
2026-03-14 数据库笔记
- 课程用教材:<< Database System Concepts >>
- 这本书讲的还是比较全面的,但废话也很多,部分地方讲的不够深
Intro
- …不够overview的overview,我试试自己学完之后来自己写一个
Introduction to the Relational Model
Structure of Relational Databases
A relational database consists of a collection of tables, each of which is assigned a
unique name.
In mathematical terminology, a tuple is simply a sequence(or list) of values. A relationship between n values is represented mathematically by an n-tuple of values, that is, a tuple with n values, which corresponds to a row in a table.
Thus, in the relational model:
- the term relation is used to refer to a table;
- the term tuple is used to refer to a row;
- the term attribute refers to a column of a table.
For each attribute of a relation, there is a set of permitted values, called the domain of that attribute. Thus, the domain of the salary attribute of the instructor relation is the set of all possible salary values, while the domain of the name attribute is the set of all possible instructor names.
A domain is atomic if elements of the domain are considered to be indivisible units.For example, suppose the table instructor had an attribute phone number, which can store a set of phone numbers corresponding to the instructor. Then the domain of phone number would not be atomic, since an element of the domain is a set of phonenumbers, and it has subparts, namely, the individual phone numbers in the set.
- 如果一个域的值在逻辑上/使用上还能再拆成更小的有意义的单元,那它就不是原子的
The null value is a special value that signifies that the value is unknown or does not exist.
Database Schema
- schema: the logical design of the database
- 即数据库中所有关系,属性的处理
- 这个概念其实很重要,会在之后多次出现.
Keys
- superkey: a set of one or more attributes that identify uniquely a tuple in the relation.
For example, the ID attribute of the relation instructor is sufficient to distinguish one instructor tuple from another. Thus, ID is a superkey. The name attribute of instructor, on the other hand, is not a superkey, because several instructors might have the same name.
- candidate keys: superkeys for which no proper subset is a superkey.
It is possible that several distinct sets of attributes could serve as a candidate key.
Suppose that a combination of name and dept name is sufficient to distinguish among
members of the instructor relation. Then, both {ID} and {name, dept name} are candidate
keys. Although the attributes ID and name together can distinguish instructor tuples,
their combination, {ID, name}, does not form a candidate key, since the attribute ID
alone is a candidate key.
- primary key: denote a candidate key that is chosen by the database designer as the principal means of identifying tuples within a relation
- 在这里,primary key可以是由多个attribute组成的tuple
The primary key should be chosen such that its attribute values are never, or are very rarely, changed.
Schema Diagrams
A database schema, along with primary key and foreign-key constraints, can be depicted by schema diagrams
Primary-key attributes are shown underlined. Foreign-key constraints appear as
arrows from the foreign-key attributes of the referencing relation to the primary key of
the referenced relation. We use a two-headed arrow, instead of a single-headed arrow,
to indicate a referential integrity constraint that is not a foreign-key constraints.
Relational Query Languages
-
Query Language: A language used by a user to request information from a database. It operates at a higher level of abstraction than standard programming languages.
-
Categorization:
- Imperative Query Language: The user instructs the system to perform a specific sequence of operations. These languages maintain a notion of state variables that are updated during computation.
- Functional Query Language: Computation is expressed as the evaluation of functions. These functions operate on database data or results of other functions. They are side-effect free and do not update program state.
- Declarative Query Language: The user describes the desired information using mathematical logic without providing specific steps or function calls. The database system is responsible for determining the physical retrieval method.
-
Pure Query Languages:
- Relational Algebra: A functional query language that forms the theoretical basis of SQL.
- Tuple Relational Calculus and Domain Relational Calculus: Declarative languages.
-
Characteristics: These formal languages lack the “syntactic sugar” found in commercial languages but illustrate fundamental techniques for data extraction.
The Relational Algebra(3/26)
The Select Operation
σ dept_name = “Physics” (instructor)
We use the lowercase Greek letter sigma (σ) to denote selection.
We can find all instructors with salary greater than $90,000 by writing:
σ salary>90000 (instructor)
The Project Operation
Projection is denoted by the uppercase Greek letter pi (Π).
Π ID, name, salary (instructor)
The project operation is a unary operation that returns its argument relation, with certain attributes left out.
我们也可以在投影的时候进行计算:
Π ID,salary∕12 (instructor)
Composition of Relational Operations
“Find the names of all instructors in the Physics department.”:
Π name (σ dept_name = “Physics” (instructor))
The Cartesian-Product Operation
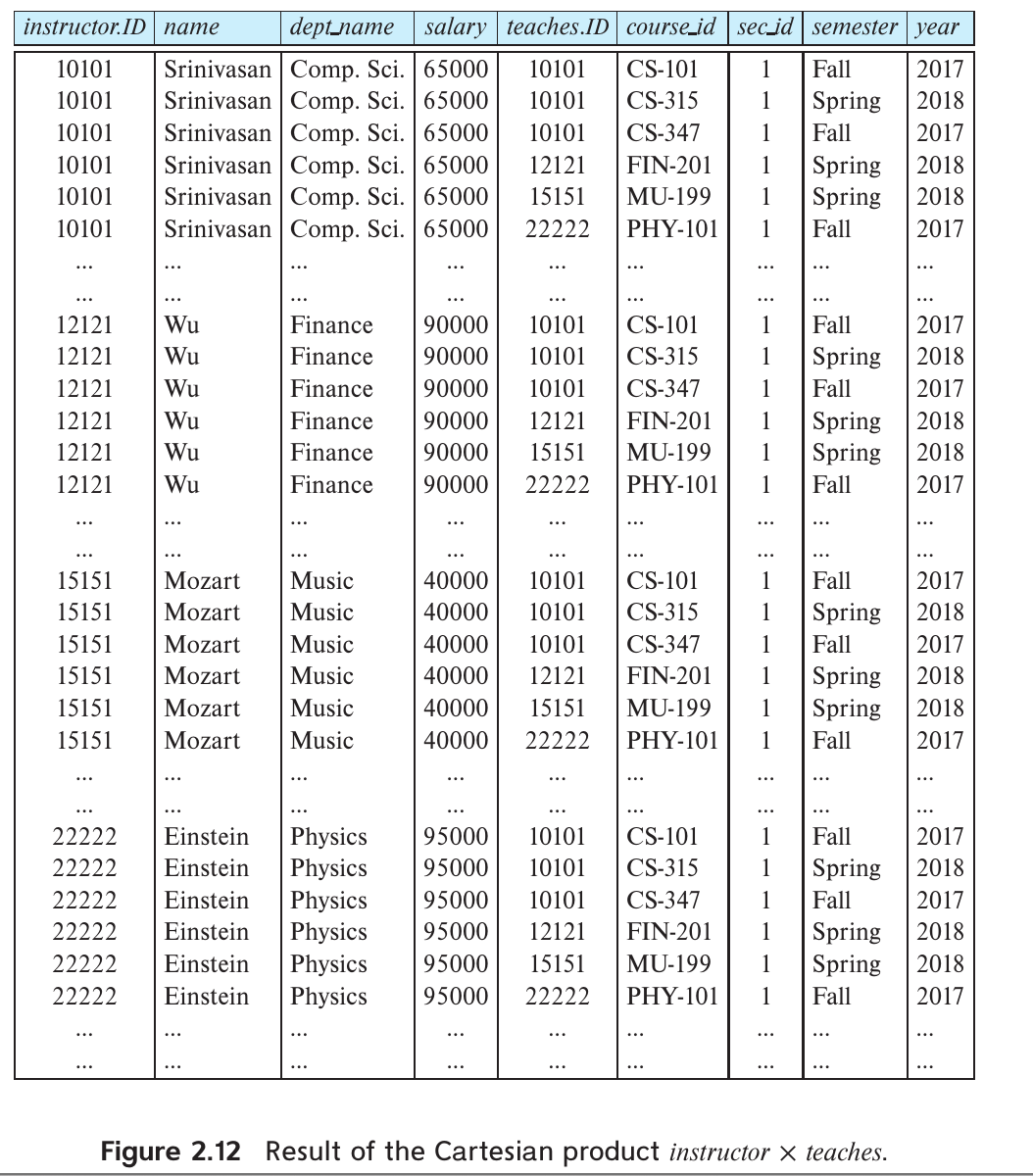
- 也就是说关系上的笛卡尔积会生成一个nxm大小的单元组表
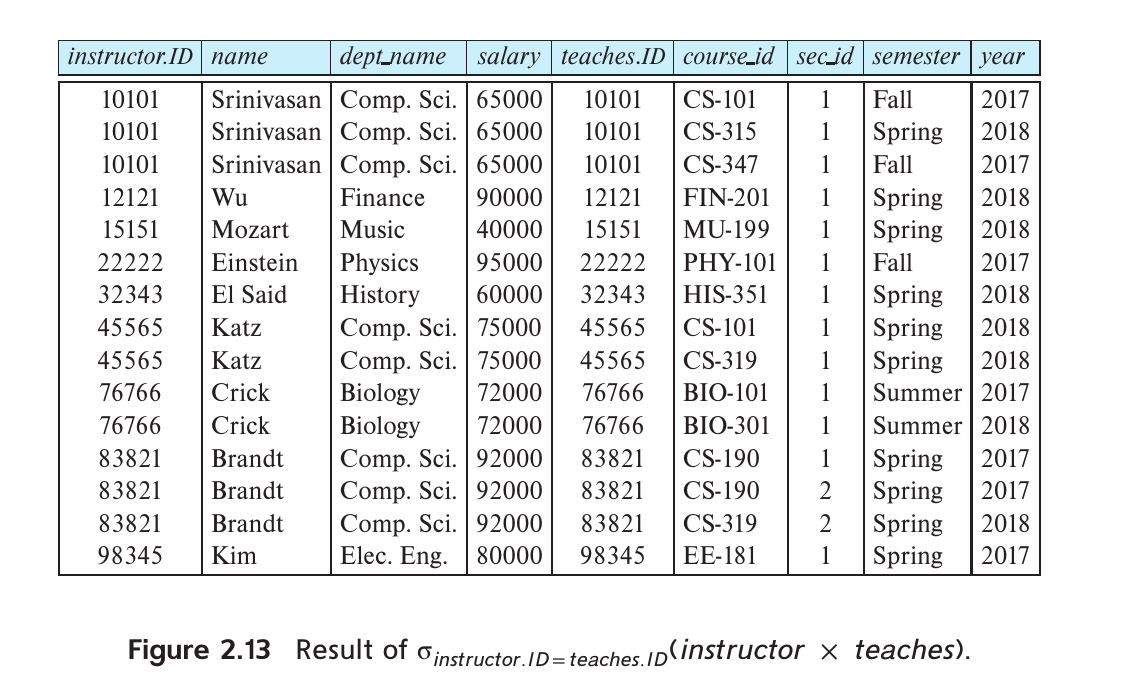
The Join Operation

注意这里的join没有过滤掉重复的id列!
Set Operations
求并集(union)的前提条件:
- 输入的两个关系具有相同数量的属性
- 当属性相关联时,两个关系中对应属性的类型必须相同
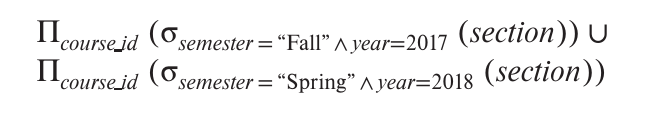
求交集(intersection):
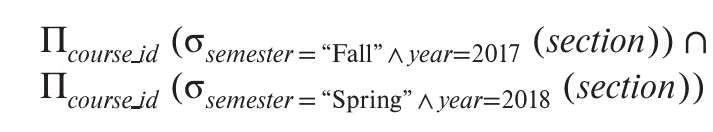
求集差(set-difference):
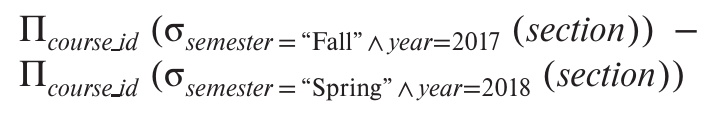
The Assignment Operation
It is convenient at times to write a relational-algebra expression by assigning parts of it to temporary relation variables.
The assignment operation, denoted by ←, works like assignment in a programming language.
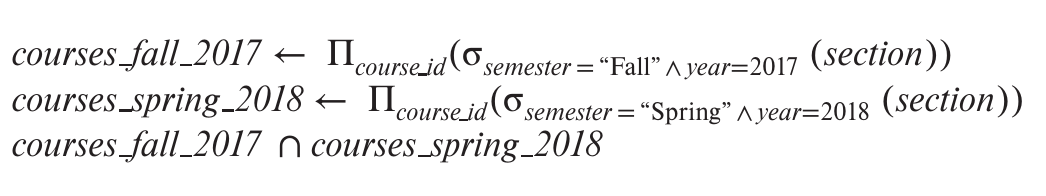
The Rename Operation
The rename operator refers to the results of relational-algebra expressions,denoted by the lowercase Greek letter rho (ρ).
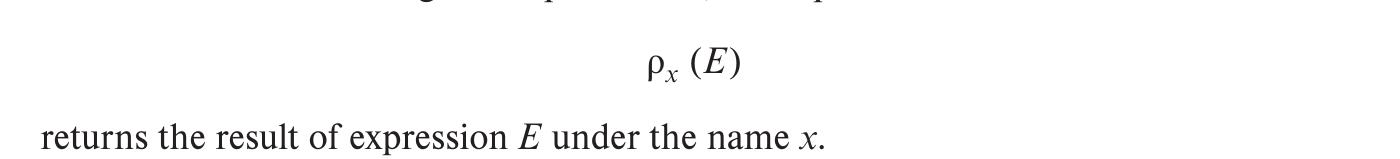
Introduction to SQL
Overview of the SQL Query Language
- The SQL language has several parts:
- Data-definition language (DDL). The SQL DDL provides commands for defining relation schemas, deleting relations, and modifying relation schemas.
- Data-manipulation language (DML). The SQL DML provides the ability to query information from the database and to insert tuples into, delete tuples from, and modify tuples in the database.
- 从这可以看到Data-manipulation是操作实例,Data-definition是操作关系模型
- Integrity. The SQL DDL includes commands for specifying integrity constraints that the data stored in the database must satisfy. Updates that violate integrity constraints are disallowed.
- 即规范性.
- and so on
SQL Data Definition
注意这里介绍的都是初级语法,后面还有高级语法.
Basic Types
The SQL standard supports a variety of built-in types, including:
-
char(n)
Fixed-length character string.
Exactly n characters long.
Padded with spaces if shorter value inserted.
Full form: character(n). -
varchar(n)
Variable-length character string.
Maximum n characters.
Stores only actual characters (no padding).
Full form: character varying(n). -
int
Integer.
Machine-dependent range (usually 32-bit).
Full form: integer. -
smallint
Small integer.
Smaller machine-dependent range than int (usually 16-bit). -
numeric(p, d)
Fixed-point (exact decimal) number.
Total digits: p (including sign).
Decimal places: d.
Example: numeric(3,1) stores -99.9 to 99.9 exactly.
Cannot store 444.5 (exceeds p) or 0.32 (needs d≥2). -
real
Single-precision floating-point.
Machine-dependent precision (usually IEEE 32-bit). -
double precision
Double-precision floating-point.
Machine-dependent higher precision (usually IEEE 64-bit). -
float(n)
Floating-point with minimum precision of n decimal digits.
Implementation chooses actual precision ≥ n.
Each type may include a special value called the null value. A null value indicates
an absent value that may exist but be unknown or that may not exist at all.
When comparing a char type with a varchar type, one may expect extra spaces to be added to the varchar type to make the lengths equal, before comparison; however, this may or may not be done, depending on the database system. As a result, even if the same value “Avi” is stored in the attributes A and B above, a comparison A=B may return false. We recommend you always use the varchar type instead of the char type to avoid these problems.
- 也就是说,可变数组在和固定长度数组比较时未必会加上对应长度的空格后再比较
Basic Schema Definition
We define an SQL relation by using the create table command. The following command creates a relation department in the database:
1 | create table department |
- 结尾的
;在大多数sql版本中是可选的
SQL supports a number of different integrity constraints. In this section, we discuss only a few of them:
-
primary key: required to be nonnull and unique
- 也就是说不可重复,不可为null
- Although the primary-key specification is optional, it is generally a good idea to specify a primary key for each relation.
-
foreign key(A) references s: the value of A in this relation must correspond to value of the primary key attributes in relation s.
- 也就是说不允许把s关系中不存在的值写在这个关系中
-
not null: the null value is not allowed for that attribute
-
drop table: remove a relation from an SQL database
drop table r;只要这样就可以删除关系r了
-
delete from: retains relation r, but deletes all tuples in r.
delete from r;
-
alter table: add or drop attributes to an existing relation
alter table r add A D;:where r is the name of an existing relation, A is the name of the attribute to be added,and D is the type of the added attribute.alter table r drop A;: drop attributes from a relation
eg
1 | create table teaches |
Basic Structure of SQL Queries
The basic structure of an SQL query consists of three clauses: select, from, and where.
A query takes as its input the relations listed in the from clause, operates on them as specified in the where and select clauses, and then produces a relation as the result.
- 事实上在部分语句或者某些数据库系统中where,from是可选的,但select是必须出现的
Queries on a Single Relation
1 | select dept_name |
Since more than one instructor can belong to a department, a department name could appear more than once in the instructor relation.
We can rewrite the preceding query as:
1 | select distinct dept name |
The result of the above query would contain each department name at most once.
Also,SQL allows us to use the keyword all to specify explicitly that duplicates are not removed:
1 | select all dept name |
Since duplicate retention is the default, we shall not use all in our examples.
The select clause may also contain arithmetic expressions involving the operators +, −, ∗, and / operating on constants or attributes of tuples:
1 | select ID, name, dept name, salary * 1.1 |
这不会改动原关系里的salary数值,只是在输出上将salary乘以1.1了
The where clause allows us to select only those rows in the result relation of the from clause that satisfy a specified predicate(断言)
1 | select name |
SQL allows the use of the logical connectives and, or, and not in the where clause.
The operands of the logical connectives can be expressions involving the comparison operators <, <=, >, >=, =, and <>.
Queries on Multiple Relations
1 | select instructor.dept_name, building, name |
注意到在不同关系中同时出现的attribute需要用关系名作为前缀来指明,而独特的attribute则不用
from解析
The from clause by itself defines a Cartesian product of the relations listed in the clause. It is defined formally in terms of relational algebra, but it can also be understood as an iterative process that generates tuples for the result relation of the from clause.
1 | for each tuple t1 in relation r1 |
也就是说from实际上会将所有关系用笛卡尔积制成一个nxm的表,如果不用where来过滤掉多余组合的话,在大型数据库中select将很难处理这么多数据
1 | SELECT s.name, c.course_name |
→ 结果行数 = students 行数 × courses 行数(所有学生 × 所有课程的组合)
Additional Basic Operations
The Rename Operation
1 | select name, course id |
The result of this query is a relation with the following attributes:
name, course id
We cannot, however, always derive names in this way, for several reasons:
First, two relations in the from clause may have attributes with the same name, in which case an attribute name is duplicated in the result.
Second, if we use an arithmetic expression in the select clause, the resultant attribute does not have a name.
Third, even if an attribute name can be derived from the base relations as in the preceding example, we may want to change the attribute name in the result.
Hence, SQL provides a way of renaming the attributes of a result relation. It uses the as clause, taking the form:
old-name as new-name
For example, if we want the attribute name name to be replaced with the name instructor_name, we can rewrite the preceding query as:
1 | select name as instructor name, course id |
The as clause is particularly useful in renaming relations.
One reason to rename a relation is to replace a long relation name with a shortened version that is more convenient to use elsewhere in the query.
To illustrate, we rewrite the query “For all instructors in the university who have taught some course, find their names and the course ID of all courses they taught.”
1 | select T.name, S.course_id |
Another reason to rename a relation is a case where we wish to compare tuples in the same relation. We then need to take the Cartesian product of a relation with itself and, without renaming, it becomes impossible to distinguish one tuple from the other.
Suppose that we want to write the query “Find the names of all instructors whose salary is greater than at least one instructor in the Biology department.”
We can write the SQL expression:
1 | select distinct T.name |
String Operations
SQL specifies strings by enclosing them in single quotes, for example, ‘Computer’. A single quote character that is part of a string can be specified by using two single quote characters.
For example, the string “It’s right” can be specified by ‘It’‘s right’.
The SQL standard specifies that the equality operation on strings is case sensitive;as a result, the expression “‘comp. sci.’ = ‘Comp. Sci.’” evaluates to false.
- 但在MySQL和SQL Server中,在字符串比较时不区分大小写,故“‘comp. sci.’ = ‘Comp. Sci.’” 为真.
Pattern matching can be performed on strings using the operator like. We describe patterns by using two special characters:
- Percent (%): The % character matches any substring.
- Underscore (_): The character matches any character.
Patterns are case sensitive.To illustrate pattern matching, we consider the following examples:
- ‘Intro%’ matches any string beginning with “Intro”.
- ‘%Comp%’ matches any string containing “Comp” as a substring, for example, ‘Intro. to Computer Science’, and ‘Computational Biology’.
- ‘___’ matches any string of exactly three characters.
- ‘___%’ matches any string of at least three characters.
For patterns to include the special pattern characters (that is, % and ), SQL allows the
specification of an escape character. The escape character is used immediately before
a special pattern character to indicate that the special pattern character is to be treated
like a normal character. We define the escape character for a like comparison using the
escape keyword. To illustrate, consider the following patterns, which use a backslash(∖) as the escape character:
- like ‘ab∖%cd%’ escape ‘∖’ matches all strings beginning with “ab%cd”.
- like ‘ab∖∖cd%’ escape ‘∖’ matches all strings beginning with “ab∖cd”.
也就是说,sql没有通用的转义符,而是需要用户定义并写入字符串中
SQL allows us to search for mismatches instead of matches by using the not like com-
parison operator. Some implementations provide variants of the like operation that do
not distinguish lower- and uppercase.
Attribute Specification in the Select Clause
The asterisk symbol “ * ” can be used in the select clause to denote “all attributes.”
1 | select instructor.* |
It indicates that all attributes of instructor are to be selected.
Ordering the Display of Tuples
The order by clause causes the tuples in the result of a query to appear in sorted order.
By default, the order by clause lists items in ascending order. To specify the sort order,
we may specify desc for descending order or asc for ascending order. Furthermore,
ordering can be performed on multiple attributes. Suppose that we wish to list the
entire instructor relation in descending order of salary. If several instructors have the
same salary, we order them in ascending order by name. We express this query in SQL as follows:
1 | select * |
Where-Clause Predicates
SQL includes a between comparison operator to simplify where clauses that specify
that a value be less than or equal to some value and greater than or equal to some other value.
Similarly, we can use the not between comparison operator.
1 | select name |
尽管它等价于以下语句,但看上去就直白了一点
1 | select name |
SQL permits us to use the notation (v1 , v2 , … , vn ) to denote a tuple of arity n con-
taining values v1 , v2 , … , vn ; the notation is called a row constructor. The comparison
operators can be used on tuples, and the ordering is defined lexicographically. For ex-
ample, (a1 , a2 ) <= (b1 , b2 ) is true if a1 <= b1 and a2 <= b2 ; similarly, the two tuples
are equal if all their attributes are equal. Thus, the SQL query:
1 | select name, course id |
can be rewritten as follows:
1 | select name, course id |
- 看似简写了,但其实看上去更懵了
Set Operations
The SQL operations union, intersect, and except operate on relations and correspond to the mathematical set operations ∪, ∩, and −.
The Union Operation
1 | (select course id |
这里只是把两个结果合并了一下而已
Note that the parentheses we include around each select-
from-where statement below are optional but useful for ease of reading.
- The union operation automatically eliminates duplicates, unlike the select clause.
If we want to retain all duplicates, we must write union all in place of union.
The Intersect Operation
1 | (select course id |
找交集
- 同样可以加一个all来保留相同字段
1 | (select course id |
The Except Operation
To find all courses taught in the Fall 2017 semester but not in the Spring 2018 semester,we write:
1 | (select course id |
The except operation outputs all tuples from its first input that do not occur in the second input.
- 同样可以加一个all来保留相同字段
1 | (select course id |
Null Values
Null values present special problems in relational operations, including arithmetic operations, comparison operations, and set operations.
The result of an arithmetic expression (involving, for example, +, −, ∗, or ∕) is null.
If any of the input values is null. For example, if a query has an expression r.A + 5, and r.A is null for a particular tuple, then the expression result must also be null for that tuple.
- 也就是说null参与的数学运算结果都是null
Comparisons involving nulls are more of a problem.SQL therefore treats as unknown the result of any comparison involving a null value.This creates a third logical value in addition to true and false.
Since the predicate in a where clause can involve Boolean operations such as and,or, and not on the results of comparisons, the definitions of the Boolean operations are extended to deal with the value unknown.
- and: The result of true and unknown is unknown, false and unknown is false, while unknown and unknown is unknown.
- or: The result of true or unknown is true, false or unknown is unknown, while unknown or unknown is unknown.
- not: The result of not unknown is unknown.
为什么这样设计?
- TRUE AND UNKNOWN 为什么是 UNKNOWN?
- 如果 UNKNOWN 实际上是 TRUE:true and true = true
- 如果 UNKNOWN 实际上是 FALSE: true and false =false
- 由于结果可能是 TRUE 也可能是 FALSE,数据库无法给出定论,只能保守地标注为 UNKNOWN。
- false and unknown 为什么是 false?
- 含有false的and语句恒为false,结果是确定的,故可标记为false.
- true or unknown 为什么是 true?
- 同理,含有true的or语句恒为true.
- false or unknown 为什么是 unknown?
- 同理,结果可能是 TRUE 也可能是 FALSE,无法定论.
SQL uses the special keyword null in a predicate to test for a null value.
Thus, to find all instructors who appear in the instructor relation with null values for salary, we write:
- 补充:
5*20+3=null,null=null,返回值都是unknown.
1 | select name |
- 有
is null当然就有is not null.
SQL allows us to test whether the result of a comparison is unknown,by using the clauses is unknown and is not unknown.For example:
1 | select name |
Aggregate Functions
Aggregate functions are functions that take a collection (a set or multiset) of values as
input and return a single value. SQL offers five standard built-in aggregate functions:
- Average: avg
- Minimum: min
- Maximum: max
- Total: sum
- Count: count
Basic Aggregation
1 | select avg (salary) as avg_salary |
- 找到salary的平均值
1 | select count (distinct ID) |
- 使用count关键字统计()内的具有对应属性的行数
Aggregation with Grouping
1 | select dept_name, avg (salary) as avg salary |
这里把instructor用dept_name分组,从而统计出每个部门的avg_salary.
- 也就是说
group by需要在select语句中写明操作的对象,才能在结果中反映出来分组的结果
1 | /* erroneous query */ |
- 上述sql语句由于一个分组中的tuple可以有不同的id属性,故不能变成一个分组,会引发错误
总结一下:
当 SQL 查询包含 GROUP BY 子句时,SELECT 子句中的任何属性(列名)必须满足以下两个条件之一,否则该查询在逻辑上是错误的:
- 该属性出现在 GROUP BY 子句中。
- 该属性被包裹在聚合函数(如 SUM, COUNT, AVG, MAX, MIN)之中。
进阶版
1 | select dept_name, count (distinct ID) as instr count |
- “Find the number of instructors in each department who teach a course in the Spring 2018 semester.”
The Having Clause
为了处理分组,而不是处理分组后的tuples,引入了having clause.
1 | select dept name, avg (salary) as avg_salary |
- 上述语句会过滤掉ayg_salary小于等于42000的分组
The logical execution sequence of an SQL query containing aggregation, GROUP BY, or HAVING clauses is defined as follows:
- Evaluate the
FROMclause
TheFROMclause is first evaluated to generate a relation (the initial set of data from specified tables or joins). - Apply the
WHEREclause (if present)
The predicate in theWHEREclause is applied to the result relation of theFROMclause. Only tuples satisfying this predicate proceed. - Apply the
GROUP BYclause (if present)
Tuples satisfying theWHEREpredicate are placed into groups based on theGROUP BYclause. If theGROUP BYclause is absent, the entire set of filtered tuples is treated as a single group. - Apply the
HAVINGclause (if present)
TheHAVINGclause is applied to each group. Groups that do not satisfy theHAVINGclause predicate are removed entirely. - Evaluate the
SELECTclause
TheSELECTclause uses the remaining groups to generate the final result tuples. Aggregate functions are applied here to produce a single result tuple for each group.
长难句分析
1 | select course_id, semester, year, sec_id, avg (tot_cred) |
- 这里把学生按照“班级”扔进不同的筐里。比如“数据库-2017-秋-01班”是一个筐,“算法-2017-秋-02班”是另一个筐
也就是说,group by后面的属性全部相同时才会被归为一组
Aggregation with Null and Boolean Values
1 | select sum (salary) |
当salary中有null值的时候,并不会像普通的5+null=null一样返回null,而是会忽略null
In general, aggregate functions treat nulls according to the following rule: All aggre-
gate functions except count (*) ignore null values in their input collection. As a result
of null values being ignored, the collection of values may be empty. The count of an
empty collection is defined to be 0, and all other aggregate operations return a value
of null when applied on an empty collection
- 由于count是统计行数的,故当某一行有null时也会计入
Nested Subqueries
A subquery is a select-from-where expression that is nested within another query. A common use of subqueries is to perform tests for set membership, make set comparisons, and determine set cardinality by nesting subqueries in the where clause.
Set Membership
1 | select distinct course_id |
We use the not in construct in a way similar to the in construct. For example, to find
all the courses taught in the Fall 2017 semester but not in the Spring 2018 semester,
which we expressed earlier using the except operation, we can write:
1 | select distinct course id |
- 也就是说,之前提到的intersect和except都可以用subquery的形式来解决
Set Comparison
The phrase “greater than at least one” is represented in SQL by > some.
1 | select name |
SQL also allows < some, <= some, >= some, = some, and <> some comparisons.
As an exercise, verify that = some is identical to in, whereas <> some is not the same as not in.
The construct > all corresponds to the phrase “greater than all.”
1 | select name |
As it does for some, SQL also allows < all, <= all, >= all, = all, and <> all comparisons.
As an exercise, verify that <> all is identical to not in, whereas = all is not the same as
in.
Test for Empty Relations
The exists construct returns the value true if the argument subquery is nonempty.
1 | select course_id |
The above query also illustrates a feature of SQL where a correlation name from
an outer query (S in the above query), can be used in a subquery in the where clause.
A subquery that uses a correlation name from an outer query is called a correlated
subquery.
当然,有exists就有not exists:
1 | select S.ID, S.name |
长难句分析
首先计算“Biology 系开设了,但该学生没选”的课程,如果这类课程not exists,说明该学生选了所有Biology系的课程.
Test for the Absence of Duplicate Tuples(3/18)
Using the unique construct, we can write the query “Find all courses that were offered at most once in 2017” as follows:
- 如果你记忆力够好的话,可能会记得之前在create table的时候会用unique来保证对应的属性不能有重复值
1 | select T .course id |
Note that if a course were not offered in 2017, the subquery would return an empty result, and the unique predicate would evaluate to true on the empty set.
也就是说即使结果为空,但由于是unique,故也会返回true.
当然,有了unique就有not unique,要求返回结果中的每个tuple至少出现两次
1 | select T .course id |
- 可以看到,where部分的subquery可以访问外层的关系
Subqueries in the From Clause
1 | select dept name, avg salary |
- 是的,from的关系也能用别名…
但是值得注意的是,在from中的subquery不能访问外层的关系,因为from中的关系是相互并列的,不存在嵌套关系,只能通过lateral关键字来强制让后继关系能够获取前置关系
1 | select name, salary, avg_salary |
如果你跟我一样从头看到这里的话,你会清楚的记得前面都是写类似
instructor as I1的方式来起别名的,但是as实际上是可选的!尽管这里并没有提到这一点-这也是我讨厌这本教材的原因之一.
The With Clause
The with clause provides a way of defining a temporary relation whose definition is available only to the query in which the with clause occurs.
1 | with max_budget (value) as |
注意到这里是先写别名再在as后写原关系,而我们之前都是先写原关系再写as的
with得到的是关系而非属性,因此我们每次都需要用关系(属性)的方式来使用with
- 实际上,上述的with语句完全可以放到where中
1 | select budget |
We could have written the preceding query by using a nested subquery in either the from clause or the where clause.
However, using nested subqueries would have made the query harder to read and understand. The with clause makes the query logic clearer;
it also permits this temporary relation to be used in multiple places within a query.
Scalar(标量) Subqueries
SQL allows subqueries to occur wherever an expression returning a value is permitted,provided the subquery returns only one tuple containing a single attribute; such sub-queries are called scalar subqueries.
- 也就是说只返回一行一列
长难句分析
1 | select dept_name, |
select count(*)在这里是无论是否有空值都返回满足epartment.dept_name = instructor.dept_name的所有行的意思
Scalar Without a From Clause
1 | (select count (*) from teaches) / (select count (*) from instructor); |
Modification of the Database(3/19)
Deletion
A delete request is expressed in much the same way as a query. We can delete only whole tuples; we cannot delete values on only particular attributes. SQL expresses a deletion by:
1 | delete from r |
1 | delete from instructor |
- 事实上delete与select的用法没有什么区别,只不过一个是选择关系,一个是删除关系而已.
Insertion
The attribute values for inserted tuples must be members of the corresponding attribute’s domain. Similarly, tuples inserted must have the correct number of attributes.
1 | insert into course |
1 | insert into instructor |
当然,我们可以从其他关系中获取tuple后再插入,而不是只用value来具体写.
Updates
n certain situations, we may wish to change a value in a tuple without changing all values in the tuple. For this purpose, the update statement can be used.
1 | update instructor |
进阶写法
1 | update instructor |
Intermediate SQL(3/15)
Join Expressions
事实上,单独的join语句不加任何前缀和后缀会报错,因为不存在只写一个join而不进行过滤操作的语法.
The Natural Join
1 | select name, course_id |
上述语句在执行的中间结果中会保留两个ID列,只是在select时抛弃掉了而已.
1 | select name, course id |
而natural join的中间结果只保留一个ID列
规则:
- 找到同名列
- 过滤掉同名列中的值不相等的行
- 两个同名列只保留一列
1 | select name, title |
The operation join … using requires a list of attribute names to be specified. Both relations being joined must have attributes with the specified names.
- 也就是说只用using()里面那个属性在join的时候来判断,而不像natural join一样在有多个同名属性的情况下全都要求相等.
Join Conditions
The on condition allows a general predicate over the relations being joined.
1 | select * |
完全等价于下面语句,也就是结果都保持了两个ID列
1 | select * |
- 所以基本用不上on
Outer Joins
1 | select * |
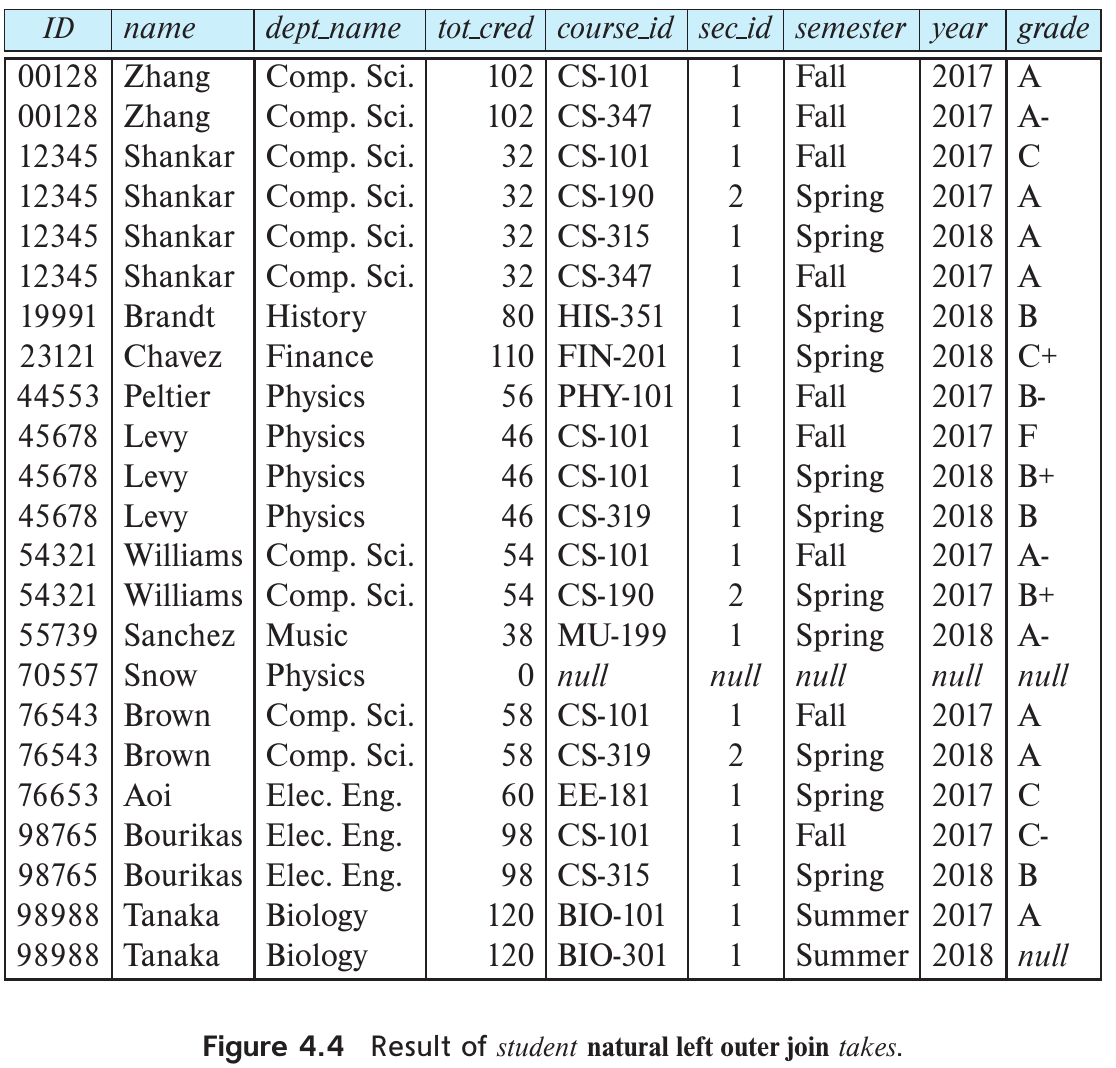
由于natural join会丢弃takes.id!=student.id的行,对于只在一个表中存在的ID,由于在另一个表中找不到对等的值,也会被抛弃,但在实际需求中,即使没选课的学生,我们也希望展示出来,故这里需要使用outer join.
There are three forms of outer join:
- The left outer join preserves tuples only in the relation named before the left outer join operation.
- The right outer join preserves tuples only in the relation named after the right outer join operation.
- The full outer join preserves tuples in both relations.
In contrast, the join operations we studied earlier that do not preserve nonmatched tuples are called inner-join operations, to distinguish them from the outer-join operations.
We now explain exactly how each form of outer join operates. We can compute
the left outer-join operation as follows: First, compute the result of the inner join as
before. Then, for every tuple t in the left-hand-side relation that does not match any
tuple in the right-hand-side relation in the inner join, add a tuple r to the result of the
join constructed as follows:
- The attributes of tuple r that are derived from the left-hand-side relation are filled in with the values from tuple t.
- The remaining attributes of r are filled with null values.
1 | select * |
如果对于在student里出现但在takes里没有的id,会将student表中的值填入,对应takes部分的值均为null.
The full outer join is a combination of the left and right outer-join types. After the
operation computes the result of the inner join, it extends with nulls those tuples from
the left-hand-side relation that did not match with any from the right-hand-side relation
and adds them to the result. Similarly, it extends with nulls those tuples from the right-
hand-side relation that did not match with any tuples from the left-hand-side relation
and adds them to the result. Said differently, full outer join is the union of a left outer
join and the corresponding right outer join.
- 也就是说保留两边的缺值
进阶例子
1 | select * |
一开始明明都是用
student natural full outer join takes的,这里为什么要单独把两个结果提出来呢?
1 | select * |
因为如果这样写的话,尽管在from部分保留了null,但where部分又把null全部过滤掉了
The on condition is part of the outer join specification, but a where clause is not.
1 | select * |
也就是说上面这个语句不等价于下面的,因为on是在join阶段生效,即使不匹配也会置为null;
而where是在join之后生效,因此where会过滤掉null行,而上面语句中的on则会保留
1 | select * |
Join Types and Conditions
The keyword inner is optional:
1 | select * |
is equivalent to:
1 | select * |
Similarly, natural join is equivalent to natural inner join.
Views
SQL allows a “virtual relation” to be defined by a query, and the relation conceptually contains the result of the query. The virtual relation is not precomputed and stored but instead is computed by executing the query whenever the virtual relation is used.
因此就有了view这个概念用来代表尚未执行的sql语句
View Definition
1 | create view v as <query expression>; |
where < query expression > is any legal query expression. The view name is represented v
1 | create view faculty as |
通过这样写,可以给低权限用户传递view这个关系而不直接接触instructor这个关系.
Using Views in SQL Queries
The attribute names of a view can be specified explicitly as follows:
1 | create view departments total salary(dept name, total salary) as |
Since the expression sum(salary) does not have a name, the attribute name is specified explicitly in the view definition.
Update of a View
Not recommended!
Transactions
blablabla…
Integrity Constraints
Constraints on a Single Relation
- not null
- unique
- check(
)
Not Null Constraint
1 | name varchar(20) not null |
The not null constraint prohibits the insertion of a null value for the attribute, and is an example of a domain constraint.
Unique Constraint
The unique specification says that no two tuples in the relation can be equal on all the listed attributes.
The Check Clause
When applied to a relation declaration, the clause check(P) specifies a predicate P that must be satisfied by every tuple in a relation.
1 | create table section |
Here, we use the check clause to simulate an enumerated type by specifying that semester must be one of ‘Fall’, ‘Winter’, ‘Spring’, or ‘Summer’.
还可以把check写在定义的属性之后
1 | CREATE TABLE classroom ( |
Referential Integrity
默认引用 (Implicit Reference)
foreign key (dept_name) references department
- 底层行为:当你省略括号中的属性名时,SQL 标准规定该外键必须引用被参照表的 主键 (Primary Key)
显式引用 (Explicit Reference)
foreign key (dept_name) references department(dept_name)
- 底层行为:目标列(dept_name)不必是主键,但必须具有 唯一性约束 (UNIQUE) 或本身就是 主键。即它必须是一个 超键 (Superkey)。
Assigning Names to Constraints
1 | -- 使用constraint关键字命名该限制 |
Complex Check Conditions and Assertions
An assertion is a predicate expressing a condition that we wish the database always
to satisfy.
格式
1 | create assertion <assertion-name> check <predicate>; |
1 | create assertion credits earned constraint check |
- 非常好的是这种东西不会考,因为主流数据库也不用
SQL Data Types and Schemas
There are additional built-in data types supported by SQL, which we describe below.
Date and Time Types in SQL
- date: A calendar date containing a (four-digit) year, month, and day of the month.
- time: The time of day, in hours, minutes, and seconds.
- timestamp: A combination of date and time.
Date and time values can be specified like this:
1 | date '2018-04-25' |
Type Conversion and Formatting Functions(过)
- 由于我找到了中文版教材,故从现在开始大部分使用中文版,少部分使用英文版(因为这本书真的是又臭又长)
1. 显式类型转换 (Type Casting)
语法: cast(expression as data_type)
用途: 物理改变数据的解析方式,常用于修正字符串排序逻辑。
1 | /* 修正前:'11' 会排在 '2' 前面(字符串字典序) */ |
2. 格式化函数 (Formatting Functions)
用途: 不改变物理类型,只给数据套上“显示滤镜”。各数据库系统实现不同。
1 | -- MySQL: 数字千分位格式化 |
3. 空值合并 (Coalesce)
语法: coalesce(arg1, arg2, ...)
逻辑: 物理扫描参数列表,返回第一个非 null 的值。要求所有参数物理类型一致。
1 | /* 如果 salary 是 null,物理替换为 0 以便后续数学运算 */ |
4. 条件解码 (Decode - Oracle 特有)
语法: decode(value, search, result, default)
逻辑: 类似于 switch-case。它允许 null = null 的物理匹配,且不强制要求类型一致。
1 | /* 将物理空值直接翻译成业务描述字符串 'N/A' */ |
- 随便一看就知道不会考的…
Default Values
SQL allows a default value to be specified for an attribute as illustrated by the following
create table statement:
1 | create table student |
Large-Object Types
SQL provides large-object data types for character data (clob) and binary data (blob).
The letters “lob” in these data types stand for “Large OBject.”
1 | book_review clob(10KB) |
User-Defined Types(过)
SQL supports two forms of user-defined data types.
The first form, which we cover here, is called distinct types.
The create type clause can be used to define new types:
1 | create type Dollars as numeric(12,2) final; |
- 这一节也不重要,因为主流数据库也不支持
Generating Unique Key Values
1 | ID number(5) generated always as identity |
Create Table Extensions
Applications often require the creation of tables that have the same schema as an existing table.
1 | -- SQL provides a create table like extension to support this task |
Schemas, Catalogs, and Environments(过)
Index Definition in SQL(过)
由于这部分基本什么都没讲,还是得到index章节去看
Authorization
We may assign a user several forms of authorizations on parts of the database. Authorizations on data include:
• Authorization to read data.
• Authorization to insert new data.
• Authorization to update data.
• Authorization to delete data.
- Each of these types of authorizations is called a privilege.
Granting and Revoking of Privileges
1 | -- grant的使用格式 |
Roles
- 我们使用Roles来解决需要多次指定相同权限的问题
1 | create role instructor; |
Authorization on Views
1 | -- 为了让某个工作人员能够看到地质系的所有教师但不能看到其他系的教师表,我们可以这样写: |
Authorizations on Schema
SQL includes a references privilege that permits a user to declare foreign keys when creating relations.
1 | grant references (dept_name) on department to Mariano; |
为什么要限制引用外码呢?
However, recall that foreign-key constraints
restrict deletion and update operations on the referenced relation. Suppose Mariano
creates a foreign key in a relation r referencing the dept name attribute of the department
relation and then inserts a tuple into r pertaining to the Geology department. It is no
longer possible to delete the Geology department from the department relation without also modifying relation r.
Transfer of Privileges
当我们授予某用户一个权限时,默认他是无法将获得的权限传递给其他用户的,如果希望他能够传递权限,我们可以这样写:
1 | grant select on department to Amit with grant option; |
- 当然,关系/视图/角色(relation/view/role) 的创建者拥有该对象的所有权限并且可以给其他用户授权(不然就没人能授权了)
Revoking of Privileges(过)
Advanced SQL
- 事实上,这部分我觉得期末不考,我猜老师自己也不会😅
- (4/8): 第一次小测考了前三节,…
Accessing SQL from a Programming Language(过)
JDBC
- 你猜怎么着,我们的课程安排是在学完这门课后再学java…
The JDBC standard defines an application program interface (API) that Java programs can use to connect to database servers. (The word JDBC was originally an abbreviation for Java Database Connectivity, but the full form is no longer used.)
ODBC
The Open Database Connectivity (ODBC) standard defines an API that applications can use to open a connection with a database, send queries and updates, and get back results.
Functions and Procedures(待补充)
Triggers(待补充)
A trigger is a statement that the system executes automatically as a side effect of a modification to the database.
- 也就是说,trigger是一个满足条件时自动执行的函数
第一次小测复习
ch1
使用文件处理系统而不是数据库的弊端
- Data redundancy and inconsistency: 可能有多个文件记录了相同的信息,又或者不同文件的记录不相同,没有同步更新
- Difficulty in accessing data: 普通的编程语言不能做到用高效又便利的方式取回数据
- Data isolation: 数据被存储在不同类型的不同文件中,很难统一管理
- Integrity problems: 很难通过普通的编程语言去给存储的数据加上各种限制
- Atomicity problems: 转账时,如果在付款方付钱后系统故障,那么收款方账户未必会收到钱,但付款方账户已经扣了钱.也就是说,很难实现这样一种效果:要么两边操作全都发生,要么都不发生
- Concurrent-access anomalies: 并发访问数据时可能导致异常
- Security problems: 很难设置不同管理员的权限
数据库结构的基础: 数据模型
本书介绍了4种模型:
- Relational Model: uses a collection of tables to represent both data and the relationships among those data. Each table has multiple columns, and each column has a unique name. Tables are also known as relations.
- Entity-Relationship Model: The entity-relationship (E-R) data model uses a collection of basic objects, called entities, and relationships among these objects.
- Semi-structured Data Model: individual data items of the same type may have different sets of attributes.
- Object-Based Data Model: 仅仅是第一种类型的扩展,适用于面向对象的编程语言
ch2: Introduction to the Relational Model
schema到底是什么
- Relation Schema(关系模式):对应编程中的“类型定义”或“类声明”。
- 物理组成:由属性名(Attributes)及其对应的域(Domains/Data Types)组成。
- 示例分析:
department (dept_name, building, budget)物理规定了任何存入该表的记录必须且只能包含这三个维度。
- Database Schema(数据库模式):对应软件架构中的“逻辑设计”。
ch3
数据类型
- char(n): 固定长度为n的字符串
- varchar(n): 最大长度为n的可变长字符串
- int: 整数
- numeric(p,d): 有p位数字(加上一个符号位)和小数点右边的p位中的d位数字
- float(n): 精度至少为n位数字的浮点数
操纵关系表
创建表时可以对变量使用以下六个限制:
- primary key(d): d非空且唯一
- foreign key(d) references s: d的值必须出现在s的对应主码上
- foreign key(d) references s(t): d的值必须与t对应,要求t是唯一的,即具有unique约束
- not null: 非空
- unique: 唯一
- check(d…): 要求新加入的d满足对应条件,否则插入时报错
1 | create table department( |
删除表或更改属性
1 | -- 删除表r |
删除元组
1 | -- 删除表r中的所有元组,保留框架 |
插入元组
1 | -- 需要按照属性名顺序来,否则可能会插入失败 |
更新元组
1 | -- 更改满足条件的属性名 |
select…from…where
select基础部分
1 | -- !!!select会选中null行,不自动过滤!!! |
select进阶部分
1 | -- max,min,avg,sum:均为op(attribute)格式 |
from基础部分
1 | -- 启用as |
where基础部分
1 | -- =判断符 |
where进阶
1 | -- 构造器写法: (a,b)=(c,d)-> a=c and b=d |
where中的子查询
in,not in
1 | select distinct course_id |
some
1 | select name |
SQL also allows < some, <= some, >= some, = some, and <> some comparisons.
As an exercise, verify that = some is identical to in, whereas <> some is not the same as not in.
all
1 | select name |
SQL also allows < all, <= all, >= all, = all, and <> all comparisons.
As an exercise, verify that <> all is identical to not in, whereas = all is not the same as in.
(not) exists
1 | select course_id |
exists的原理: 当括号内的查询第一次被满足时即返回true,让sql引擎继续扫描下一行.
unique
1 | select T .course id |
如果无重复元组则返回true,无论元组是否为空
from中的子查询
1 | select dept_name, avg_salary |
with: 子查询的变种
1 | with max_budget (value) as |
标量子查询
1 | select dept_name, |
having和group by
group by
1 | -- 在group子句中的所有属性取值相同的元组将被分在一个组内,显然,当涉及的属性名越多,分的组也会越多 |
注意,没有出现在group by中的属性只能以聚集函数的参数形式在select语句中出现,如下方的例子中ID就是不该出现的属性,因为一个组中的教师可以有不同的ID,那就无法选定保留哪一个ID:
1 | /* erroneous query */ |
having: 作用于group的条件判断
1 | select dept_name, avg (salary) as avg_salary |
关系的集合
- 三种运算均自动去重
1 | -- union(并集): 找到至少在一个关系中出现的被select选中的元组,自动去重 |
排在最末尾的order by: 结果排序
1 | -- 不写默认为升序asc |
习题3.1
a
1 | select title |
b
1 | select distinct ID |
c
1 | select max(salary) |
d
1 | with max_salary(v) as (select max(salary) from instructor) |
e
目标: 2017年 秋季 每个课程段 选课人数
approach: section,takes
1 | select count(ID),course_id,sec_id; |
f
target: max enrollment in Autumn 2009
1 | with enrollment(counts) as ( |
ch4
join
natural join: 自动去重的发散join
自动去重,多列匹配
1 | select name, course id |
join…using: 自动去重的定向join
using 只能用于等值连接,不能配合其他谓词使用
1 | select name, title |
相当于一个仅比对所需列的natural join,更加安全
join…on: 不自动去重的定向join
1 | select * |
- 当然,on在大多数情况下都可以用where直接替换,但对于outer join来说,二者是有所不同的
outer join: 保留空值的发散join前缀
outer join本身不能直接使用,需要搭配on,natural或者using
当我们希望即便一边的ID有值,但另一边不存在这个ID时,也保留该行时,可以使用outer join.
有三种形式:
- left outer join: 只保留左边关系中的元组
- right outer join: 只保留右边关系中的元组
- full outer join: 保留两边关系的元组
以left outer join为例子来说明:
- The attributes of tuple r that are derived from the left-hand-side relation are filled in with the values from tuple t.
- The remaining attributes of r are filled with null values.
1 | select ID |
Database Design Using the E-R Model
数据库的设计并不简单,所以我们需要一些好用的模型来组织数据库,比如这章涉及的E-R模型.
- 忽然发现前面的笔记中废话太多了,像我的小测复习这样精炼就已经可以了,能够轻松的获取所需的信息
The Entity-Relationship Model
- entity: a “thing” or “object” in the real world that is distinguishable from all other objects.
- 实体是一个独一无二的个体
- attribute: 实体通过一组属性来表示,每个实体在它的每个属性上都有一个值(value)
- entity set: 共享部分属性的实体集合
- relationship: 多个实体之间的关系
- relationship set: 相同类型的联系集合
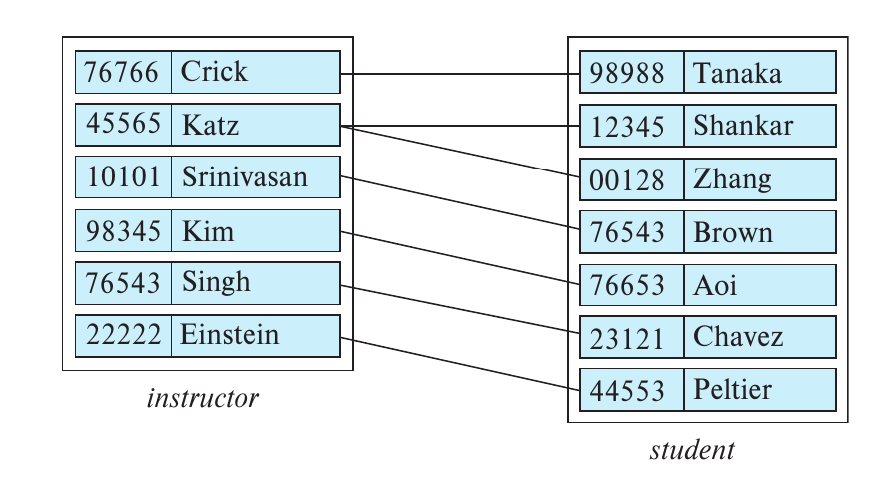
- 看这个图就很好理解了,单独的两个实体,如Crick和Tanaka之间的关系就是relationship,而实体集之间的映射关系就是relationship set
E-R图
-
entity set: 使用矩形来表示,分为两个部分,一部分是实体集的名称,一部分是实体集所有属性的名称
-
relationship set: 使用菱形来标识,通过线条连接到多个实体集
- relationship set的描述性属性用单矩形虚线连接
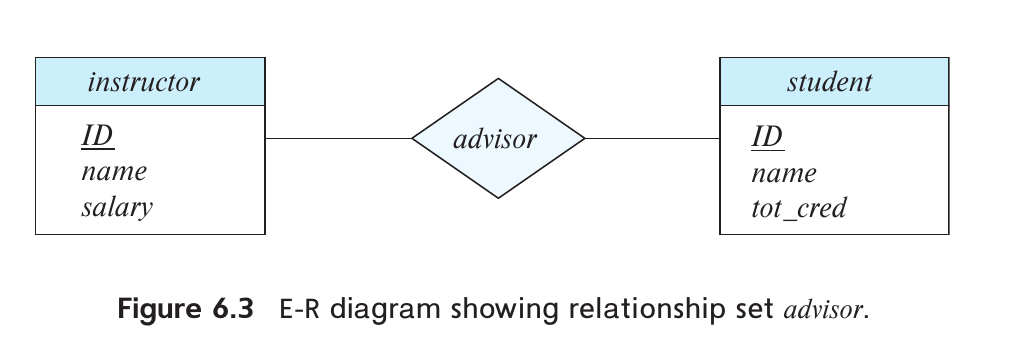
- relationship set的描述性属性用单矩形虚线连接
-
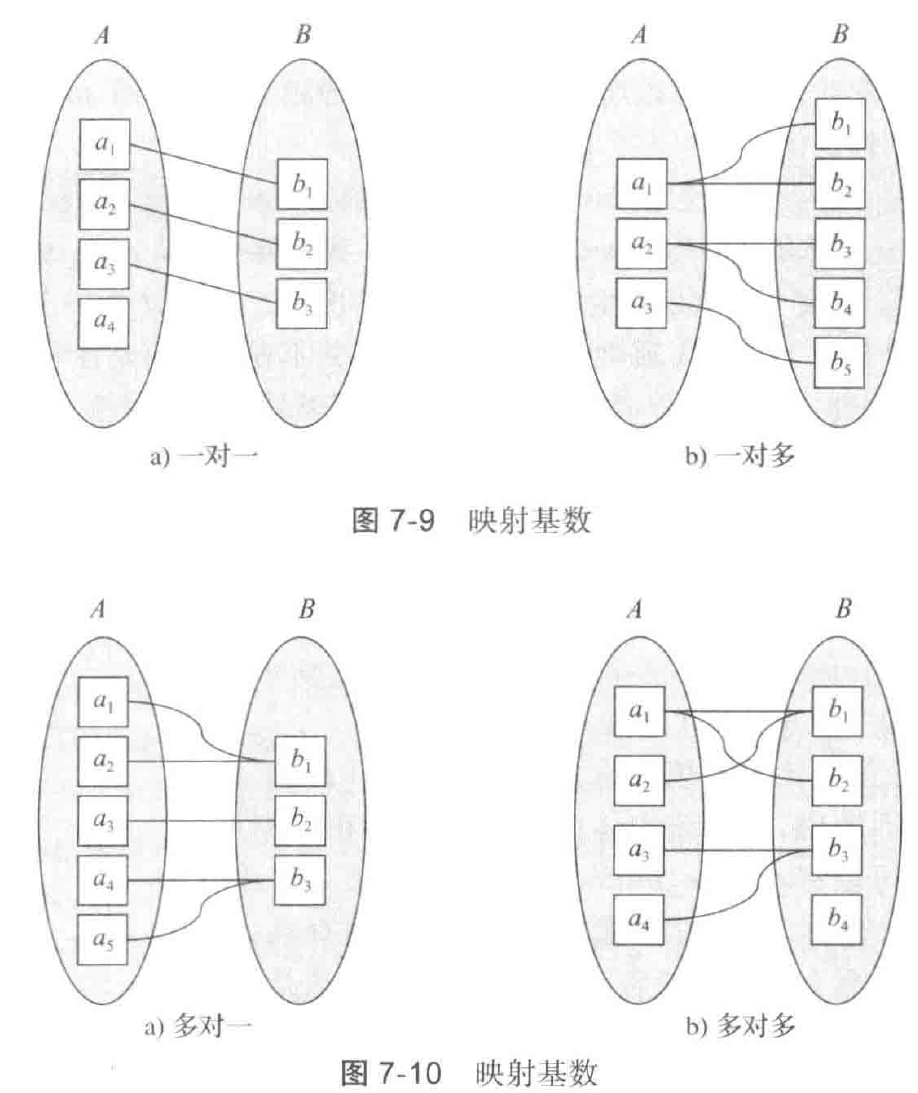
映射基数(mapping cardinality): 一个实体通过一个联系集关联的其他实体的数量,有以下四种:
- 一对一: 从联系集到两个实体集各画一个有向线段
- 一对多: "多方"使用无向线段连接,"一方"使用有向线段
- 多对一: 与一对多刚好相反
- 多对多: 两边都是无向线段
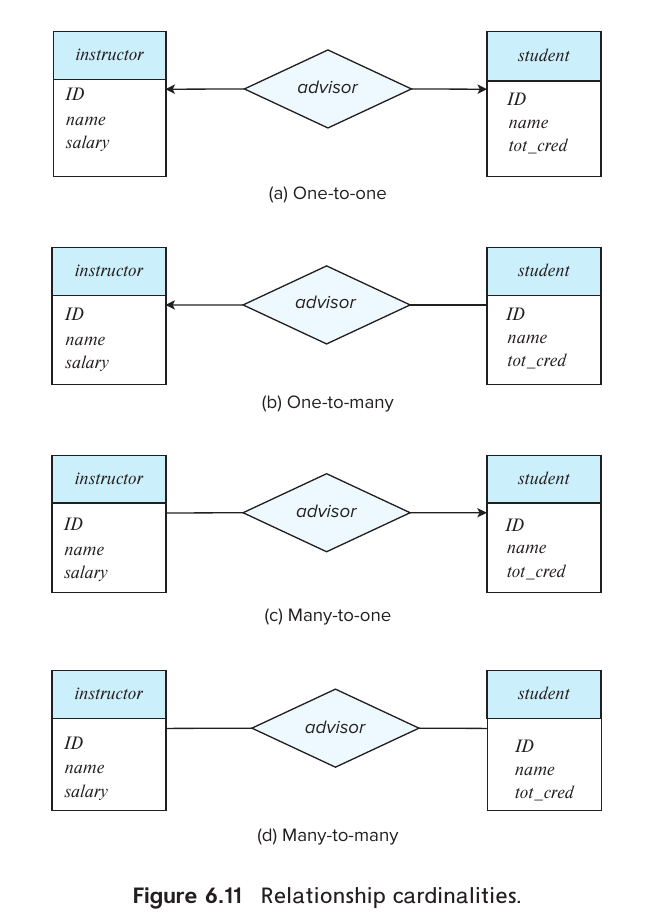
The participation of an entity set E in a relationship set R is said to be total if every entity in E must participate in at least one relationship in R. If it is possible that some entities in E do not participate in relationships in R, the participation of entity set E in
relationship R is said to be partial.
使用双线来表示一个实体集在联系集中全部参与.
strong entity and weak entity
强实体 (Strong Entity)
强实体是自足的,它不依赖于数据库中任何其他实体的存在。
- 物理特征:拥有一个独立的主键 (Primary Key)。这个主键不包含任何其他实体的属性。
- 物理隐喻:像一个拥有独立身份证的“自然人”。
- ER 图标识:矩形框。
- 例子:
Student(学生)。每个学生都有唯一的student_id,无论这个学生是否选课,他作为“学生”这个实体的物理记录在数据库中都是独立存在的。
弱实体 (Weak Entity)
弱实体是寄生的,它必须依赖于另一个实体(称为“标识实体”或“父实体”)才能获得物理意义上的唯一性。
- 物理特征:没有足够的属性来构成自己的主键。它的主键是物理借用来的,由“父实体的物理主键 + 自己的部分键(Discriminator/Partial Key)”共同组成。
- 物理隐喻:像“公寓里的房间”。没有公寓(父实体),“101室”这个编号物理上没有任何意义。
- ER 图标识:双边矩形框。
- 例子:
Section(开课班级)。单独看sec_id(如 1 班)无法确定是哪门课。它必须物理依赖于Course(课程),主键通常是(course_id, sec_id, semester, year)。
概化与特化
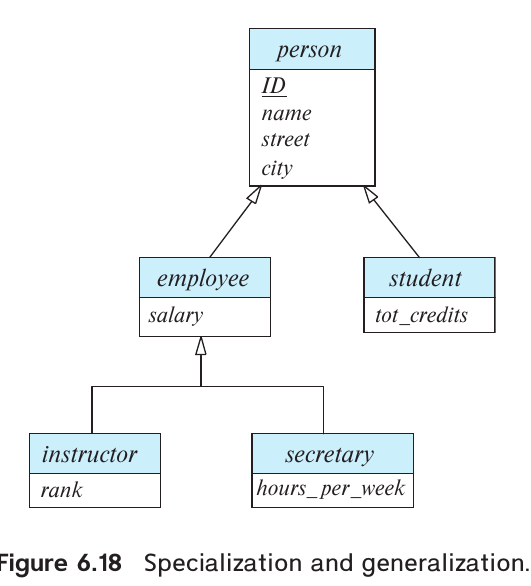
特化 (Specialization) —— 自上而下
- 物理逻辑:将一个高层级的实体集(父类)根据特定特征,物理拆分为多个低层级的子实体集(子类)。
- 触发场景:当你发现某些属性只适用于部分成员,而不适用于全体时。
- ER图表示: 由特化实体用空心箭头指向父类,如果一个实体可以属于多个特化实体集,则称为重叠特化(overlapping specialization),使用两个单独箭头;如果只能属于一个实体集,则称为不相交特化(disjoint specialization),使用一个箭头
- 物理示例:
员工 (Employee)实体。- 只有“厨师”拥有
厨师等级属性。 - 只有“司机”拥有
驾驶证号属性。 - 物理动作:从
员工集合中特化出厨师和司机子集。
- 只有“厨师”拥有
概化 (Generalization) —— 自下而上
- 物理逻辑:提取多个实体集中的共同属性,物理归纳为一个更高层级的通用实体集(父类)。
- 触发场景:为了消除数据冗余,并在物理层面提供统一的访问接口。
- 物理示例:存在
老虎、狮子、大象三个独立实体。- 它们物理上共有
年龄、体重、所属区域等属性。 - 物理动作:将它们概化为
动物 (Animal)实体。
- 它们物理上共有
汇总
The Unified Modeling Language (UML)
Relational Database Design(较难,待补充)
根据上一章的E-R图我们可以导出一组关系模式:

Complex Data Types
In this chapter, we discuss several non-atomic data types that are widely used,including semi-structured data, object-based data, textual data, and spatial data.
Semi-structured Data
Overview of Semi-structured Data Models
Flexible Schema
Some database systems allow each tuple to potentially have a different set of attributes;
such a representation is referred to as a wide column data representation.
The set of attributes is not fixed in such a representation; each tuple may have a different set of attributes, and new attributes may be added as needed.
A more restricted form of this representation is to have a fixed but very large number of attributes, with each tuple using only those attributes that it needs, leaving the rest with null values; such a representation is called a sparse column(稀疏表) representation.
Multivalued Data Types
Some representations allow attributes to store key-value maps, which store key-value pairs. A key-value map, often just called a map, is a set of (key, value) pairs, such that each key occurs in at most one element.
Nested Data Types
All of these data types represent a hierarchy of data types, and that structure leads to the use of the term nested data types.
- JSON和XML是该数据库类型的最重要的两个代表
JSON(JavaScript Object Notation)
The JavaScript Object Notation (JSON), is a textual representation of complex data types that is widely used to transmit data between applications and to store complex data.
JSON supports the primitive data types integer, real and string, as well as arrays,
and “objects,” which are a collection of (attribute name, value) pairs.
1 | { |
XML(Extensible Markup Language)
The XML data representation adds tags enclosed in angle brackets, <>, to mark up information in a textual representation.
Tags are used in pairs, withand delimiting the beginning and the end of the portion of the text to which the tag refers.
1 | <course> |
Object Orientation
Three approaches are used in practice for integrating object orientation with
database systems:
- Build an object-relational database system, which adds object-oriented features to a relational database system.
- Automatically convert data from the native object-oriented type system of the programming language to a relational representation for storage, and vice versa for retrieval. Data conversion is specified using an object-relational mapping.
- Build an object-oriented database system, that is, a database system that natively supports an object-oriented type system and allows direct access to data from an object-oriented programming language using the native type system of the language.
We provide a brief introduction to the first two approaches in this section.
Object-Relational Database Systems
User-Defined Types
1 | create type Person |
Type Inheritance
1 | create type Student under Person |
Table Inheritance
1 | -- PostgreSQL |
Object-Relational Mapping(ORM)
A fringe benefit of using an ORM is that any of a number of databases can be used
to store data, with exactly the same high-level code. ORMs hide minor SQL differences
between databases from the higher levels. Migration from one database to another is
thus relatively straightforward when using an ORM, whereas SQL differences can make
such migration significantly harder if an application uses SQL to communicate with
the database.
On the negative side, object-relational mapping systems can suffer from significant
performance inefficiencies for bulk database updates, as well as for complex queries
that are written directly in the imperative language. It is possible to update the database
directly, bypassing the object-relational mapping system, and to write complex queries
directly in SQL in cases where such inefficiencies are discovered.
Textual Data
Textual data consists of unstructured text. The term information retrieval generally refers to the querying of unstructured textual data.
Keyword Queries
A keyword query retrieves documents whose set of keywords contains all the keywords in the query.
搜索引擎是information retrieval systems的典型例子,根据关键词返回网页内容.
Relevance Ranking
The set of all documents that contain the keywords in a query may be very large; in
particular, there are billions of documents on the web, and most keyword queries on
a web search engine find hundreds of thousands of documents containing some or all of the keywords.
Information-retrieval systems therefore estimate relevance of documents to a query and return only highly ranked documents as answers.
Ranking Using TF-IDF
- term: refers to a keyword occurring in a document, or given as part of a query.
- TF: term frequency
One way of measuring TF(d, t), the relevance of a term t to a document d, is:
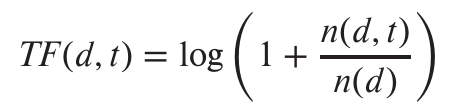
where n(d) denotes the number of term occurrences in the document and n(d, t) denotes the number of occurrences of term t in the document d.
However, not all terms used as keywords are equal. Suppose a query uses two terms, one
of which occurs frequently, such as “database”, and another that is less frequent, such
as “Silberschatz”. A document containing “Silberschatz” but not “database” should be
ranked higher than a document containing the term “database” but not “Silberschatz”.
To fix this problem, weights are assigned to terms using the inverse document fre-
quency (IDF), defined as:
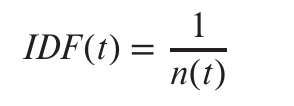
where n(t) denotes the number of documents (among those indexed by the system) that contain the term t. The relevance of a document d to a set of terms Q is then defined as:
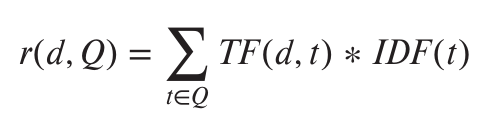
Almost all text documents (in English) contain words such as “and,” “or,” “a,” and
so on, and hence these words are useless for querying purposes since their inverse doc-
ument frequency is extremely low. Information-retrieval systems define a set of words,
called stop words, containing 100 or so of the most common words, and ignore these
words when indexing a document. Such words are not used as keywords, and they are
discarded if present in the keywords supplied by the user.
- 这就是为什么输入
python和爬虫得到的结果与python 爬虫相差无几的原因
Ranking Using Hyperlinks
Hyperlinks between documents can be used to decide on the overall importance of
a document, independent of the keyword query; for example, documents linked from
many other documents are considered more important.
Pagerank是该排序方法的著名代表之一
Spatial Data
Two types of spatial data are particularly important:
- Geographic data: such as road maps, land-usage maps, topographic elevation maps, political maps showing boundaries.
- Geometric data: include spatial information about how objects— such as buildings, cars, or aircraft— are constructed
游戏建模,谷歌地图都属于空间数据这一范畴
补充
Outline Of The Course
- Chapter 1: Introduction
- Chapter 2: Introduction to Relational Model
- Chapter 3: Introduction to SQL
- Chapter 4: Intermediate SQL
- Chapter 5: Advanced SQL (只要求前三节)
- Chapter 6: Entity-Relationship Model
- Chapter 7: Relational Database Design
- Chapter 8: Complex Data Types
- Chapter 9: Application Design
- Chapter 10: Big Data
- Chapter 11: Data Analytics
- Chapter 12: Physical Storage Systems (Sections 12.5 (RAID) omitted)
- Chapter 13: Storage and File Structure
- Chapter 14: Indexing and Hashing
- Chapter 15: Query Processing (Section 15.1, 15.2)
- Chapter 17: Transactions
- 斜体的为需要熟练的部分,黑体的为非常重要的部分
吐槽
教材详细过头了,而ppt基本是原封不动的搬运了整本书1300多页的内容,一个ppt最少五六十张,而总共有20多个ppt.
要说他敬业呢,ppt上的内容破碎无比,速览一遍发现不如看书完整,要说他不敬业呢,好歹有这么大的工作量.
- (3/26)这本书真的是又臭又长…
- (3/28)我服了原来这个ppt是官网上的,而我们老师实际啥都没干…
本教材核心: 大学数据库
- keys used
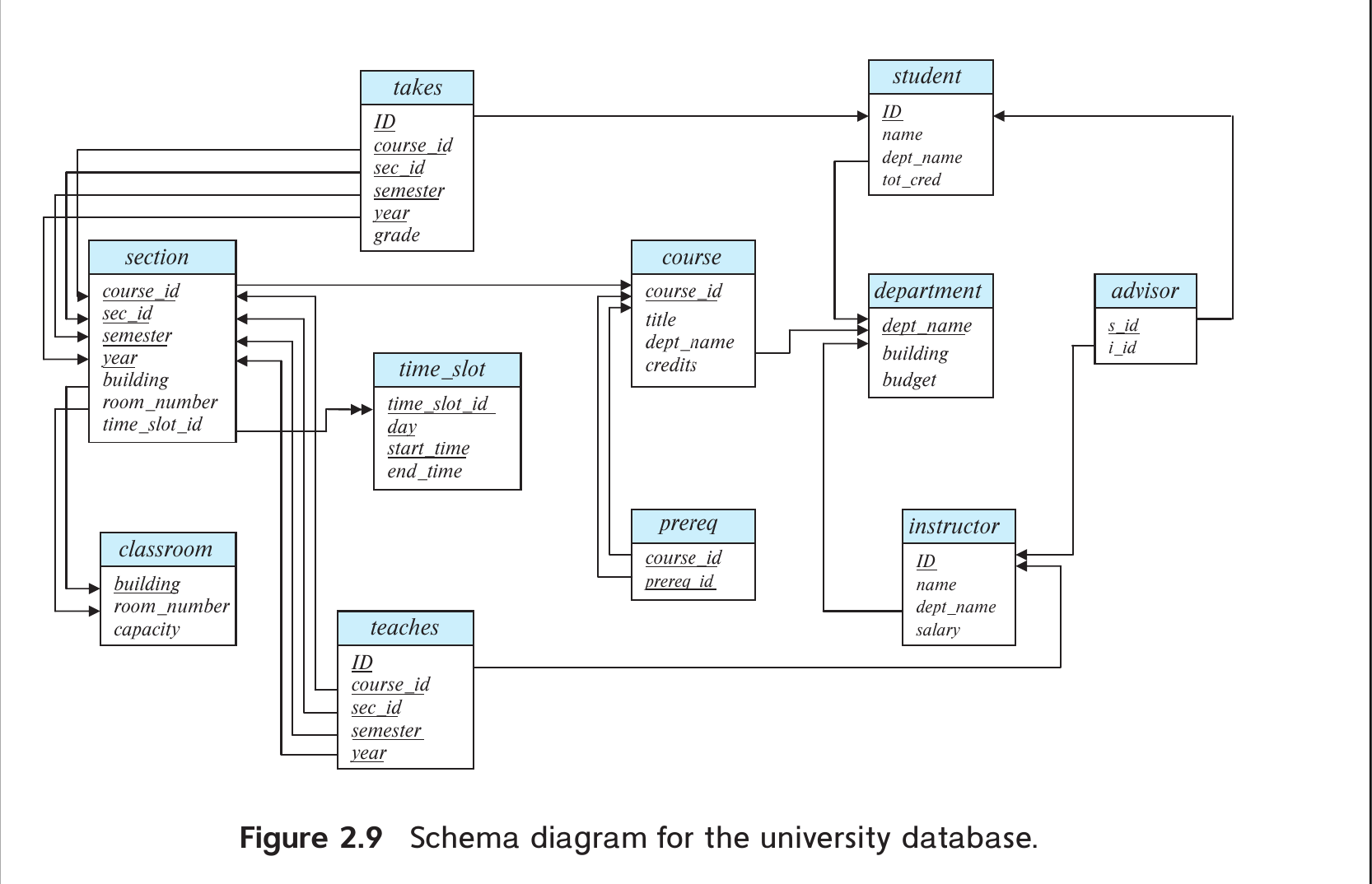
- schema diagram
关系表解析
1 | create table classroom |
- departname: 部门的办公地点和预算
- course: 培养计划中的课程
- instructor: 教师的信息
- section: 课表中的真实课程
- section是course在某一学期的映射
- teaches: 教师教授的课程信息
- student: 学生的信息
- takes: 学生所选的真实课表





