上创建新的一层,这会影响镜像大小。因此,合理使用 RUN(特别是合并多个 RUN)是构建轻量级镜像的关键。
基本语法
有两种格式:
| |
shell格式
| |
- 默认通过 /bin/sh -c 执行。
- 可以使用环境变量、管道、重定向等 Shell 特性。
exec格式
| |
- 直接调用可执行文件,不经过 Shell。
- 无法使用 $VAR 环境变量替换 (除非显式调用 shell)
实战
由于每一个 RUN 指令都会新建一层镜像。为了减少镜像体积和层数,应使用 && 连接命令:
| |
- 可以看到dockerfile将\用于换行,这与makefile的写法一致
COPY: 复制文件
COPY 是在构建镜像时,将构建上下文(Dockerfile 所在目录及其子目录)中的文件或目录复制到镜像内的指令。它是处理应用代码、配置文件最常用的方式,应用场景如下:
COPY . /app(应用源码)COPY nginx.conf /etc/nginx/nginx.conf(配置文件)COPY public /app/public(静态资源)
基本语法
| |
复制文件
| |
复制目录
| |
指定路径
| |
dockerignore
排除不需要复制的文件,精简镜像体积
| |
实战
| |
详细解释一下,docker构建镜像是线性操作的,只有COPY,RUN,ADD三种命令会创建新的存储层,而每次构建时docker都会在本地存储缓存,如果下一次构建镜像时对应的命令没有变化,则会直接复用原来的缓存,不会重新构建;当docker发现COPY的文件内容有改动时,该行之后的所有命令被视为与原缓存不同,需要重新构建.
因此,如果直接写COPY . .的话,修改任何一个文件后构建镜像都要重新运行npm install;但如果把COPY . .放在后面,只会在package.json变化时重新构建.
ADD: 更高级的COPY
实践中的建议:除非你明确需要自动解压功能(比如官方基础镜像构建根文件系统),否则始终使用 COPY。原因很简单——显式优于隐式。你的 Dockerfile 在 6 个月后被接手维护时,清晰的意图会让团队少走很多弯路。
基本用法
| |
ADD 在 COPY 基础上增加了两个功能:
- 自动解压 tar 压缩包
- 支持从 URL 下载文件 (不推荐)
CMD: 容器启动命令(4/10)
在深入 CMD 的细节之前,我们需要理解一个关键问题:CMD 和 ENTRYPOINT 应该在什么时候使用?
这是 Dockerfile 使用中最常见的困惑之一。简单的答案是:
- CMD:定义容器的”默认命令”。如果用户在 docker run 时提供命令,CMD 会被覆盖
- ENTRYPOINT:定义容器的”入口脚本”。通常用于启动应用的某个特定部分
基本用法
CMD指令用于指定容器启动时默认执行的命令。它定义了容器的 “主进程”。
| 格式类型 | 语法示例 | 推荐程度 | 核心机制 |
|---|---|---|---|
| Exec 格式 | CMD ["executable", "param1", "param2"] | ✅ 推荐 | 直接由内核执行,PID 为 1,可接收 SIGTERM 信号。 |
| Shell 格式 | CMD command param1 param2 | ⚠️ 简单场景 | 通过 /bin/sh -c 调用,无法直接接收信号,环境变量会被解析。 |
| 参数格式 | CMD ["param1", "param2"] | ⚓ 配合使用 | 仅作为 ENTRYPOINT 的默认参数传递。 |
exec 格式
| |
shell格式
| |
实际执行:会被包装为 sh -c
| |
- 换句话说shell写法实际上是使用了sh的exec简写格式.
CMD命令只能写一个
多个CMD只有最后一个生效. 因为CMD的PID为1,意思是在Linux内核中它作为根进程,是独一无二的.因此CMD一旦停止,容器就关闭了.
ENTRYPOINT: 入口点(4/11)
如果说 CMD 是"容器中的默认程序",那么 ENTRYPOINT 就是"把容器变成一个命令"。这个思维转变决定了你何时使用 ENTRYPOINT。
是什么,怎么用
ENTRYPOINT 指定容器启动时运行的入口程序。与 CMD 不同,ENTRYPOINT 定义的命令不会被 docker run 的参数覆盖,而是 接收这些参数。
基本语法
| |
ENV: 设置环境变量
- 很好理解,就是设置了一个dockerfile中的变量而已.
| |
例子
| |
用法
使用 -e 或 –env 覆盖 Dockerfile 中定义的环境变量:
| |
运行时传入密码:
| |
使用docker compose的话就没必要考虑这么多了
ARG: 构建参数
ARG仅在构建时生效,用于传递版本号之类的信息,可以出现在FROM指令之前,也能在docker build阶段传入对应的参数.换句话说,我们可以更改构建初始镜像所用的版本号.
而ENV则会被打包进入镜像,在容器运行期间永久生效,也不能出现在FROM指令之前. 基本语法
| |
用法
| |
VOLUME: 定义匿名卷
是什么,怎么用
容器存储层应该保持无状态,任何运行时数据都应该存储在volume中。
| |
volume的行为
自动创建匿名卷 如果运行时未指定挂载,Docker 会自动创建匿名卷:
| |
会被命名卷覆盖
| |
VOLUME 之后对该目录的修改会被丢弃!
| |
原因:在构建过程中,VOLUME 指令会为该目录创建一个临时的匿名卷。后续 RUN 指令对该目录的写入实际发生在这个临时卷中,而非镜像层。当该 RUN 指令结束后,临时卷被丢弃,因此写入的内容不会保存到最终镜像中。注意:这与容器运行时创建的匿名卷是不同的——运行时创建的卷会在容器生命周期内持续存在。
正确做法
| |
在compose中使用
| |
EXPOSE: 暴露端口(4/12)
是什么,怎么用
EXPOSE 声明容器运行时提供服务的端口。这是一个文档性质的声明,告诉使用者容器会监听哪些端口。
- 换句话说只起一个约定作用,不通过-p的话不会起作用
基本用法
| |
使用 docker run -P 时,Docker 会自动映射 EXPOSE 的端口到宿主机随机端口:
| |
实战
| |
| |
compose中的编写
| |
WORKDIR: 指定工作目录
WORKDIR 指定后续指令的工作目录。如果目录不存在,Docker 会自动创建。
基本用法
| |
| |
实战
使用绝对命令
| |
USER: 指定当前用户
是什么,怎么用
USER 指令切换后续指令 (RUN、CMD、ENTRYPOINT) 的执行用户
| |
- 一般是用不上这个的
HEALTHCHECK: 健康检查
是什么,怎么用
HEALTHCHECK 指令告诉 Docker 如何判断容器状态是否正常。这是保障服务高可用的重要机制。
| |
基本用法
| |
| 选项 | 说明 | 默认值 |
|---|---|---|
--interval | 两次检查的间隔 | 30s |
--timeout | 检查命令的超时时间 | 30s |
--start-period | 启动缓冲期 (期间失败不计入次数) | 0s |
--retries | 连续失败多少次标记为 unhealthy | 3 |
应用启动可能需要时间 (如 Java 应用)。设置 –start-period 可以防止在启动阶段因检查失败而误判
| |
LABEL: 为镜像添加元数据
是什么,怎么用
LABEL 指令以键值对的形式给镜像添加元数据。这些数据不会影响镜像的功能,但可以帮助用户理解镜像,或被自动化工具使用。
- 版本管理:记录版本号、构建时间、Git Commit ID
- 联系信息:维护者邮箱、文档地址、支持渠道
- 自动化工具:CI/CD 工具可以读取标签触发操作
- 许可证信息:声明开源协议
| |
| |
数据管理
这一章介绍如何在 Docker 内部以及容器之间管理数据,在容器中管理数据主要有以下几种方式:
- 数据卷
- 挂载主机目录
- tmpfs 挂载
数据卷
容器的存储层有一个关键问题:容器删除后,数据就没了。数据卷 (Volume) 解决了这个问题,它的生命周期独立于容器。
创建和查看数据卷
| |
关键字段:
- Mountpoint:数据卷在宿主机上的实际存储位置
- Driver:存储驱动 (默认 local,也可以用第三方驱动)
挂载数据卷
方式一:–mount:推荐
| |
| 参数 | 说明 |
|---|---|
source | 数据卷名称 (不存在会自动创建) |
target | 容器内挂载路径 |
readonly | 可选,只读挂载 |
| 方式二:-v:简写 |
| |
提示:官方更推荐使用 –mount。除了语法格式可读性更好之外,最重要的行为差异发生在 绑定挂载 (Bind Mount) 时:如果挂载的宿主机源路径尚未存在,-v 会擅自将其自动创建为一个空目录;而 –mount 则会严格检查并直接报错。这能有效避免因路径拼写错误而在宿主机上留下垃圾目录(以及导致的容器访问空目录问题)。而对于本节的 数据卷 (Volume) 挂载而言,两者在目标指定的卷不存在时皆会自动创建卷,产生的结果是 完全一致 的。
实战
数据库持久化
| |
多容器共享数据
| |
配置文件持久化
| |
挂载主机目录
绑定挂载
Bind Mount (绑定挂载) 将 Docker daemon 所在主机 上的目录或文件直接挂载到容器中。容器可以读写这台主机上的文件系统。 Bind Mount vs Volume
特性 Bind Mount (绑定挂载) Volume (数据卷) 数据位置 宿主机任意路径 Docker 管理的特定目录 ( /var/lib/docker/volumes/)路径指定 必须是绝对路径 (如 /opt/app/data)卷名 (如 my-vol),隐式管理物理路径可移植性 低。依赖宿主机特定的文件目录结构 高。不依赖物理路径,易于在不同环境迁移 性能 依赖宿主机文件系统原生性能 绕过 Storage Driver 层,具备原生 I/O 性能 适用场景 开发环境同步代码、挂载宿主机配置文件 生产环境数据库持久化、日志存储、多容器共享 备份与管理 手动定位宿主机路径进行备份 使用 docker volume命令管理,备份需挂载容器操作隔离性 宿主机进程可轻易修改,安全性较低 由 Docker 隔离,减少了被宿主机其他进程误删的风险
基本语法
方案 A:使用 --mount(推荐方式)
| |
方案 B:使用 -v(简写方式)
| |
可以看到,这里的语法与之前的volume挂载基本相同
网络配置
配置DNS
Docker 容器的 DNS 配置有两种情况:
- 默认 Bridge 网络:继承宿主机的 DNS 配置 (/etc/resolv.conf)。
- 自定义网络(推荐):使用 Docker 嵌入式 DNS 服务器 (Embedded DNS),支持通过 容器名 进行服务发现。
使用自定义网络
| |
端口映射
容器的网络访问规则如下:
- 容器之间:可以通过 IP 或容器名 (自定义网络) 互通。
- 宿主机访问容器:可以通过容器 IP 访问。
- 外部网络访问容器:❌ 默认无法直接访问。
为了让外部 (如你的浏览器、其他局域网机器) 访问容器内的服务,我们需要将容器的端口 映射 到宿主机的端口。
基本用法
| |
- 此时访问 http://localhost:8080 即可看到 Nginx 页面。
格式 含义 示例 ip:hostPort:containerPort 绑定指定 IP 的特定端口 -p 127.0.0.1:8080:80(仅允许本机访问)ip::containerPort 绑定指定 IP 的随机端口 -p 127.0.0.1::80hostPort:containerPort 绑定所有网卡 IP ( 0.0.0.0) 的特定端口-p 8080:80(最常用格式)containerPort 绑定所有网卡 IP 的随机端口 -p 80
随机映射
如果不关心宿主机使用哪个端口,可以使用随机映射。使用 -P (大写) 参数,Docker 会把 Dockerfile 中 EXPOSE 指令暴露的所有端口发布到宿主机的随机高位端口。具体落在哪个端口,取决于宿主机当前可用的临时端口范围。
| |
实战
默认情况下,-p 8080:80 会监听 0.0.0.0:8080,这意味着任何人只要能连接你的宿主机 IP,就能访问该服务。如果不希望对外暴露 (例如数据库服务),应绑定到 127.0.0.1:
| |
网络隔离
不同网络之间默认隔离,容器只能与同一网络中的容器直接通信:
| |
Docker Compose
概览
在学习 Compose 之前,笔者想强调它的真正价值。假设你正在开发一个微服务应用——前端、后端、数据库三个服务。如果你用 Docker 容器分别运行它们,你会遇到这些问题:
- 启动顺序:需要先启数据库,再启后端,最后启前端
- 网络连接:三个容器需要能彼此通信
- 卷挂载:本地代码需要映射到容器内
- 环境变量:每个服务的配置需要逐个设置
使用
docker run逐个启动的话,需要记住 3 条复杂的命令。而Docker Compose的核心价值就是用一个 YAML 文件来定义整个应用,然后一条命令docker compose up启动所有服务。这是 Compose 被广泛采用的原因——它极大地简化了本地开发和测试的复杂性。
Compose 项目早期由 Python 编写,称为 Docker Compose V1,现在的 Docker Compose V2 是一个 Go 语言编写的 Docker CLI 插件。Docker Desktop 默认包含它
关键定义
- 服务 (service):一个应用容器,实际上可以运行多个相同镜像的实例。
- 项目 (project):由一组关联的应用容器组成的一个完整业务单元。
可见,一个项目可以由多个服务 (容器) 关联而成,Compose 面向项目进行管理。
补充: compose命令行
基本使用格式
| |
参数说明
-f, --file FILE: 指定使用的 Compose 模板文件。默认会自动识别 compose.yaml (也兼容 docker-compose.yml 等),并且可以多次指定。-p, --project-name NAME: 指定项目名称,默认将使用所在目录名称作为项目名。--verbose: 输出更多调试信息。-v, --version: 打印版本并退出。
事实上,想要更好的理解docker compose命令,需要和没有compose的docker命令进行比较:
构建项目
docker compose build: 根据当前目录的compose.yml文件进行构建,如果没有用-f指定文件名字的话,会在当前目录中按以下顺序检索,匹配到第一个即停止查找- compose.yaml(官方推荐的首选名称)
- compose.yml
- docker-compose.yaml
- docker-compose.yml(历史最常用的名称,现降级为备选)
docker build: 根据当前目录的dockerfile构建镜像 更多的相同点
- 都会在目标文件变更时才重新构建镜像
自然,它完全可以被且已经被docker compose up取代
启动项目
docker run: 根据镜像名字启动容器,若依赖的镜像尚未构建且可以从远端拉取时,则先拉取该镜像后再启动容器,docker compose up: 根据compose.yml启动项目,若依赖的services(服务)有一些或者全部没有对应的镜像则会先构建再启动项目.
更多的相同点
- 都支持使用-d参数来后台运行
事实上,docker compose up的特性比上面所说的要复杂得多,我们可以compose.yml中预先在build关键字中指定了对应的构建目录和dockerfile,则每次运行docker compose up时可以加上--build参数,来实现在对应的构建目录有更改时自动构建镜像后运行.
因此,如果容器不报错的话我们可以只使用docker compose up命令完成实时的构建和项目运行.
停止和删除容器
docker compose stop: 停止所有服务,保留容器和网络,当然也保留数据卷docker compose down: 停止所有服务后删除容器和网络,默认保留数据卷,除非加上-v参数,这会删除所有匿名卷和命名卷,但保留绑定挂载文件docker stop: 正常停止容器,不会删除容器docker kill: 强制停止容器,不会删除容器docker rm 容器名: 删除某个容器docker rmi 镜像名:docker remove image的缩写,删除某个镜像docker container prune: 删除虚悬容器docker image prune: 删除虚悬镜像
docker compose logs: 日志查看
基本格式
| |
参数
--tail=50: 指定对应的最新日志行数 tail参数的默认值为all,输出所有服务或者在指定服务名字时输出该服务的所有日志.
如果构建报错,都需要使用该命令来查看具体的构建问题.
进阶用法: 多compose文件编排
- 官方文档
前面所说的
docker compose up还可以通过使用多个-f参数,实现多文件的覆盖,从而将生产环境和部署环境彻底隔离开来,具体用法如下:
执行命令
| |
compose.yml
| |
compose.prod.yml
| |
补充: compose编写
build: 指定dockerfile路径
指定 Dockerfile 所在文件夹的路径 (可以是绝对路径,或者相对 Compose 文件的路径)。Compose 将会利用它自动构建这个镜像,然后使用这个镜像.
- Dockerfile 中设置的选项 (例如:CMD、EXPOSE、VOLUME、ENV 等) 将会自动被获取,无需在 Compose 文件中重复设置。
| |
进阶用法
使用arg参数指定构建镜像时的变量:
| |
image: 指定镜像
指定该服务使用的镜像名称或ID,如果该镜像本地不存在,则会去远程仓库拉取该镜像
进阶用法
image可以与build进行配合,指定build生成的镜像名字:
| |
${DOCKER_IMAGE_FRONTEND?Variable not set}: compose语法${VAR?ErrorMessage},若VAR为定义或为空,则compose会报错并停止运行,在终端输出该调试信息TAG-latest: compose语法${VAR-DefaultValue},VAR变量未定义时提供默认值
如果compose.yml所在目录的.env文件中有如下定义:
DOCKER_IMAGE_FRONTEND = frontendTAG = 1.0
而该项目的名字为web,则这个镜像在docker中的最终名字为web-frontend:1.0.
volumes: 指定挂载的数据卷
数据卷所挂载路径设置。可以设置为宿主机路径 (HOST:CONTAINER)(即绑定挂载) 或者数据卷名称 (VOLUME:CONTAINER),并且可以设置访问模式 (HOST:CONTAINER:ro)。
用法
| |
env_file与environment: 环境变量
env_file: 指定环境变量文件路径。- 如果通过 docker compose -f FILE 方式来指定 Compose 模板文件,则 env_file 中变量的路径会基于模板文件路径。
- 如果有变量名称与 environment 指令冲突,则按照惯例,以后者为准。
该环境文件需要严格符合.env格式:
| |
即使没有使用env_file关键字,compose依然会自动读取对应目录的.env文件.
environment: 设置服务的环境变量,如果只给定名称,会自动读取环境变量,可以用来防止泄露不必要的数据.
示例
| |
command: 覆盖容器启动后默认执行的命令
command: bash scripts/prestart.sh
healthcheck: 健康检查
通过命令检查容器是否健康运行。
| |
test: 检查时执行的命令interval: 执行间隔timeout: 超过该时间限制仍未收到响应则视为这次检查失败retries: 第一次检查失败后的总尝试次数,若5次都失败则将该服务标记未不健康(unhealthy).
该关键字通常与depends_on关键字搭配使用.
depends_on
先看这个例子:
| |
- web需要在redis和db两个服务都启动后才可以启动.
也就是说depends_on规定了容器启动的先后顺序,保证需要其他服务作为依赖的容器滞后启动.
进阶用法: 搭配healthcheck
| |
关键字解析
condition: 要求相关依赖服务必须达到的具体状态restart: 对应服务重启时backend也必须重启service_healthy: 要求对应服务通过了健康检查,状态变为healthyservice_completed_successfully: 用于一次性服务中,要求对应服务运行后正常退出
labels
设置服务标签,供第三方工具识别
例如我们可以给后端加上traefik标签:
| |
networks
配置容器连接的网络,若不声明,所有服务都加入默认的桥接网络,彼此可见
写法如下:
| |
expose: 暴露端口
暴露端口,但不映射到宿主机仅可以指定docker内部端口为参数:
| |
docker中装载操作系统
RESTful Web APIs
补充: 什么是RESTful Web API
非常令人震惊的是,这本书并没有谈到这一名词的具体概念和历史背景…因此需要在这里做一点补充
只看上面的文章就够了,我再加上一点历史背景解析
历史背景
- 根据« RESTful Web APIs Patterns and Practices Cookbook »总结
在www(万维网)的概念于1993年左右开始盛行时,并没有一个合适的规范来约束用户端和服务器之间的通信.
于是,web技术大牛Roy T. Fielding在1998年的微软演讲提出了Representational State Transfer(REST)的初步构想,并在两年后的论文(“Architectural Styles and the Design of Network-based Software Architectures”)中完整的介绍了REST,总结一下大致意思就是:
REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems.
看不懂没关系,我们只需要知道Rest的主要准则如下:
| 约束名称 | 核心要求 | 违背后的后果 |
|---|---|---|
| 客户机-服务器 (Client-Server) | 前后端分离,职责解耦。 | 无法独立演进,扩展性受阻。 |
| 无状态 (Stateless) | 每个请求必须包含处理所需的全部信息,服务器不保存会话上下文。 | 导致服务器无法水平扩展,容错性降低。 |
| 可缓存 (Cacheable) | 响应必须定义自身是否可缓存。 | 增加网络延迟,浪费带宽和服务器资源。 |
| 统一接口 (Uniform Interface) | 包含资源标识、通过表述操纵资源、自描述消息、HATEOAS。 | 最常被忽视的一项。不满足此项的通常只是“带 HTTP 的 RPC”。 |
| 分层系统 (Layered System) | 客户端无法感知直接连接的是服务器还是中间件(代理、缓存)。 | 破坏安全性与负载均衡的透明度。 |
| 按需代码 (Code on Demand) | (可选) 允许服务器向客户端发送可执行代码(如 JS)。 | 增加客户端复杂度和安全风险。 |
如果你的Web架构设计和API请求符合这些原则,则可以被称为Restful Web和Restful Web API.(rest-ful,意思大致为rest风格)
Deep Learning from Scratch
- pdf链接 如前所说,阅读« Transformers快速入门 »的前提是要搞懂神经网络是什么,于是我辗转找到了这本享有盛名的书,希望能够彻底理解神经网络的概念